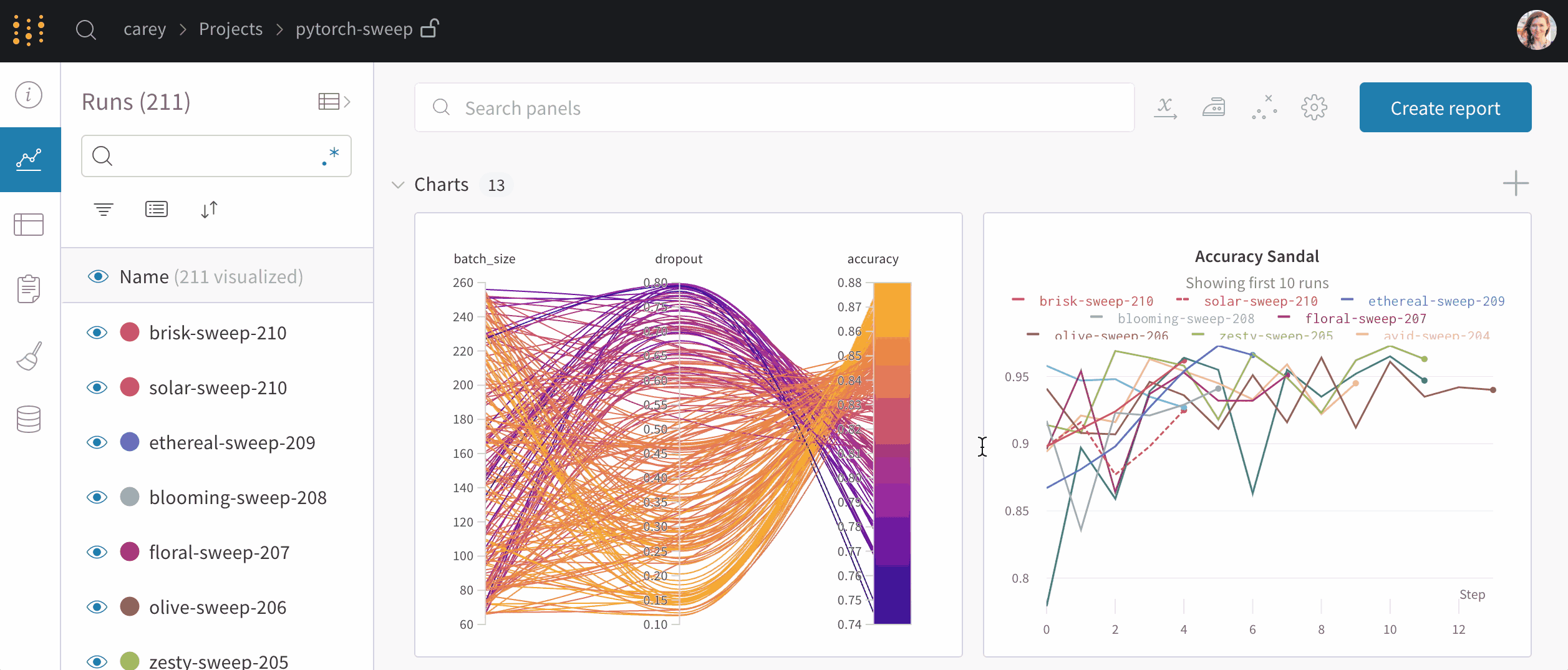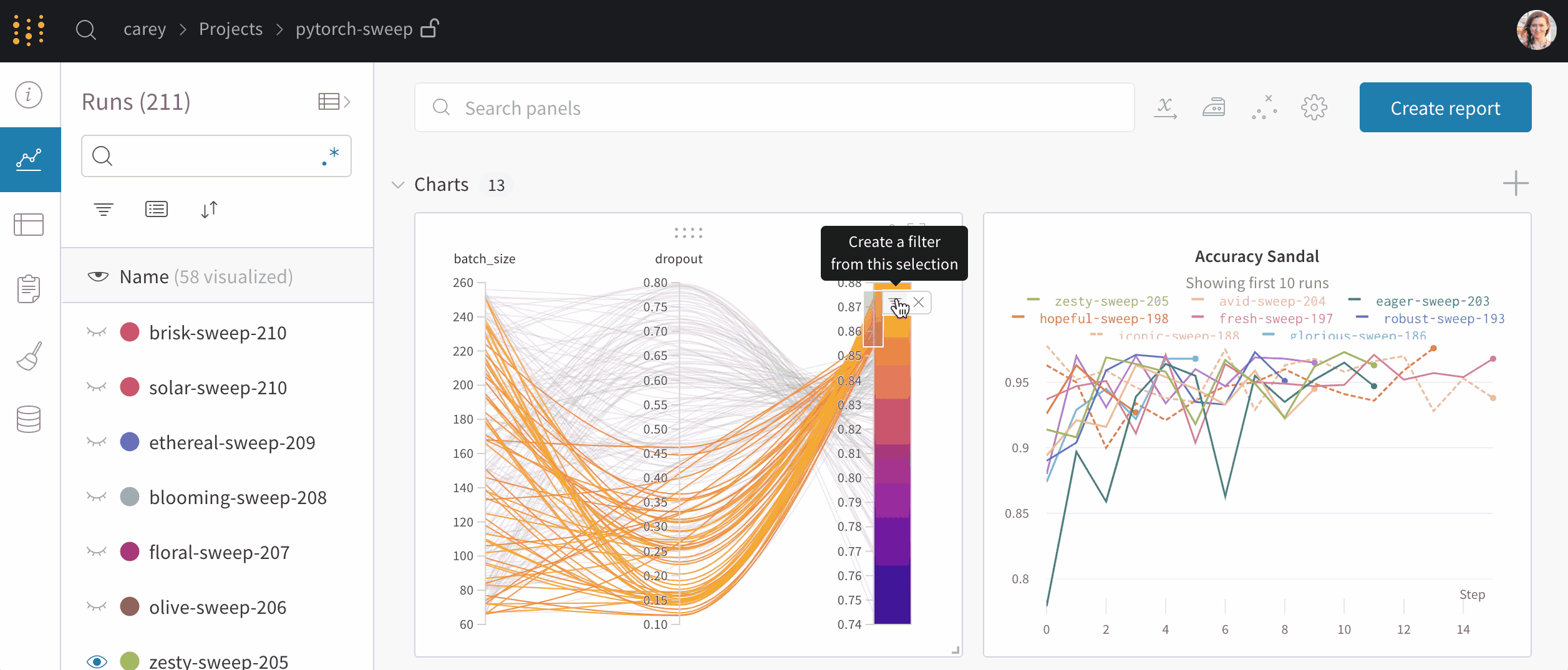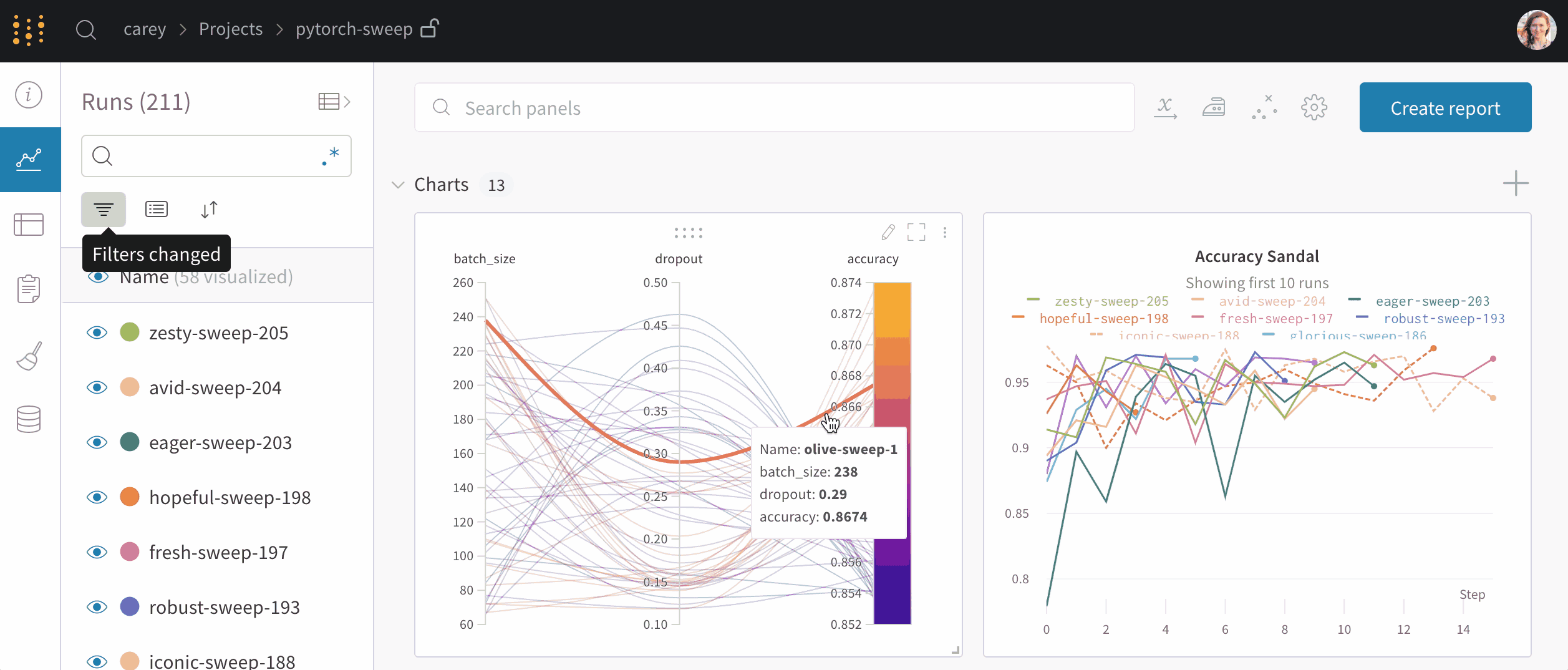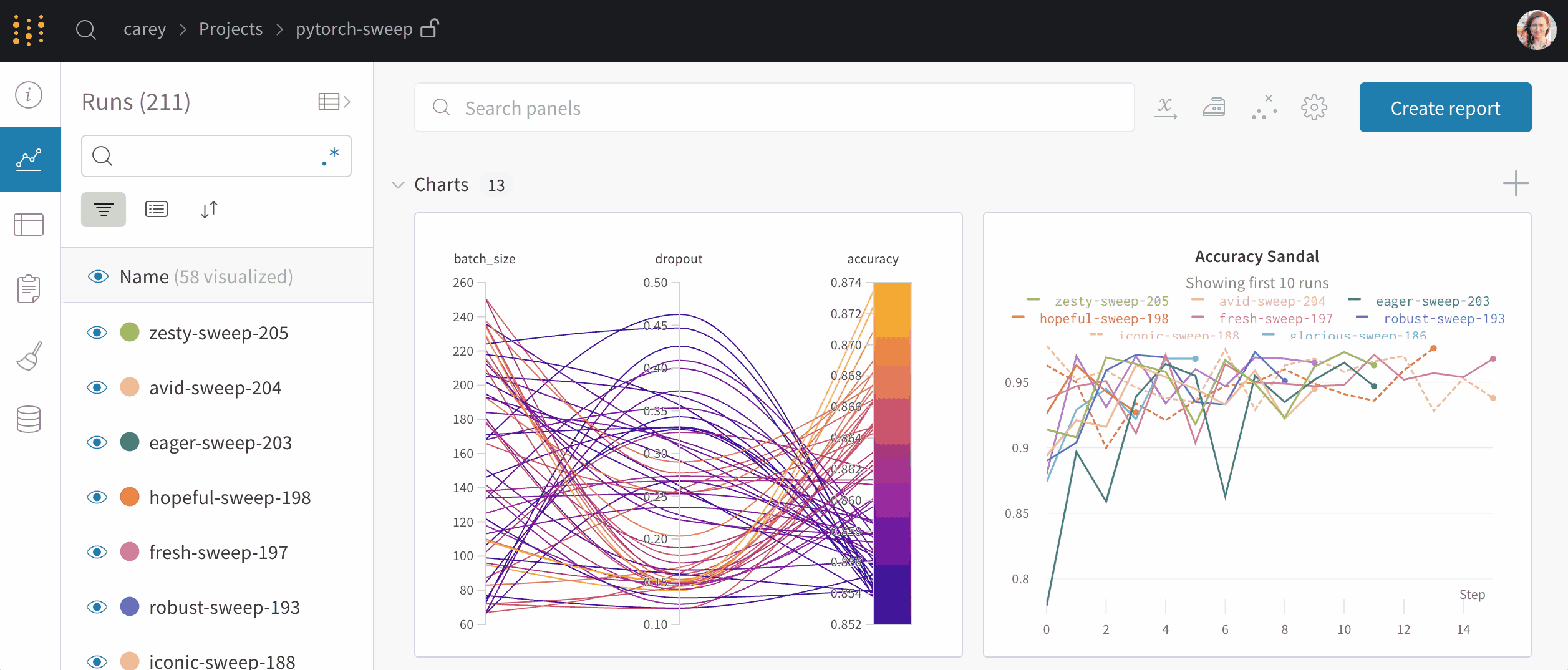
GNAS-QN2U8B は、Intel® Celeron® N5095/5105 クアッドコアプロセッサ(最大バースト 2.9 GHz)を搭載し、省スペース筐体により奥行きの浅いラックや配線が多い環境にも容易に設置できます。さらに、拡張可能なストレージ構成と高性能アプリケーション群により、従来モデルと比較して処理性能・拡張性・運用効率が大幅に向上しています。
クアッドコアCPUとハードウェア暗号化を備えた高効率NASアーキテクチャ
GNAS-QN2U8Bは、Intel® Celeron® N5095 クアッドコアプロセッサ(最大バースト 2.9 GHz)を搭載し、標準 4 GB の DDR4 メモリは最大 16 GB まで拡張可能です。また、Intel® AES-NI 暗号化エンジンを備えており、AES-256 ビット暗号化のハードウェアアクセラレーションにより、暗号化処理を高速化しつつシステム全体のパフォーマンスを最適化します。これにより、NAS に保存されるビジネスデータを高い安全性で保護できます。
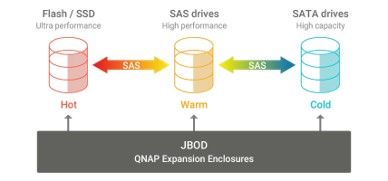
Qtier™ による自動階層化とSSDキャッシュで高速I/Oを実現
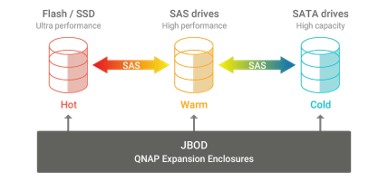
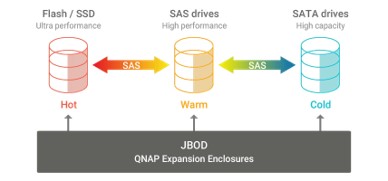
GNAS-QN2U8Bは、仮想化環境などランダムIOPSが求められるワークロードを高速化するSSDキャッシュに対応しています。さらに Qtier™ テクノロジー により、高速なSSD層と大容量SATA層の間でデータを自動的に最適配置し、ストレージ性能と利用効率を継続的に向上させます。Qtier™ 2.0 では、SSDの未使用領域をキャッシュとして活用することでリアルタイムのバーストI/Oに対応可能となり、SSD階層化ストレージの性能を最大限引き出します。これにより、GNAS-QN2U8Bはランダムアクセス負荷の高い業務アプリケーションでも高いパフォーマンスを発揮します。
QTS 5 ベースの高効率管理オペレーティング環境
GNAS-QN2U8Bは標準で QTS 5 オペレーティングシステムを搭載しています。最新カーネルによるパフォーマンス向上と、操作性を高めたユーザーインターフェース、さらに強化されたセキュリティ機能により、管理性・安全性・快適性を備えた最新の運用環境を提供します。
高信頼性を支えるアクセス制御と統合セキュリティ
GNAS-QN2U8B は高度なアクセス制御と多層セキュリティ機能を搭載しています。IP アクセス制限、2 要素認証(2FA)、HTTPS/TLS 通信に対応し、不正アクセスリスクを低減します。また、統合セキュリティアプリにより、マルウェアやブルートフォース攻撃などの脅威をリアルタイムで監視・防御し、NAS 全体のセキュリティを強化します。
GNASⅢ-RM2U8Bには、Intel® Celeron® N5095/5105 クアッドコアプロセッサ (最大バースト2.9 GHz)が搭載されています。奥行きの浅い省スペースなデザインなので小型のテレビ台やケーブルの多い場所にも簡単に設置できます。拡張可能なストレージ容量および高性能のアプリを備えた GNASⅢ-RM2U8Bは、従来の製品と比較して、圧倒的に優れています。
クアッドコアプロセッサ、最大バースト2.9 GHz、最大8 GBまで増設可能なメモリ
GNASⅢ-RM2U8Bは、Intel® Celeron® N5095クアッドコアプロセッサ(最大バースト2.9 GHz)搭載で、さらに16 GBまで拡張可能な4 GB DDR4メモリを備えています。Intel® AES-NI暗号化エンジン搭載のTS-x64eUは、AES-256ビット暗号化アクセラレーションによる比類ない暗号化性能を備えており、システム性能を向上させつつ、NASに保存された重要なビジネスデータを安全に守ります。
SSDキャッシュおよび自動階層化によるストレージ効率の最適化
GNASⅢ-RM2U8Bは、仮想化などのランダムIOPSを要求するアプリケーションのワークフローを向上するSSDキャッシュをサポートしています。Qtier™テクノロジーにより、高性能のSSDおよび大容量SATAドライブにわたるストレージ利用を継続的に最適化する自動階層化で、GNASⅢ-RM2U8Bの性能が向上します。Qtier™ 2.0は、キャッシュのような予備のスペースでSSD階層化ストレージを強化して、リアルタイムにバーストI/Oを処理し、SSDのメリットを最大限に引き出すことのできるIOへのケアを特長としています。
QTS 5、高速でスムーズかつ使いやすい!
GNASⅢ-RM2U8Bは標準でQTS 5オペレーティングシステムが付属し、アップデートされたシステムカーネル、最適化されたユーザーインターフェース、また先進のセキュリティ機能を備えており、次世代の使用体験を提供します。
包括的なセキュリティおよび権限設定
GNASⅢ-RM2U8Bには、柔軟な権限設定およびセキュリティ機能が搭載されています。IPブロック、二段階認証、HTTPS接続に加え、マルウェアやハッカーなどの脅威からNASを最適に保護するためのアプリがあります。
GNASⅢ-RM2U8Bには、Intel® Celeron® N5095/5105 クアッドコアプロセッサ (最大バースト2.9 GHz)が搭載されています。奥行きの浅い省スペースなデザインなので小型のテレビ台やケーブルの多い場所にも簡単に設置できます。拡張可能なストレージ容量および高性能のアプリを備えた GNASⅢ-RM2U8Bは、従来の製品と比較して、圧倒的に優れています。
クアッドコアプロセッサ、最大バースト2.9 GHz、最大8 GBまで増設可能なメモリ
GNASⅢ-RM2U8Bは、Intel® Celeron® N5095クアッドコアプロセッサ(最大バースト2.9 GHz)搭載で、さらに16 GBまで拡張可能な4 GB DDR4メモリを備えています。Intel® AES-NI暗号化エンジン搭載のTS-x64eUは、AES-256ビット暗号化アクセラレーションによる比類ない暗号化性能を備えており、システム性能を向上させつつ、NASに保存された重要なビジネスデータを安全に守ります。
SSDキャッシュおよび自動階層化によるストレージ効率の最適化
GNASⅢ-RM2U8Bは、仮想化などのランダムIOPSを要求するアプリケーションのワークフローを向上するSSDキャッシュをサポートしています。Qtier™テクノロジーにより、高性能のSSDおよび大容量SATAドライブにわたるストレージ利用を継続的に最適化する自動階層化で、GNASⅢ-RM2U8Bの性能が向上します。Qtier™ 2.0は、キャッシュのような予備のスペースでSSD階層化ストレージを強化して、リアルタイムにバーストI/Oを処理し、SSDのメリットを最大限に引き出すことのできるIOへのケアを特長としています。
QTS 5、高速でスムーズかつ使いやすい!
GNASⅢ-RM2U8Bは標準でQTS 5オペレーティングシステムが付属し、アップデートされたシステムカーネル、最適化されたユーザーインターフェース、また先進のセキュリティ機能を備えており、次世代の使用体験を提供します。
包括的なセキュリティおよび権限設定
GNASⅢ-RM2U8Bには、柔軟な権限設定およびセキュリティ機能が搭載されています。IPブロック、二段階認証、HTTPS接続に加え、マルウェアやハッカーなどの脅威からNASを最適に保護するためのアプリがあります。
GNASⅢ-RM2U8Bには、Intel® Celeron® N5095/5105 クアッドコアプロセッサ (最大バースト2.9 GHz)が搭載されています。奥行きの浅い省スペースなデザインなので小型のテレビ台やケーブルの多い場所にも簡単に設置できます。拡張可能なストレージ容量および高性能のアプリを備えた GNASⅢ-RM2U8Bは、従来の製品と比較して、圧倒的に優れています。
クアッドコアプロセッサ、最大バースト2.9 GHz、最大8 GBまで増設可能なメモリ
GNASⅢ-RM2U8Bは、Intel® Celeron® N5095クアッドコアプロセッサ(最大バースト2.9 GHz)搭載で、さらに16 GBまで拡張可能な4 GB DDR4メモリを備えています。Intel® AES-NI暗号化エンジン搭載のTS-x64eUは、AES-256ビット暗号化アクセラレーションによる比類ない暗号化性能を備えており、システム性能を向上させつつ、NASに保存された重要なビジネスデータを安全に守ります。
SSDキャッシュおよび自動階層化によるストレージ効率の最適化
GNASⅢ-RM2U8Bは、仮想化などのランダムIOPSを要求するアプリケーションのワークフローを向上するSSDキャッシュをサポートしています。Qtier™テクノロジーにより、高性能のSSDおよび大容量SATAドライブにわたるストレージ利用を継続的に最適化する自動階層化で、GNASⅢ-RM2U8Bの性能が向上します。Qtier™ 2.0は、キャッシュのような予備のスペースでSSD階層化ストレージを強化して、リアルタイムにバーストI/Oを処理し、SSDのメリットを最大限に引き出すことのできるIOへのケアを特長としています。
QTS 5、高速でスムーズかつ使いやすい!
GNASⅢ-RM2U8Bは標準でQTS 5オペレーティングシステムが付属し、アップデートされたシステムカーネル、最適化されたユーザーインターフェース、また先進のセキュリティ機能を備えており、次世代の使用体験を提供します。
包括的なセキュリティおよび権限設定
GNASⅢ-RM2U8Bには、柔軟な権限設定およびセキュリティ機能が搭載されています。IPブロック、二段階認証、HTTPS接続に加え、マルウェアやハッカーなどの脅威からNASを最適に保護するためのアプリがあります。
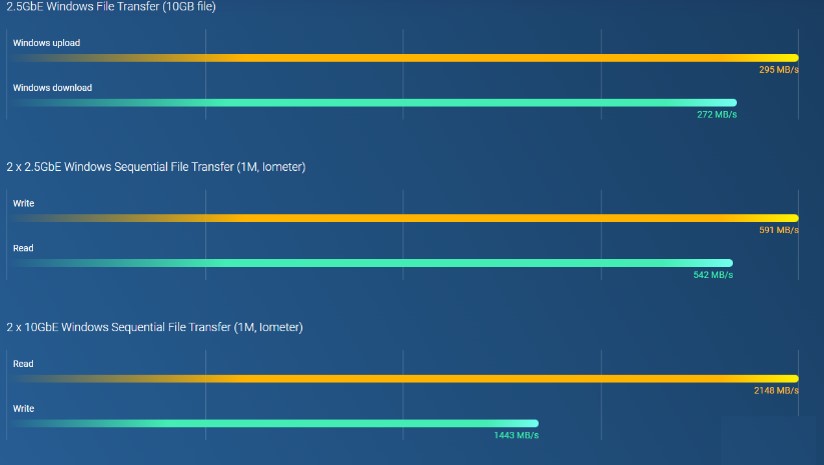
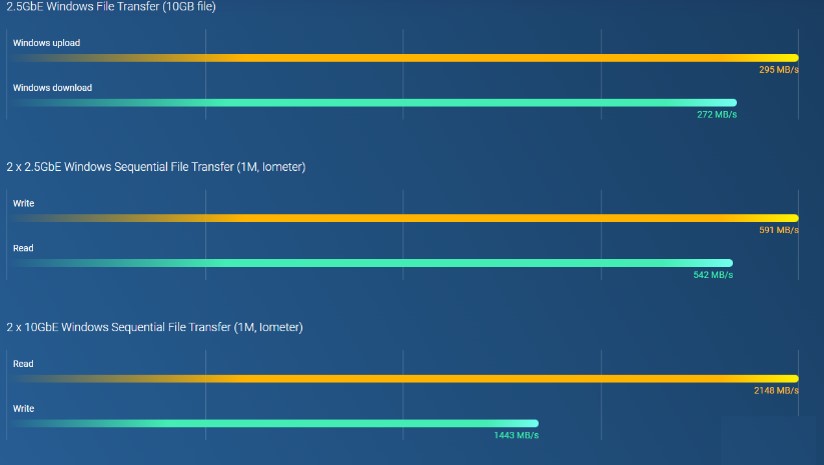
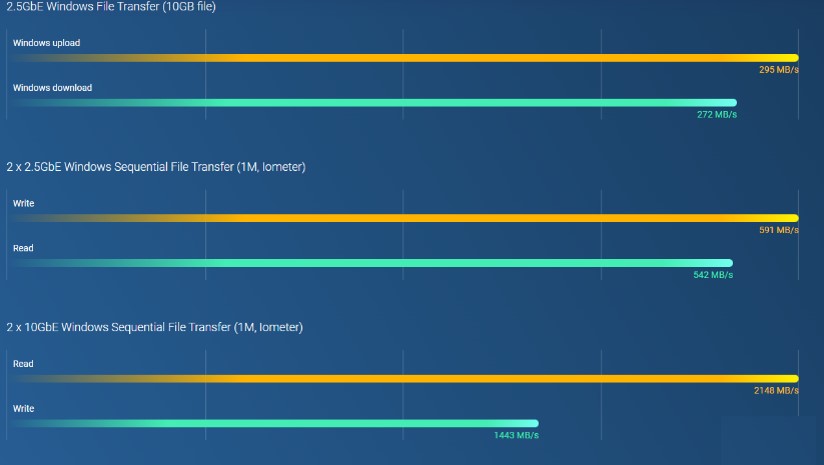
Intel® Celeron® N5105/N5095、クアッドコアプロセッサ (最大バースト 2.9GHz)搭載、2つの2.5GbE RJ45ポートおよびポートトランキング対応で、最大5Gbpsの結合帯域幅を実現します。M.2 PCIe Gen3およびPCIe Gen3スロット装備、NAS機能の拡張性を提供し、M.2 SSDキャッシュ用のQM2カード、AI画像認識用のEdge TPU、各種10GbE/5GbEネットワークカードのインストールが可能です。また4 GB RAM装備で軽負荷VMおよびコンテナが稼働可能で、マルチクラウドバックアップ、クラウドストレージゲートウェイ、4K HDMI出力、リアルタイムトランスコーディングに対応し、拡張可能なストレージ容量や機能の豊富なアプリによって高いコスト効率と信頼性を備えた2.5GbE NASとして活躍します。
クアッドコアの高性能および最大16GBのRAM
Intel Celeron N5105 / N5095 クアッドコアプロセッサ搭載で、最大16 GB DDR4 メモリ、2つの2.5GbEポートおよびSATA 6 Gb/sドライブに対応します。また、搭載のIntel® AES-NI暗号化エンジンがシステムパフォーマンスへの影響なく機密データの保護を支援します。
2.5GbEで、大容量ファイル転送とビデオ編集を効率化
2つの2.5GbE RJ45 (2.5G/1G/100M) LANポートを備えており、既存のCAT5eケーブルを使ってネットワーク速度を1 ギガビットから2.5 ギガビットへアップグレードできます。また、2つの2.5GbEポートはポートトランキング対応で最大5 Gbpsの転送速度を実現し、大型ファイル転送、高速バックアップ・復元、マルチメディア転送・編集など、帯域幅重視のアプリケーションにおけるビジネス効率を向上させます。
TPUおよびPCIe拡張による、AIベース画像認識およびキャッシュのアクセラレーション
2つのM.2 PCIe Gen 3スロットを装備しており、SSDキャッシュまたはSSDストレージプールによるパフォーマンス向上、またはEdge TPUによるAI画像認識を実現します。
最大5年までのハードウェア保証延長
本製品には、別途費用なしで3年保証が付いています。必要に応じて、最大5年までの延長保証を購入することができます。
GNAS-DS4Bは10GbEネットワーク、RAID(5,6,10,JBOD等)に対応した信頼性、安全性、拡張性が高い4ベイ高性能 NAS のエントリーモデルです。
高い機密性とパフォーマンス
最新の14 nm Intel® Celeron® J3455クアッドコア1.5Ghzプロセッサ (バースト最大2.3Ghz)、を搭載したGNAS-DS8BBは最大 225 MB/s の読み書き速度でタスクをスムーズかつ素早く実行します。Intel® AES-NIハードウェアアクセラレート暗号化エンジンを搭載し、NASボリューム全体と共有フォルダに対して、AES 256ビット暗号化による最大225MB/秒の転送速度を実現します。 また、システム性能を向上させ、貴重なデータを安全に確実に保管します。
シームレスな容量拡張
GNAS-DS4Bは拡張エンクロージャーを追加することにより容易に容量の拡張が可能です。ビジネスにおいて増大するビッグデータや,大型ファイルのアーカイブの必要性に応える高性能でありながらも経済的なストレージソリューションです。
高信頼性ストレージWD Redシリーズ搭載
GNAS-DS8Bでは搭載ハードディスクにWestern digital社のREDシリーズを採用。 複数台ストレージの周囲温度が高くなるような厳しい環境下でも、低温で低振動で動作するよう開発されており、厳しい24時間365日常時稼働環境で優れた適合性を発揮します。
GNAS-DS4Bは10GbEネットワーク、RAID(5,6,10,JBOD等)に対応した信頼性、安全性、拡張性が高い4ベイ高性能 NAS のエントリーモデルです。
高い機密性とパフォーマンス
最新の14 nm Intel® Celeron® J3455クアッドコア1.5Ghzプロセッサ (バースト最大2.3Ghz)、を搭載したGNAS-DS8BBは最大 225 MB/s の読み書き速度でタスクをスムーズかつ素早く実行します。Intel® AES-NIハードウェアアクセラレート暗号化エンジンを搭載し、NASボリューム全体と共有フォルダに対して、AES 256ビット暗号化による最大225MB/秒の転送速度を実現します。 また、システム性能を向上させ、貴重なデータを安全に確実に保管します。
シームレスな容量拡張
GNAS-DS4Bは拡張エンクロージャーを追加することにより容易に容量の拡張が可能です。ビジネスにおいて増大するビッグデータや,大型ファイルのアーカイブの必要性に応える高性能でありながらも経済的なストレージソリューションです。
高信頼性ストレージWD Redシリーズ搭載
GNAS-DS8Bでは搭載ハードディスクにWestern digital社のREDシリーズを採用。 複数台ストレージの周囲温度が高くなるような厳しい環境下でも、低温で低振動で動作するよう開発されており、厳しい24時間365日常時稼働環境で優れた適合性を発揮します。
AMD Ryzen™ V1000シリーズ V1500Bクアッドコアプロセッサ搭載で、最大クアッドコア/ 8スレッド、最大2.2 GHzのTurbo Core対応、優れたシステム性能を実現します。2つの2.5GbE RJ45ポートおよび2つのPCIe Gen3スロットを装備、5GbE/10GbEネットワークをフレキシブルに展開できます。QtierテクノロジおよびSSDキャッシング対応の2つのM.2 NVMe SSDスロットにより、安定したストレージ最適化が可能です。
高性能AMD Ryzen™プロセッサ
AMD Ryzen™ V1000 シリーズ V1500 クアッドコア2.2 GHz プロセッサ搭載、最大64GB RAM (ECCメモリ対応*)装着で、最大10 Gb/sの速度に対応するUSB 3.2 Gen 2ポートを装備します。また、1つのUSB Type-Cポートを装備、より多くのデバイスに対応することで、大容量メディアファイルを複数のデバイス間で転送でき、より効率的なワークフローが実現します。
お財布に優しい2.5GbEスイッチにより、ネットワークを変革します
ネットワークのアップグレードに莫大な費用をかける必要はありません。2.5GbE接続は標準の1GbEと比べてすぐに顕著な改善がみられます。マルチGigabit NBASE-T™対応の2.5GbEスイッチを提供、これにより既存のCAT5eケーブルを使って複数のコンピューターおよびNASが接続でき、予算を超えることなく、高速でセキュアかつスケーラブルなネットワーク環境を組織に導入することを支援します。
GPUアクセラレーションコンピューティングのためにグラフィックカードを取り付ける
グラフィックスカードは、グラフィカルな計算や変換のために最適化されていますが、他のハードウェアよりも多くの電力を必要としています。本製品は、NVIDIA® GeForce® GTX1650グラフィックスカードを含む、電源ケーブルを必要としないハイプロファイルグラフィックスカードをサポートするPCIeスロットを備えており、ビデオ編集、4K UHDトランスコーディング、QTSでの画像処理、GPUパススルーを介した仮想マシンのパフォーマンスなどのアプリケーション性能を向上させることができます。
最大5年までのハードウェア保証延長
本製品には、別途費用なしで3年保証が付いています。必要に応じて、最大5年までの延長保証を購入することができます。
AMD Ryzen™ V1000シリーズ V1500Bクアッドコアプロセッサ搭載で、最大クアッドコア/ 8スレッド、最大2.2 GHzのTurbo Core対応、優れたシステム性能を実現します。2つの2.5GbE RJ45ポートおよび2つのPCIe Gen3スロットを装備、5GbE/10GbEネットワークをフレキシブルに展開できます。QtierテクノロジおよびSSDキャッシング対応の2つのM.2 NVMe SSDスロットにより、安定したストレージ最適化が可能です。
高性能AMD Ryzen™プロセッサ
AMD Ryzen™ V1000 シリーズ V1500 クアッドコア2.2 GHz プロセッサ搭載、最大64GB RAM (ECCメモリ対応*)装着で、最大10 Gb/sの速度に対応するUSB 3.2 Gen 2ポートを装備します。また、1つのUSB Type-Cポートを装備、より多くのデバイスに対応することで、大容量メディアファイルを複数のデバイス間で転送でき、より効率的なワークフローが実現します。
お財布に優しい2.5GbEスイッチにより、ネットワークを変革します
ネットワークのアップグレードに莫大な費用をかける必要はありません。2.5GbE接続は標準の1GbEと比べてすぐに顕著な改善がみられます。マルチGigabit NBASE-T™対応の2.5GbEスイッチを提供、これにより既存のCAT5eケーブルを使って複数のコンピューターおよびNASが接続でき、予算を超えることなく、高速でセキュアかつスケーラブルなネットワーク環境を組織に導入することを支援します。
GPUアクセラレーションコンピューティングのためにグラフィックカードを取り付ける
グラフィックスカードは、グラフィカルな計算や変換のために最適化されていますが、他のハードウェアよりも多くの電力を必要としています。本製品は、NVIDIA® GeForce® GTX1650グラフィックスカードを含む、電源ケーブルを必要としないハイプロファイルグラフィックスカードをサポートするPCIeスロットを備えており、ビデオ編集、4K UHDトランスコーディング、QTSでの画像処理、GPUパススルーを介した仮想マシンのパフォーマンスなどのアプリケーション性能を向上させることができます。
最大5年までのハードウェア保証延長
本製品には、別途費用なしで3年保証が付いています。必要に応じて、最大5年までの延長保証を購入することができます。
AMD Ryzen™ V1000シリーズ V1500Bクアッドコアプロセッサ搭載で、最大クアッドコア/ 8スレッド、最大2.2 GHzのTurbo Core対応、優れたシステム性能を実現します。2つの2.5GbE RJ45ポートおよび2つのPCIe Gen3スロットを装備、5GbE/10GbEネットワークをフレキシブルに展開できます。QtierテクノロジおよびSSDキャッシング対応の2つのM.2 NVMe SSDスロットにより、安定したストレージ最適化が可能です。
高性能AMD Ryzen™プロセッサ
AMD Ryzen™ V1000 シリーズ V1500 クアッドコア2.2 GHz プロセッサ搭載、最大64GB RAM (ECCメモリ対応*)装着で、最大10 Gb/sの速度に対応するUSB 3.2 Gen 2ポートを装備します。また、1つのUSB Type-Cポートを装備、より多くのデバイスに対応することで、大容量メディアファイルを複数のデバイス間で転送でき、より効率的なワークフローが実現します。
既存CAT5eをそのまま活用し、コストを抑えた高速・安全なネットワーク環境を実現
ネットワークのアップグレードに莫大な費用をかける必要はありません。2.5GbE接続は標準の1GbEと比べてすぐに顕著な改善がみられます。マルチGigabit NBASE-T™対応の2.5GbEスイッチを提供、これにより既存のCAT5eケーブルを使って複数のコンピューターおよびNASが接続でき、予算を超えることなく、高速でセキュアかつスケーラブルなネットワーク環境を組織に導入することを支援します。
GTX1650相当の無給電GPU拡張に対応。4KトランスコードやVMパススルー性能の強化が可能に
グラフィックスカードは、グラフィカルな計算や変換のために最適化されていますが、他のハードウェアよりも多くの電力を必要としています。本製品は、NVIDIA® GeForce® GTX1650グラフィックスカードを含む、電源ケーブルを必要としないハイプロファイルグラフィックスカードをサポートするPCIeスロットを備えており、ビデオ編集、4K UHDトランスコーディング、QTSでの画像処理、GPUパススルーを介した仮想マシンのパフォーマンスなどのアプリケーション性能を向上させることができます。
最大5年までのハードウェア保証延長
本製品には、別途費用なしで3年保証が付いています。必要に応じて、最大5年までの延長保証を購入することができます。
AMD Ryzen™ V1000シリーズ V1500Bクアッドコアプロセッサ搭載で、最大クアッドコア/ 8スレッド、最大2.2 GHzのTurbo Core対応、優れたシステム性能を実現します。2つの2.5GbE RJ45ポートおよび2つのPCIe Gen3スロットを装備、5GbE/10GbEネットワークをフレキシブルに展開できます。QtierテクノロジおよびSSDキャッシング対応の2つのM.2 NVMe SSDスロットにより、安定したストレージ最適化が可能です。
高性能AMD Ryzen™プロセッサ
AMD Ryzen™ V1000 シリーズ V1500 クアッドコア2.2 GHz プロセッサ搭載、最大64GB RAM (ECCメモリ対応*)装着で、最大10 Gb/sの速度に対応するUSB 3.2 Gen 2ポートを装備します。また、1つのUSB Type-Cポートを装備、より多くのデバイスに対応することで、大容量メディアファイルを複数のデバイス間で転送でき、より効率的なワークフローが実現します。
お財布に優しい2.5GbEスイッチにより、ネットワークを変革します
ネットワークのアップグレードに莫大な費用をかける必要はありません。2.5GbE接続は標準の1GbEと比べてすぐに顕著な改善がみられます。マルチGigabit NBASE-T™対応の2.5GbEスイッチを提供、これにより既存のCAT5eケーブルを使って複数のコンピューターおよびNASが接続でき、予算を超えることなく、高速でセキュアかつスケーラブルなネットワーク環境を組織に導入することを支援します。
GPUアクセラレーションコンピューティングのためにグラフィックカードを取り付ける
グラフィックスカードは、グラフィカルな計算や変換のために最適化されていますが、他のハードウェアよりも多くの電力を必要としています。本製品は、NVIDIA® GeForce® GTX1650グラフィックスカードを含む、電源ケーブルを必要としないハイプロファイルグラフィックスカードをサポートするPCIeスロットを備えており、ビデオ編集、4K UHDトランスコーディング、QTSでの画像処理、GPUパススルーを介した仮想マシンのパフォーマンスなどのアプリケーション性能を向上させることができます。
最大5年までのハードウェア保証延長
本製品には、別途費用なしで3年保証が付いています。必要に応じて、最大5年までの延長保証を購入することができます。
10GbE SFP+と2.5GbEネットワークポートを備えたGNASⅢ-RM1U4Bは、高いネットワーク帯域幅を実現し、チームのコラボレーションとファイルアクセスを合理化します。1つのPCIe Gen 2 x2スロットにより、QNAP拡張カードをインストールして、ネットワーク接続性、SSDキャッシング機能やワイヤレス接続性を追加できます。必要な時にはいつでも即座に回復を実現する一方で、ファイルのバックアップと同期化、安全なスナップショット保護、Google™ WorkspaceとMicrosoft 365®エンタープライズアカウントバックアップサービスに対応しています。
より高いパフォーマンス x より速い処理能力
より高いパフォーマンスを実現する2GB DDR4 RAM(16GBまで拡張可能)とSATA 6Gb/sドライブを備えたAnnapurna Labs Alpine AL-324 ARM® Cortex®-A57クアッドコア1.7 GHzプロセッサを搭載しています。2つの10GbE SFP+と2つの2.5GbEネットワークポートを備えたGNAS-RM1U4Bは、信じられないくらいの帯域幅を実現し、高速ファイルアクセス、バックアップ/復元、メディア転送を満たします。さらに、個々のアプリケーションとサービスのためにネットワークリソースを柔軟に割り当てることができます。
マルチポイントのファイルバックアップ、アクセス、および同期
HBS(Hybrid Backup Sync)は、データのバックアップ、回復、データの同期化を統合します。高速10GbEの接続性により、別のGNAS、リモートサーバーやクラウドストレージにデータを容易にバックアップ/同期でき、信頼性の高い障害復旧ソリューションを構築できます。Qsync があれば、GNAS-RM1U4Bがファイル同期のための大容量の安全なデータセンターへと変身。GNAS-RM1U4Bにアップロードされたファイルは、デスクトップパソコンやノートパソコン、スマートフォンなど、接続されたすべての端末で利用できます。また、共有フォルダの同期やチームフォルダを作成することで、共同作業の効率を上げることも可能です。
頼れるサービスのための冗長性電源
GNAS-RM1U4Bは、サービスアップタイムを最大化するために冗長性電源を搭載しています。デュアル10GbE SFP+とデュアル2.5GbEポートを組み合わせ、 お客様のビジネスは容易に年中無休の稼働を維持でき、費用対効果が良く、信頼性の高いストレージソリューションを保証します。
データ増加に応じて拡張できる、モジュール型ストレージ拡張フレームワーク
GNAS-RM1U4Bのストレージ容量は、データ需要の増加に合わせて容易に拡張できます。ストレージ容量を拡張するには、必要に応じて、TR RAID拡張エンクロージャやTL JBODを接続するだけです。仮想JBOD(VJBOD)テクノロジーにより、GNAS-RM1U4Bの未使用のスペースが他のGNASのストレージ容量を拡張するために使用されます。
Intel® Celeron® J4125、クアッドコア2.0 GHzプロセッサを搭載した本製品は、2つの2.5GbE RJ45ポート特長としています。このモデルは、ギガビットイーサネットの最大2.5倍の速度を実現し、スムーズなマルチメディア再生と日常での利用を可能にします。PCIe Gen 2.0 x 2スロットを搭載した本製品は、NAS機能を柔軟に拡張でき、追加のネットワークポート、M.2 SSDキャッシング/ティアリングやWi-Fi接続性用のさまざまなカードをインストールできます。本製品は、AES 256ビット暗号化を使用してデータセキュリティを確保しており、保存されている機密性の高いビジネスデータの安全性を確保しながらシステムの性能を向上しています。
QNAPで高速ネットワークを構築
Intel® Celeron® J4125クアッドコア2.0 GHzプロセッサ(最大2.70 GHzまでバースト)、DDR4デュアルチャンネルRAM(最大8GB)、2つの2.5GbEギガビットLANポートを搭載した本製品は、スムーズなマルチメディア再生と日常でのNAS利用を可能にします。QNAPの追加の高速ネットワークオプションには、USB 3.2 Gen 1 to 2.5GbE/5GbEアダプター(N-BASET/Multi-Gigに対応)、QXG 5GbE/10GbE PCIeカード、QNAP QSW 10GbEスイッチが含まれます。これらすべてのオプションにより、ユーザーはネットワークをコスト効率良く大幅に改善できます。
PCIeカードでNASの機能性を拡張
PCIe Gen 2.0 x 2スロットにより、本製品はNAS機能拡張および将来のアプリケーション向けに柔軟性を提供しています。システム性能を最適化するには、QNAP QM2カードをインストールして、M.2 SATAやNVMe SSDキャッシング/10GbE接続性を追加し、最適なシステム性能を実現するためにQtier階層型記憶域と共に使用します。QNAP QWA-AC2600をインストールすることで、ワイヤレス接続性を追加できます。QXG-10GbE/5GbEネットワークカードは、超高速ネットワークポートを追加します。あるいは、お手頃なQNAP QNA-UC5G1T USB 3.2 Gen 1 to 5GbEアダプターを追加して、より高速なネットワーク速度を楽しんだり、USB 3.2 Gen 2(10Gbps)カードをインストールしてUSB接続性を向上させたりすることができます。
最適化されたストレージ効率のためのSSDキャッシングおよび自動階層化
本製品は、仮想化などのランダムIOPSを要求するアプリケーションのワークフローを向上するSSDキャッシングをサポートしています。Qtier™テクノロジーにより、高性能のSSDおよび大容量SATAドライブにわたるストレージ利用を継続的に最適化する自動階層化で本製品が強化されています。Qtier™ 2.0は、キャッシュのような予約スペースでSSD階層化ストレージを強化して、リアルタイムにバーストI/Oを処理し、SSDのメリットを最大限に引き出すことのできるIOへのケアを特長としています。
簡単で安全なファイル管理
File Stationでは、本製品やクラウドに保存したファイルを一元管理することができます。コンピューターからファイルを簡単にアップロードしたり、フォルダー間でファイルをドラッグアンドドロップでき、ファイル名の変更、ファイルの削除、ファイルの設定、不正アクセスを回避するためのフォルダー権限の変更を行うことができます。Microsoft Office Onlineを使用して、ローカルデバイスにダウンロードすることなく、本製品に保存されたMicrosoft Office文書を直接開いたり、修正したりすることができます。本製品に保存された機密性の高いファイルを共有する場合、File Stationを使用してファイルを.qencファイルに暗号化し、パスワードを設定し、QENC Decrypterを使用してファイルを復号します。
Intel® Celeron® J4125、クアッドコア2.0 GHzプロセッサを搭載した本製品は、2つの2.5GbE RJ45ポート特長としています。このモデルは、ギガビットイーサネットの最大2.5倍の速度を実現し、スムーズなマルチメディア再生と日常での利用を可能にします。PCIe Gen 2.0 x 2スロットを搭載した本製品は、NAS機能を柔軟に拡張でき、追加のネットワークポート、M.2 SSDキャッシング/ティアリングやWi-Fi接続性用のさまざまなカードをインストールできます。本製品は、AES 256ビット暗号化を使用してデータセキュリティを確保しており、保存されている機密性の高いビジネスデータの安全性を確保しながらシステムの性能を向上しています。
QNAPで高速ネットワークを構築
Intel® Celeron® J4125クアッドコア2.0 GHzプロセッサ(最大2.70 GHzまでバースト)、DDR4デュアルチャンネルRAM(最大8GB)、2つの2.5GbEギガビットLANポートを搭載した本製品は、スムーズなマルチメディア再生と日常でのNAS利用を可能にします。QNAPの追加の高速ネットワークオプションには、USB 3.2 Gen 1 to 2.5GbE/5GbEアダプター(N-BASET/Multi-Gigに対応)、QXG 5GbE/10GbE PCIeカード、QNAP QSW 10GbEスイッチが含まれます。これらすべてのオプションにより、ユーザーはネットワークをコスト効率良く大幅に改善できます。
PCIeカードでNASの機能性を拡張
PCIe Gen 2.0 x 2スロットにより、本製品はNAS機能拡張および将来のアプリケーション向けに柔軟性を提供しています。システム性能を最適化するには、QNAP QM2カードをインストールして、M.2 SATAやNVMe SSDキャッシング/10GbE接続性を追加し、最適なシステム性能を実現するためにQtier階層型記憶域と共に使用します。QNAP QWA-AC2600をインストールすることで、ワイヤレス接続性を追加できます。QXG-10GbE/5GbEネットワークカードは、超高速ネットワークポートを追加します。あるいは、お手頃なQNAP QNA-UC5G1T USB 3.2 Gen 1 to 5GbEアダプターを追加して、より高速なネットワーク速度を楽しんだり、USB 3.2 Gen 2(10Gbps)カードをインストールしてUSB接続性を向上させたりすることができます。
最適化されたストレージ効率のためのSSDキャッシングおよび自動階層化
本製品は、仮想化などのランダムIOPSを要求するアプリケーションのワークフローを向上するSSDキャッシングをサポートしています。Qtier™テクノロジーにより、高性能のSSDおよび大容量SATAドライブにわたるストレージ利用を継続的に最適化する自動階層化で本製品が強化されています。Qtier™ 2.0は、キャッシュのような予約スペースでSSD階層化ストレージを強化して、リアルタイムにバーストI/Oを処理し、SSDのメリットを最大限に引き出すことのできるIOへのケアを特長としています。
簡単で安全なファイル管理
File Stationでは、本製品やクラウドに保存したファイルを一元管理することができます。コンピューターからファイルを簡単にアップロードしたり、フォルダー間でファイルをドラッグアンドドロップでき、ファイル名の変更、ファイルの削除、ファイルの設定、不正アクセスを回避するためのフォルダー権限の変更を行うことができます。Microsoft Office Onlineを使用して、ローカルデバイスにダウンロードすることなく、本製品に保存されたMicrosoft Office文書を直接開いたり、修正したりすることができます。本製品に保存された機密性の高いファイルを共有する場合、File Stationを使用してファイルを.qencファイルに暗号化し、パスワードを設定し、QENC Decrypterを使用してファイルを復号します。
強力なAMD Ryzen™ V1000シリーズV1500Bクアッドコアプロセッサを搭載したGNAS-QN2U12Bは、仮想マシンのパフォーマンスを最大2.2GHzの4コア/8スレッドまでブーストできます。2つの2.5GbEポートと2つのPCIe Gen 3スロットを備えており、高速ネットワーク接続を提供し、更なる機能と追加のアプリケーションの可能性を付加することができます。また、システムのアップタイムを最大化するために冗長電源を搭載しています。
Ryzen™ V1500B搭載、高性能ラックマウントNAS
GNAS-QN2U12B は、AES-NI ハードウェア暗号化アクセラレーションと最大 64 GB の DDR4 メモリを備え、4コア/8スレッドの AMD Ryzen™ V1500B 2.2 GHz プロセッサを搭載したラックマウント型NASです。高性能ながら効率的な設計により、VDI、R&D、プライベートクラウド、サーバー仮想化など、リソース集約型のビジネスアプリケーションでも安定した処理能力を提供します。
2.5GbE対応LANポートとリンクアグリゲーションによる高速・冗長ネットワーク
GNAS-QN2U12B は、2基の 2.5GbE RJ45 LAN ポートを搭載しており、既存の CAT5e ケーブルを用いてネットワーク速度を 1GbE から 2.5GbE にアップグレード可能です。ポートトランキング(リンクアグリゲーション)を活用することで、最大 5GbE の帯域幅を実現でき、冗長性と負荷分散によるネットワーク安定性も向上します。さらに、ラップトップやデスクトップ端末の高速ネットワーク利用を支援するため、USB 3.2 Gen 1 to 5GbE アダプターや 5GbE PCIe 拡張カードなどの各種アダプター・周辺機器にも対応しています。
SSDキャッシュによるランダムI/O最適化と低レイテンシ化
GNAS-QN2U12B は、SSD キャッシュを追加することでストレージボリュームのランダム I/O 性能を大幅に向上させ、レイテンシを低減します。データベースや仮想化環境など IOPS を多く消費するアプリケーションに最適で、キャッシュ使用によりシステム全体のワークフロー効率が改善されます。SSD キャッシュの起動・停止および設定変更は、システムをシャットダウンすることなくリアルタイムで実行可能で、運用中の柔軟なパフォーマンス最適化をサポートします。
VJBOD対応による柔軟なNASストレージ拡張
GNAS-QN2U12B は、TR RAID 拡張エンクロージャや TL JBOD を接続することで、データ増加に応じた物理ストレージの容易な拡張をサポートします。加えて、仮想 JBOD(VJBOD)テクノロジーを活用することで、GNAS-QN2U12B の未使用ストレージ領域をネットワーク経由で他の GNAS デバイスに仮想的に割り当て、追加ハードウェアを導入せずにストレージ容量を拡張可能です。これにより、ストレージ資源を効率的に集約し、RAID 構成やデータ冗長性を維持しながら、複数 NAS 間で柔軟に容量を再配分できます。
強力なAMD Ryzen™ V1000シリーズV1500Bクアッドコアプロセッサを搭載したGNASⅢ-RM2U12Bは、仮想マシンのパフォーマンスを最大2.2GHzの4コア/8スレッドまでブーストできます。2つの2.5GbEポートと2つのPCIe Gen 3スロットを備えており、高速ネットワーク接続を提供し、更なる機能と追加のアプリケーションの可能性を付加することができます。また、システムのアップタイムを最大化するために冗長電源を搭載しています。
AMD Ryzen™および最大64GBのRAMによる絶対的なパフォーマンス
AES-NI暗号化アクセラレーションと最大64GB DDR4 RAMを備え、4コア/8スレッドAMD Ryzen™ V1500B 2.2GHzプロセッサを搭載したラックマウントGNASⅢ-RM2U12Bは、積極的ながらパワースマートなパフォーマンスを提供し、 VDI、R&D、プライベートクラウドやサーバー仮想化などのリソースを多く消費するビジネスアプリケーションをドライブします。
マル2.5GbEネットワーキングにアップグレード
GNASⅢ-RM2U12Bには、2つの2.5GbE RJ45 LANポートが付属しています。このポートは、既存のカテゴリー5eケーブルを使用して、ネットワーク速度を1 ギガビットから2.5ギガビットにアップグレードできます。ポートトランキングを使用することで、5GbEの速度を達成できます。ラップトップやデスクトップをアップグレードして、高速ネットワークを活用できるように、GNASⅢ-RM2U12BはUSB 3.2 Gen 1 to 5GbEアダプターと5GbE PCIe拡張カードなどを含む、さまざまなアダプターと周辺機器を提供しています。
SSDキャッシングによるIOPSパフォーマンスの高速化
GNASⅢ-RM2U12BへのSSDキャッシュ追加は、IOPSパフォーマンスを向上し、ストレージボリュームレイテンシーを低減させるための簡単な方法です。IOPSを要求するアプリケーション(データベースや仮想化を含む)に理想的です。また、全体的なワークフローを大幅に向上できます。必要に応じて、起動、停止、または設定の変更を、システムをシャットダウンすることなく行うことができます。
必要な時にはいつでも、柔軟にストレージ容量を拡張します
GNAS-RM1U4Bのストレージ容量は、データ需要の増加に合わせて容易に拡張できます。ストレージ容量を拡張するには、必要に応じて、TR RAID拡張エンクロージャやTL JBODを接続するだけです。仮想JBOD(VJBOD)テクノロジーにより、GNAS-RM1U4Bの未使用のスペースが他のGNASのストレージ容量を拡張するために使用されます。
強力なAMD Ryzen™ V1000シリーズV1500Bクアッドコアプロセッサを搭載したGNASⅢ-RM2U12Bは、仮想マシンのパフォーマンスを最大2.2GHzの4コア/8スレッドまでブーストできます。2つの2.5GbEポートと2つのPCIe Gen 3スロットを備えており、高速ネットワーク接続を提供し、更なる機能と追加のアプリケーションの可能性を付加することができます。また、システムのアップタイムを最大化するために冗長電源を搭載しています。
AMD Ryzen™および最大64GBのRAMによる絶対的なパフォーマンス
AES-NI暗号化アクセラレーションと最大64GB DDR4 RAMを備え、4コア/8スレッドAMD Ryzen™ V1500B 2.2GHzプロセッサを搭載したラックマウントGNASⅢ-RM2U12Bは、積極的ながらパワースマートなパフォーマンスを提供し、 VDI、R&D、プライベートクラウドやサーバー仮想化などのリソースを多く消費するビジネスアプリケーションをドライブします。
マル2.5GbEネットワーキングにアップグレード
GNASⅢ-RM2U12Bには、2つの2.5GbE RJ45 LANポートが付属しています。このポートは、既存のカテゴリー5eケーブルを使用して、ネットワーク速度を1 ギガビットから2.5ギガビットにアップグレードできます。ポートトランキングを使用することで、5GbEの速度を達成できます。ラップトップやデスクトップをアップグレードして、高速ネットワークを活用できるように、GNASⅢ-RM2U12BはUSB 3.2 Gen 1 to 5GbEアダプターと5GbE PCIe拡張カードなどを含む、さまざまなアダプターと周辺機器を提供しています。
SSDキャッシングによるIOPSパフォーマンスの高速化
GNASⅢ-RM2U12BへのSSDキャッシュ追加は、IOPSパフォーマンスを向上し、ストレージボリュームレイテンシーを低減させるための簡単な方法です。IOPSを要求するアプリケーション(データベースや仮想化を含む)に理想的です。また、全体的なワークフローを大幅に向上できます。必要に応じて、起動、停止、または設定の変更を、システムをシャットダウンすることなく行うことができます。
必要な時にはいつでも、柔軟にストレージ容量を拡張します
GNAS-RM1U4Bのストレージ容量は、データ需要の増加に合わせて容易に拡張できます。ストレージ容量を拡張するには、必要に応じて、TR RAID拡張エンクロージャやTL JBODを接続するだけです。仮想JBOD(VJBOD)テクノロジーにより、GNAS-RM1U4Bの未使用のスペースが他のGNASのストレージ容量を拡張するために使用されます。
UNI-i9ZR/Silentは第14世代インテル® Core™ プロセッサー(コードネーム:Raptor Lake Refresh)を搭載した静音モデルです。
第14世代インテル® Core™プロセッサー “Raptor Lake Refresh”搭載
最新のインテル® Core™ プロセッサー(第14世代)はRaptor Cove 高性能CPUコア(P-CORE)とGracemont 高効率CPUコア(E-CORE)によるハイブリッド構成の全く新しい新アーキテクチャで最大24コアを搭載。効率的なコアの使用により没入感のある高精細なゲームのパフォーマンス向上をはじめ、4K超ビデオコンテンツ制作などの最新の映像体験において驚異のエンターテインメント・ハブを提供します。
Intel® B760チップセット
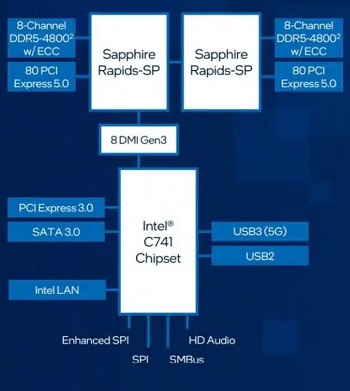
第14世代 intel Coreプロセッサ対応 intel B760搭載ATXマザーボードを採用。PCIe5.0対応PCIe×16スロット、USB3.2 Gen2×1 Type-C、3つのPCIe4.0接続対応M.2スロット、Realtek 2.5GbE等を搭載。従来のDIPスタイルのPCIeスロットと比較して、SMT(表面実装技術)タイプのPCIe スロットは、信号の流れを改善し高速での安定性を最大化しています。
CPUクーラーに「こだわり」の空冷システムメーカー Noctua搭載
ナローヒートシンクデザインを使用した、12cmファン搭載サイドフロー型のCPUクーラーを採用。スリム設計により、CPUソケット周辺のクリアランスを確保。メモリとの干渉も最小限に抑えこんでいます。
負荷 40% 以下でのセミファンレスモード& ハイブリッドスイッチ搭載 80 PLUS Gold認証の静音電源
高効率を実現できるハーフブリッジ形 LLC方式 DC/DCコンバータに、日本製コンデンサを100% 使用し、プロフェッショナルグレードの品質を実現しつつ、本体のハイブリッドスイッチで ON/OFFを切替可能なセミファンレスモードを搭載することにより、静音性と冷却性にも優れ た 80 PLUS Gold 認証 850W電源です。
ノイズを最小限に抑え、冷却効率に優れたSILENCIOデザイン
Silencioは、ソフトで厚みのあるフォーム材から高密度ビニールまで、特定の周波数を正確に打 ち消すために複数の遮音材を組み合わせて使用しています。 スチールフロントパネルは、開く方向を左右どちらにも変えることができるリバーシブルシス テムを採用しています。スチール部分に取付けられた厚みのある緩衝材と、マグネットとゴム パッドを使用したヒンジシステムによって、パーツ同士の接触部分の振動を抑えています。
UNI-i9ZR/Silentは第14世代インテル® Core™ プロセッサー(コードネーム:Raptor Lake Refresh)を搭載した静音モデルです。
第14世代インテル® Core™プロセッサー “Raptor Lake Refresh”搭載
最新のインテル® Core™ プロセッサー(第14世代)はRaptor Cove 高性能CPUコア(P-CORE)とGracemont 高効率CPUコア(E-CORE)によるハイブリッド構成の全く新しい新アーキテクチャで最大24コアを搭載。効率的なコアの使用により没入感のある高精細なゲームのパフォーマンス向上をはじめ、4K超ビデオコンテンツ制作などの最新の映像体験において驚異のエンターテインメント・ハブを提供します。
Intel® Z790チップセット
ビジネス向け 第13世代 intel Coreプロセッサ対応 intel Z790搭載ATXマザーボードを採用。PCIe5.0対応PCIe×16スロット、USB3.2 Gen2×2 Type-C、3つのPCIe4.0×4接続対応M.2スロット、PCIe3.0×4接続対応M.2スロット、intel 2.5GbE等を搭載。CPUとの接続にはDMI4.0x8が採用され、チップセットとCPU間のボトルネックが解消されています。
CPUクーラーに「こだわり」の空冷システムメーカー Noctua搭載
ナローヒートシンクデザインを使用した、12cmファン搭載サイドフロー型のCPUクーラーを採用。スリム設計により、CPUソケット周辺のクリアランスを確保。メモリとの干渉も最小限に抑えこんでいます。
負荷 40% 以下でのセミファンレスモード& ハイブリッドスイッチ搭載 80 PLUS Gold認証の静音電源
高効率を実現できるハーフブリッジ形 LLC方式 DC/DCコンバータに、日本製コンデンサを100% 使用し、プロフェッショナルグレードの品質を実現しつつ、本体のハイブリッドスイッチで ON/OFFを切替可能なセミファンレスモードを搭載することにより、静音性と冷却性にも優れ た 80 PLUS Gold 認証 850W電源です。
ノイズを最小限に抑え、冷却効率に優れたSILENCIOデザイン
Silencioは、ソフトで厚みのあるフォーム材から高密度ビニールまで、特定の周波数を正確に打 ち消すために複数の遮音材を組み合わせて使用しています。 スチールフロントパネルは、開く方向を左右どちらにも変えることができるリバーシブルシス テムを採用しています。スチール部分に取付けられた厚みのある緩衝材と、マグネットとゴム パッドを使用したヒンジシステムによって、パーツ同士の接触部分の振動を抑えています。
UNI-i9ZR/Silentは第14世代インテル® Core™ プロセッサー(コードネーム:Raptor Lake Refresh)を搭載した静音モデルです。
第14世代インテル® Core™プロセッサー “Raptor Lake Refresh”搭載
最新のインテル® Core™ プロセッサー(第14世代)はRaptor Cove 高性能CPUコア(P-CORE)とGracemont 高効率CPUコア(E-CORE)によるハイブリッド構成の全く新しい新アーキテクチャで最大24コアを搭載。効率的なコアの使用により没入感のある高精細なゲームのパフォーマンス向上をはじめ、4K超ビデオコンテンツ制作などの最新の映像体験において驚異のエンターテインメント・ハブを提供します。
Intel® Z790チップセット
ビジネス向け 第13世代 intel Coreプロセッサ対応 intel Z790搭載ATXマザーボードを採用。PCIe5.0対応PCIe×16スロット、USB3.2 Gen2×2 Type-C、3つのPCIe4.0×4接続対応M.2スロット、PCIe3.0×4接続対応M.2スロット、intel 2.5GbE等を搭載。CPUとの接続にはDMI4.0x8が採用され、チップセットとCPU間のボトルネックが解消されています。
CPUクーラーに「こだわり」の空冷システムメーカー Noctua搭載
ナローヒートシンクデザインを使用した、12cmファン搭載サイドフロー型のCPUクーラーを採用。スリム設計により、CPUソケット周辺のクリアランスを確保。メモリとの干渉も最小限に抑えこんでいます。
負荷 40% 以下でのセミファンレスモード& ハイブリッドスイッチ搭載 80 PLUS Gold認証の静音電源
高効率を実現できるハーフブリッジ形 LLC方式 DC/DCコンバータに、日本製コンデンサを100% 使用し、プロフェッショナルグレードの品質を実現しつつ、本体のハイブリッドスイッチで ON/OFFを切替可能なセミファンレスモードを搭載することにより、静音性と冷却性にも優れ た 80 PLUS Gold 認証 850W電源です。
ノイズを最小限に抑え、冷却効率に優れたSILENCIOデザイン
Silencioは、ソフトで厚みのあるフォーム材から高密度ビニールまで、特定の周波数を正確に打 ち消すために複数の遮音材を組み合わせて使用しています。 スチールフロントパネルは、開く方向を左右どちらにも変えることができるリバーシブルシス テムを採用しています。スチール部分に取付けられた厚みのある緩衝材と、マグネットとゴム パッドを使用したヒンジシステムによって、パーツ同士の接触部分の振動を抑えています。
UNI-i9ZRは、第14世代 Intel® Core™ デスクトッププロセッサ(Raptor Lake-S Refresh)を搭載したモデルです。前世代の Alder Lake-S と比較して、クロックの向上に加え、キャッシュメモリ容量の増加や E-CORE のコア数拡張により、大幅な性能向上を実現しました。Raptor Cove を採用した高性能コア(P-CORE)と、Gracemont を採用した高効率コア(E-CORE)によるハイブリッド構成により、最大24コアを搭載可能です。これにより、効率的なコア利用が可能となり、高精細コンテンツの処理性能向上はもちろん、高速演算、シミュレーション、グラフィック作業など、CPUパワーを必要とする幅広い作業において高いパフォーマンスを提供します。
第14世代 Intel® Core™ デスクトッププロセッサ(Raptor Lake-S Refresh)搭載
第14世代 インテル® Core™ プロセッサー(コードネーム:Raptor Lake-S Refresh)は、Raptor Cove 高性能CPUコア(P-CORE)と Gracemont 高効率CPUコア(E-CORE)によるハイブリッド構成を採用し、最大24コアを搭載する最新アーキテクチャです。前世代からの改良によりクロックが向上し、キャッシュメモリの強化や E-CORE 数の拡張によって、さらなる性能向上を実現しています。効率的なコア運用により、没入感のある高精細ゲームの描画性能向上はもちろん、4K 以上のビデオ編集、映像制作、仮想現実(VR)など、最新の映像・クリエイティブワークにおいても優れたパフォーマンスを発揮し、卓越したエンターテインメント体験を提供します。
Intel® B760チップセット
第14世代 intel Coreプロセッサ対応 intel B760搭載ATXマザーボードを採用。PCIe5.0対応PCIe×16スロット、USB3.2 Gen2×1 Type-C、3つのPCIe4.0接続対応M.2スロット、Realtek 2.5GbE等を搭載。従来のDIPスタイルのPCIeスロットと比較して、SMT(表面実装技術)タイプのPCIe スロットは、信号の流れを改善し高速での安定性を最大化しています。
PCI-Express 5.0 に対応
Alder Lake-SのCPU及び、Z690マザーボードは最新のPCI-Express 5.0に対応しており、従来のPCI-Express 4.0に比べて2倍の転送速度を持っております。x1で4GB/s、x4で16GB/s、x8で32GB/s、x16で64GB/sの転送速度を発揮します。最大レーン数がx4に縛られるM.2接続の機器などでは大きな恩恵を受ける事が可能です。特にM.2接続のNVMe SSDでは現在最新のPCIe 4.0ではx4接続では理論上は最大8GB/sの転送速度が実現可能となっていますが、既にPCIe 4.0対応のNVMe SSDでは最大リード速度が7GB/sに達している製品が多く、既にPCIe 4.0の規格上限値に限りなく近くなっておりました。これが、PCIe 5.0対応となると最大16GB/sまで理論的には対応可能になるため、現行の約2倍高速なNVMe SSDが搭載可能となります。
最大5基のストレージベイを搭載
HDD ケージシステムには 3.5 インチまたは 2.5 インチドライブを最大 5台まで設置可能、従来よりも更に優れた拡張性を実現。ユーザー個人の好みに応じてケースレイアウトを変更可能です。
UNI-i9ZRは第13世代インテル® Core™ プロセッサー(コードネーム:Raptor Lake-S)を搭載したモデルです。
第13世代インテル® Core™プロセッサー “Raptor Lake-S”搭載
第13世代インテル® Core™ プロセッサー(コードネーム:RaptorLake-S)はRaptor Cove 高性能CPUコア(P-CORE)とGracemont 高効率CPUコア(E-CORE)によるハイブリッド構成の全く新しい新アーキテクチャで最大24コアを搭載。
Intel® Z790チップセット
ビジネス向け 第13世代 intel Coreプロセッサ対応 intel Z790搭載ATXマザーボードを採用。PCIe5.0対応PCIe×16スロット、USB3.2 Gen2×2 Type-C、3つのPCIe4.0×4接続対応M.2スロット、PCIe3.0×4接続対応M.2スロット、intel 2.5GbE等を搭載。CPUとの接続にはDMI4.0x8が採用され、チップセットとCPU間のボトルネックが解消されています。
PCI-Express 5.0 に対応
Alder Lake-SのCPU及び、Z690マザーボードは最新のPCI-Express 5.0に対応しており、従来のPCI-Express 4.0に比べて2倍の転送速度を持っております。x1で4GB/s、x4で16GB/s、x8で32GB/s、x16で64GB/sの転送速度を発揮します。最大レーン数がx4に縛られるM.2接続の機器などでは大きな恩恵を受ける事が可能です。特にM.2接続のNVMe SSDでは現在最新のPCIe 4.0ではx4接続では理論上は最大8GB/sの転送速度が実現可能となっていますが、既にPCIe 4.0対応のNVMe SSDでは最大リード速度が7GB/sに達している製品が多く、既にPCIe 4.0の規格上限値に限りなく近くなっておりました。これが、PCIe 5.0対応となると最大16GB/sまで理論的には対応可能になるため、現行の約2倍高速なNVMe SSDが搭載可能となります。
最大5基のストレージベイを搭載
HDD ケージシステムには 3.5 インチまたは 2.5 インチドライブを最大 5台まで設置可能、従来よりも更に優れた拡張性を実現。ユーザー個人の好みに応じてケースレイアウトを変更可能です。
UNI-i9ZRは第13世代インテル® Core™ プロセッサー(コードネーム:Raptor Lake-S)を搭載したモデルです。
第13世代インテル® Core™プロセッサー “Raptor Lake-S”搭載
第13世代インテル® Core™ プロセッサー(コードネーム:RaptorLake-S)はRaptor Cove 高性能CPUコア(P-CORE)とGracemont 高効率CPUコア(E-CORE)によるハイブリッド構成の全く新しい新アーキテクチャで最大24コアを搭載。
Intel® Z790チップセット
ビジネス向け 第13世代 intel Coreプロセッサ対応 intel Z790搭載ATXマザーボードを採用。PCIe5.0対応PCIe×16スロット、USB3.2 Gen2×2 Type-C、3つのPCIe4.0×4接続対応M.2スロット、PCIe3.0×4接続対応M.2スロット、intel 2.5GbE等を搭載。CPUとの接続にはDMI4.0x8が採用され、チップセットとCPU間のボトルネックが解消されています。
PCI-Express 5.0 に対応
Alder Lake-SのCPU及び、Z690マザーボードは最新のPCI-Express 5.0に対応しており、従来のPCI-Express 4.0に比べて2倍の転送速度を持っております。x1で4GB/s、x4で16GB/s、x8で32GB/s、x16で64GB/sの転送速度を発揮します。最大レーン数がx4に縛られるM.2接続の機器などでは大きな恩恵を受ける事が可能です。特にM.2接続のNVMe SSDでは現在最新のPCIe 4.0ではx4接続では理論上は最大8GB/sの転送速度が実現可能となっていますが、既にPCIe 4.0対応のNVMe SSDでは最大リード速度が7GB/sに達している製品が多く、既にPCIe 4.0の規格上限値に限りなく近くなっておりました。これが、PCIe 5.0対応となると最大16GB/sまで理論的には対応可能になるため、現行の約2倍高速なNVMe SSDが搭載可能となります。
最大5基のストレージベイを搭載
HDD ケージシステムには 3.5 インチまたは 2.5 インチドライブを最大 5台まで設置可能、従来よりも更に優れた拡張性を実現。ユーザー個人の好みに応じてケースレイアウトを変更可能です。
最新インテル第14世代 コードネーム Raptor Lake-S Refresh(ラプターレイクリフレッシュ)を搭載したデスクサイドGPUワークステーションです。Pコア+Eコア合計24コアで 最大Thermal Velocity Boost 6.0GHz動作の「Inte® Core™ i9-14900KF」をはじめとした」ラインナップによりCPU性能を大幅に向上させています。また、プラットフォームでは PCIe 5.0をサポート 、最大16のPCI Express 5.0レーンにより、RTX 4090 をはじめとする 次世代 NVIDIA Ada Lovelace アーキテクチャ GPU搭載で最適に動作することができ、高速演算やシミュレーション、グラフィック作業などCPUパワーを必要する作業に満足のいくパフォーマンスを提供できるモデルです。
※注意:このモデルはCPU 仕様によりPCIe Lanes数は20までとなり、2枚のGPUを搭載可能ですが、1枚目はx16転送レート(理論値 256.0Gbps)、2枚目はx4転送レート(理論値 64.0Gbps)での動作となります。
NVIDIA Ada Lovelace アーキテクチャ 世代 TDP 450W クラスGPUカードが搭載可能
第 4 世代 Tensor コアにより Tensor コアは、新しい FP8 Transformer エンジンを使用して、驚異的に速い、最大 5 倍のスループットの向上と、1.4 Tensor-petaFLOPS の性能を実現し、Ada の第 3 世代 RT コアは、レイ-トライアングル交差のスループットが 2 倍になり、RT-TFLOP 性能が 2 倍以上向上します。これらプロフェッショナル グラフィックス、AI、コンピューティング性能を実現するために設計されていおります。
第14世代インテル® Core™プロセッサー “Raptor Lake Refresh”搭載
最新のインテル® Core™ プロセッサー(第14世代)はRaptor Cove 高性能CPUコア(P-CORE)とGracemont 高効率CPUコア(E-CORE)によるハイブリッド構成の全く新しい新アーキテクチャで最大24コアを搭載。効率的なコアの使用により没入感のある高精細なゲームのパフォーマンス向上をはじめ、4K超ビデオコンテンツ制作などの最新の映像体験において驚異のエンターテインメント・ハブを提供します。
安定度抜群の高効率電源
採用されている電源は高品質のDC-DCコンバータを使用した大容量高効率ユニットです。100V環境で1200W の容量を実現しワークステーション用途はもちろん、サーバーレベルの要求仕様も満たす品質と高いTDPを要求する演算用GPUカードも安定した性能を発揮出来る余裕のマージン設計です。
最新インテル第14世代 コードネーム Raptor Lake-S Refresh(ラプターレイクリフレッシュ)を搭載したデスクサイドGPUワークステーションです。Pコア+Eコア合計24コアで 最大Thermal Velocity Boost 6.0GHz動作の「Inte® Core™ i9-14900KF」をはじめとした」ラインナップによりCPU性能を大幅に向上させています。また、プラットフォームでは PCIe 5.0をサポート 、最大16のPCI Express 5.0レーンにより、RTX 4090 をはじめとする 次世代 NVIDIA Ada Lovelace アーキテクチャ GPU搭載で最適に動作することができ、高速演算やシミュレーション、グラフィック作業などCPUパワーを必要する作業に満足のいくパフォーマンスを提供できるモデルです。
※注意:このモデルはCPU 仕様によりPCIe Lanes数は20までとなり、2枚のGPUを搭載可能ですが、1枚目はx16転送レート(理論値 256.0Gbps)、2枚目はx4転送レート(理論値 64.0Gbps)での動作となります。
NVIDIA Ada Lovelace アーキテクチャ 世代 TDP 450W クラスGPUカードが搭載可能
第 4 世代 Tensor コアにより Tensor コアは、新しい FP8 Transformer エンジンを使用して、驚異的に速い、最大 5 倍のスループットの向上と、1.4 Tensor-petaFLOPS の性能を実現し、Ada の第 3 世代 RT コアは、レイ-トライアングル交差のスループットが 2 倍になり、RT-TFLOP 性能が 2 倍以上向上します。これらプロフェッショナル グラフィックス、AI、コンピューティング性能を実現するために設計されていおります。
第14世代インテル® Core™プロセッサー “Raptor Lake Refresh”搭載
最新のインテル® Core™ プロセッサー(第14世代)はRaptor Cove 高性能CPUコア(P-CORE)とGracemont 高効率CPUコア(E-CORE)によるハイブリッド構成の全く新しい新アーキテクチャで最大24コアを搭載。効率的なコアの使用により没入感のある高精細なゲームのパフォーマンス向上をはじめ、4K超ビデオコンテンツ制作などの最新の映像体験において驚異のエンターテインメント・ハブを提供します。
安定度抜群の高効率電源
採用されている電源は高品質のDC-DCコンバータを使用した大容量高効率ユニットです。100V環境で1200W の容量を実現しワークステーション用途はもちろん、サーバーレベルの要求仕様も満たす品質と高いTDPを要求する演算用GPUカードも安定した性能を発揮出来る余裕のマージン設計です。
GWS-IARGA-1Gは、Intel® Core™ Ultra プロセッサを採用し、Performanceコア(Pコア)とEfficiencyコア(Eコア)によるハイブリッド・アーキテクチャを実装しています。これにより、スレッドレベルでの動的スケジューリングが最適化され、シングルスレッド性能を要する処理から並列性の高いマルチスレッド処理まで、タスク負荷に応じた効率的なリソース配分が可能です。またGPUには、RTX™ 6000 Blackwell Max-Q Workstation Edition、RTX™ 6000 Blackwell Workstation Edition、またはNVIDIA GeForce RTX 5090のいずれかを搭載可能。これらのGPUは、Blackwell アーキテクチャによるFP8/FP16演算性能と高帯域のメモリ帯域幅を備えており、AIモデルの学習・推論、3Dレンダリング、ディープラーニング推論などGPUコンピュート負荷の高いワークロードにおいて卓越した処理スループットを発揮します。加えて、最大256GBのDDR5メモリをサポートしており、大規模データセットやマルチアプリケーション環境でも安定した処理性能を維持できます。同時に、システムドライブとしてセットアップされたM.2 SSDにより、OSおよび主要アプリケーションの起動を高速化します。その上、データ用ストレージスロットを2基備え、プロジェクトごとのデータ分離や作業用・保管用データの効率的運用が可能です。
カスタマイズメニューに無い構成はお気軽に弊社までお問い合わせ下さい。お客様のご要望に合わせて抜群のコストパフォーマンスと安定した利用環境をご提供します。
NVIDIA RTX PRO 6000 Blackwell シリーズ製品比較レポート
Intel Core Ultra を採用
GWS-IARGA-1Gは、Intel Core Ultra を搭載することで、AI時代に最適化された高性能環境を実現します。高性能コア(Pコア)と高効率コア(Eコア)がリアルタイムにタスクを解析し、負荷に応じて自動的に最適化。これにより、重いAI演算から軽いバックグラウンド処理まで、あらゆるワークロードで安定した処理能力を発揮します。さらに、AI専用エンジン NPU(Neural Processing Unit)により、生成AIや機械学習、データ解析といった高度なAIワークロードも効率的に実行可能です。内蔵の Intel Arc GPU がグラフィック処理を強化し、3Dレンダリングや科学計算、AI推論などもスムーズに処理できます。また高速メモリや PCIe Gen 5 SSD との連携により、大規模データの読み書きも高速化。これにより、AI開発や解析作業、シミュレーションなど、多様な業務において卓越した演算性能と安定性を提供します。
最大1基の高性能GPUを搭載
GWS-IARGA-1Gは、Blackwell GPU を搭載することで、GPU負荷の高い処理を高速かつ効率的に実行できます。高度な並列演算能力を持つ Blackwell アーキテクチャにより、AIモデルの学習や推論、大規模データ解析を迅速に処理。さらに、リアルタイムレンダリングや3Dグラフィックス計算も滑らかに実行でき、複雑なシミュレーションや高度な解析作業でも優れた演算性能を発揮します。Blackwell GPU は専用の高速メモリを備えており、大量データをGPU内で直接処理可能です。加えて、CPUやストレージからGPUへのデータ転送速度が向上しているため、GPUがデータ待ちになる時間を最小化。これにより、大規模データや複数のAIタスクも滞りなく処理でき、GPUの演算能力をフルに活かすことができます。AI開発、科学計算、生成AIモデルの推論など、多様なGPUワークロードにおいて、Blackwell GPU は高効率な並列演算能力と持続的安定動作を提供します。
効率化ストレージ設計
GWS-IARGA-1Gは、M.2 SSD をブートストレージに採用することで、OS やアプリケーションの起動時間を大幅に短縮し、システム全体の応答性と操作感を向上させます。さらに、データ用ストレージを2枚搭載することで、大容量データの管理や複数プロジェクトの同時運用が容易になり、柔軟なデータ整理と効率的なバックアップ運用を実現します。これにより、業務中の待機時間を最小化するとともに、解析作業やAI処理、シミュレーションなどの大量データを扱う高度な作業でも、安定かつスムーズなワークフローを維持できます。加えて、M.2 SSDとデータ用ストレージの組み合わせにより、ストレージ間のデータ移動や読み書きも高速化され、全体的な作業効率をさらに高めることが可能です。
大容量メモリによる安定したマルチタスク性能
最大256GBのDDR5メモリを搭載可能とし、大規模データセットの処理や複数アプリケーションの同時実行においても安定したパフォーマンスを発揮します。高帯域かつ低レイテンシなメモリアーキテクチャにより、データ転送時のボトルネックを抑制し、AI開発やシミュレーション、データ分析などのメモリ負荷の高いワークロードにおいてもスムーズな処理を実現します。さらに、仮想環境の同時稼働や大規模モデルの展開、複数プロジェクトの並行処理といった高度な利用シーンにおいても安定したリソース供給を維持し、ワークロードの集中時でも処理遅延を抑えます。加えて、将来的なデータ増加や処理規模の拡張にも柔軟に対応可能な設計とすることで、長期的な運用においても安心して利用できる拡張性を確保しています。長時間の連続稼働や高負荷環境下でも性能低下を最小限に抑え、処理の中断や遅延を防ぎながら、業務効率と生産性の向上に貢献します。
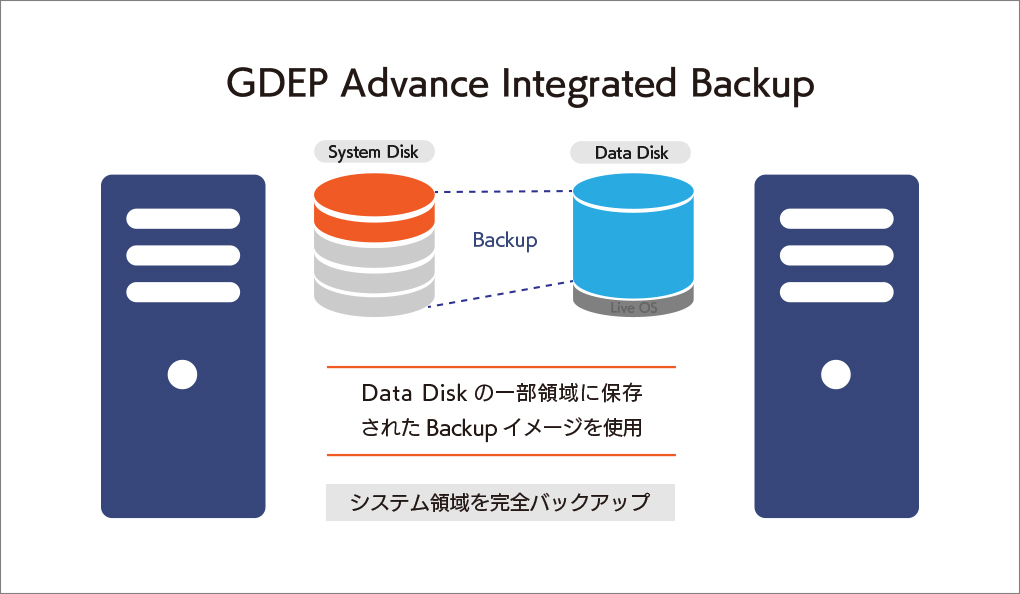
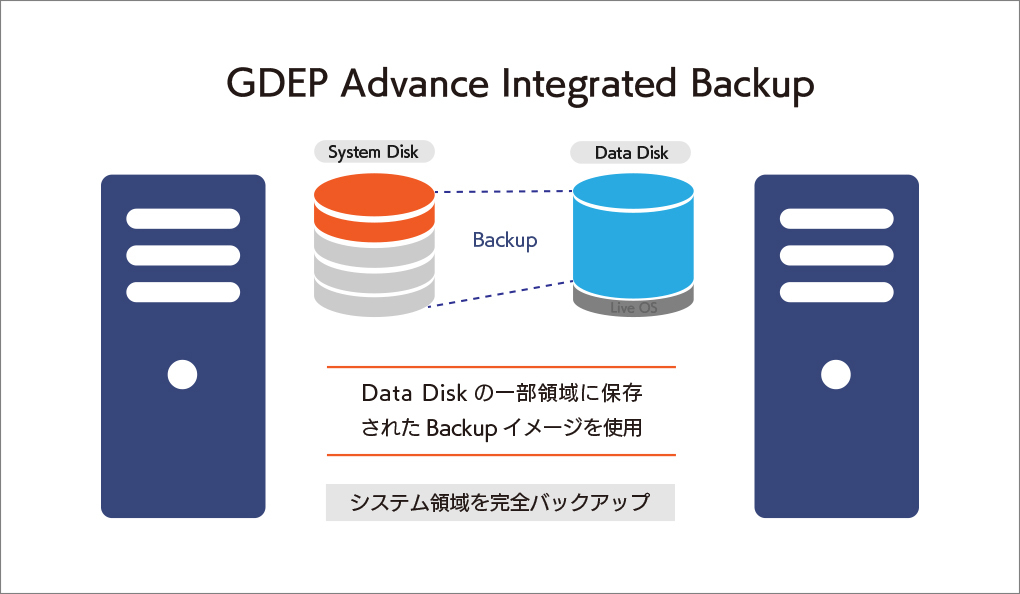
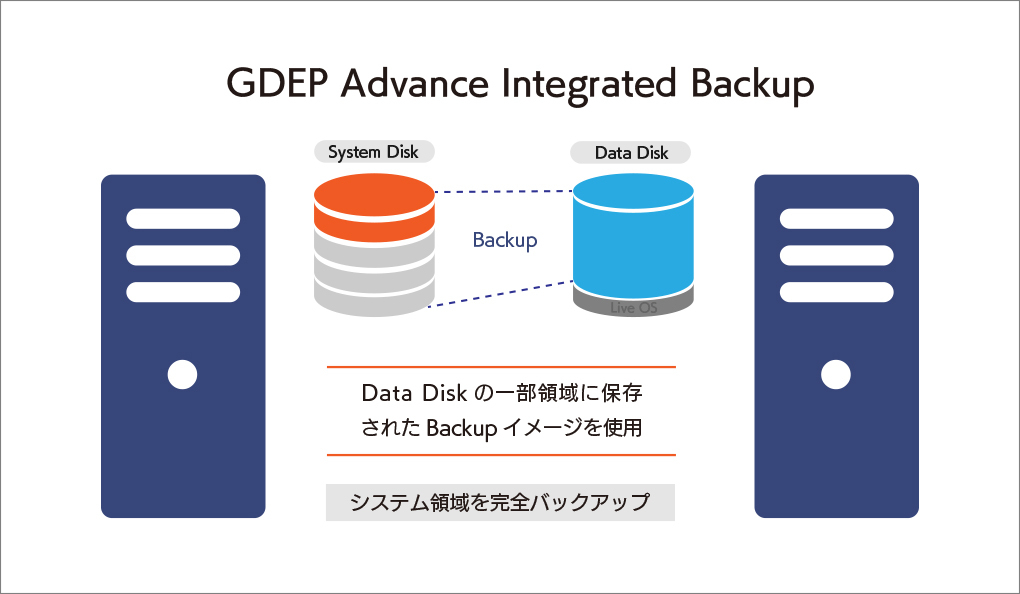
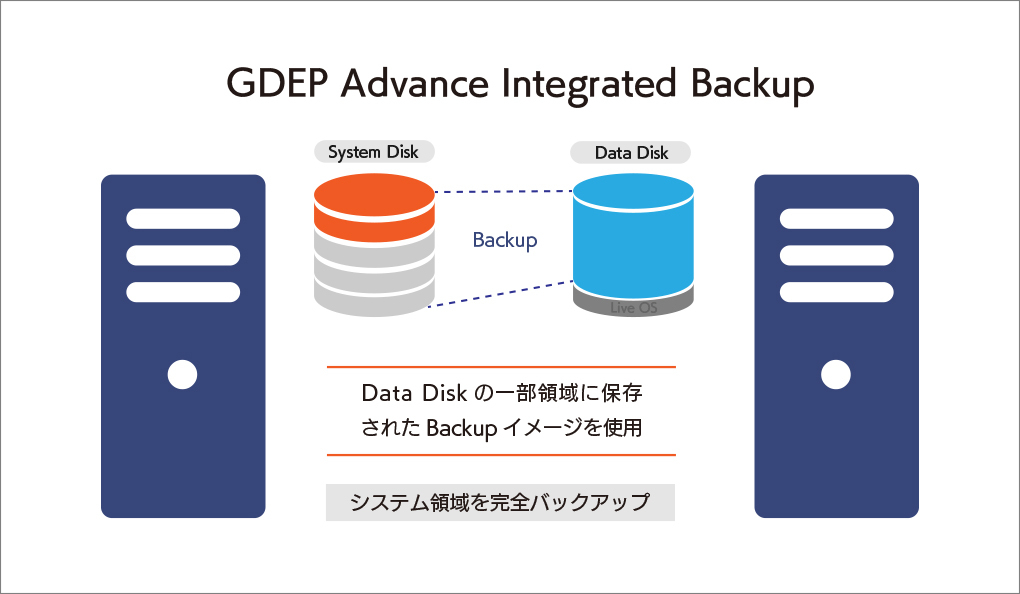
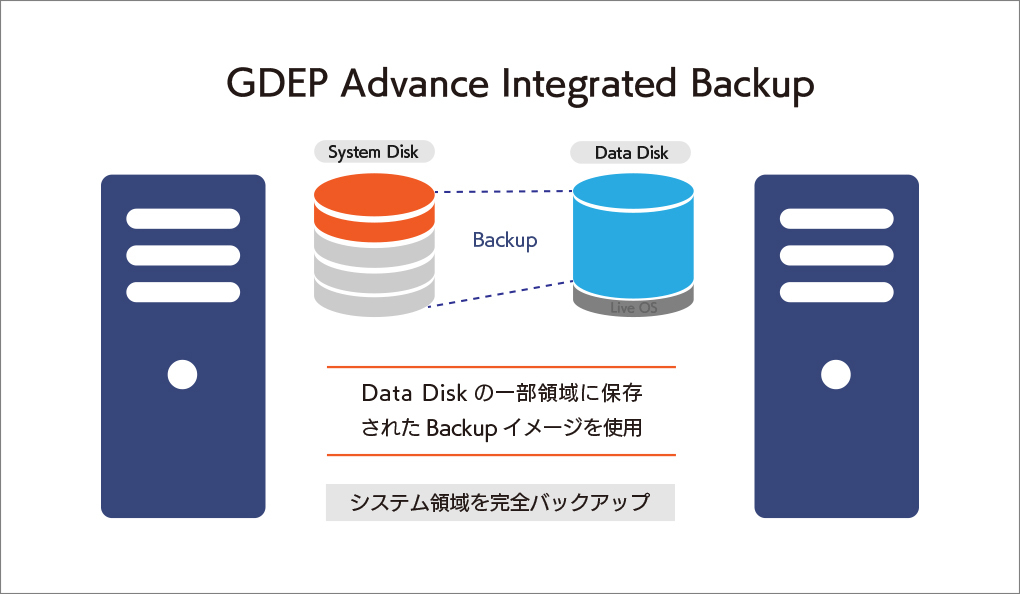
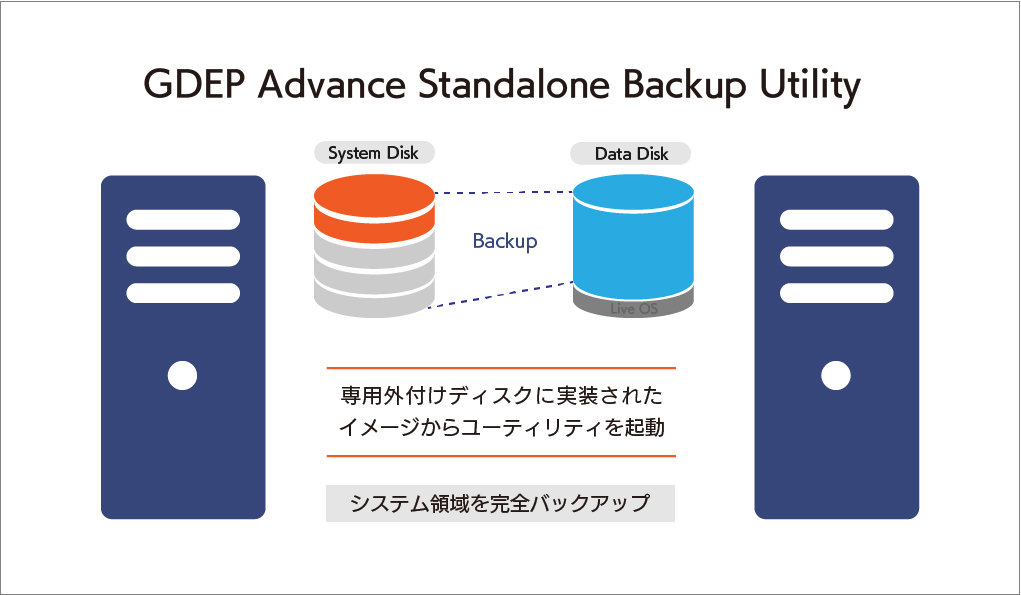
大切なシステムを丸ごと守る、安心の完全バックアップIntegrated Backup搭載
GDEP Advance Integrated Backup(以下 Integrated Backup)はジーデップ・アドバンスが提供する コンピュータのシステム領域を完全バックアップするためのユーティリティツールです。 システムディスクのパーティション、ファイルシステムフォーマット、データ内容をすべて記録することが可能で、日付やコメントをつけてバックアップ内容を管理できます。ブートディスク消失時の復旧や、過去にバックアップしたの状態への復帰などが容易に行えます。 【動作条件】 ・システムディスク以外にデータディスクが一つ以上装備されている必要があります。 ・バックアップイメージはシステムディスク以外のディスクに独立して組み込まれます。 ・OSをシャットダウンさせたうえで、バックアップが入っているディスクからブートさせます。 ・バックアップデータは日付別に分類されて保存されます。
GWS-IARGA-1Gは、Intel® Core™ Ultra プロセッサを採用し、Performanceコア(Pコア)とEfficiencyコア(Eコア)によるハイブリッド・アーキテクチャを実装しています。これにより、スレッドレベルでの動的スケジューリングが最適化され、シングルスレッド性能を要する処理から並列性の高いマルチスレッド処理まで、タスク負荷に応じた効率的なリソース配分が可能です。またGPUには、RTX™ 6000 Blackwell Max-Q Workstation Edition、RTX™ 6000 Blackwell Workstation Edition、またはNVIDIA GeForce RTX 5090のいずれかを搭載可能。これらのGPUは、Blackwell アーキテクチャによるFP8/FP16演算性能と高帯域のメモリ帯域幅を備えており、AIモデルの学習・推論、3Dレンダリング、ディープラーニング推論などGPUコンピュート負荷の高いワークロードにおいて卓越した処理スループットを発揮します。加えて、最大256GBのDDR5メモリをサポートしており、大規模データセットやマルチアプリケーション環境でも安定した処理性能を維持できます。同時に、システムドライブとしてセットアップされたM.2 SSDにより、OSおよび主要アプリケーションの起動を高速化します。その上、データ用ストレージスロットを2基備え、プロジェクトごとのデータ分離や作業用・保管用データの効率的運用が可能です。 カスタマイズメニューに無い構成はお気軽に弊社までお問い合わせ下さい。お客様のご要望に合わせて抜群のコストパフォーマンスと安定した利用環境をご提供します。
Intel Core Ultra を採用
GWS-IARGA-1Gは、Intel Core Ultra を搭載することで、AI時代に最適化された高性能環境を実現します。高性能コア(Pコア)と高効率コア(Eコア)がリアルタイムにタスクを解析し、負荷に応じて自動的に最適化。これにより、重いAI演算から軽いバックグラウンド処理まで、あらゆるワークロードで安定した処理能力を発揮します。さらに、AI専用エンジン NPU(Neural Processing Unit)により、生成AIや機械学習、データ解析といった高度なAIワークロードも効率的に実行可能です。内蔵の Intel Arc GPU がグラフィック処理を強化し、3Dレンダリングや科学計算、AI推論などもスムーズに処理できます。また高速メモリや PCIe Gen 5 SSD との連携により、大規模データの読み書きも高速化。これにより、AI開発や解析作業、シミュレーションなど、多様な業務において卓越した演算性能と安定性を提供します。
最大1基の高性能GPUを搭載
GWS-IARGA-1Gは、Blackwell GPU を搭載することで、GPU負荷の高い処理を高速かつ効率的に実行できます。高度な並列演算能力を持つ Blackwell アーキテクチャにより、AIモデルの学習や推論、大規模データ解析を迅速に処理。さらに、リアルタイムレンダリングや3Dグラフィックス計算も滑らかに実行でき、複雑なシミュレーションや高度な解析作業でも優れた演算性能を発揮します。Blackwell GPU は専用の高速メモリを備えており、大量データをGPU内で直接処理可能です。加えて、CPUやストレージからGPUへのデータ転送速度が向上しているため、GPUがデータ待ちになる時間を最小化。これにより、大規模データや複数のAIタスクも滞りなく処理でき、GPUの演算能力をフルに活かすことができます。AI開発、科学計算、生成AIモデルの推論など、多様なGPUワークロードにおいて、Blackwell GPU は高効率な並列演算能力と持続的安定動作を提供します。
効率化ストレージ設計
GWS-IARGA-1Gは、M.2 SSD をブートストレージに採用することで、OS やアプリケーションの起動時間を大幅に短縮し、システム全体の応答性と操作感を向上させます。さらに、データ用ストレージを2枚搭載することで、大容量データの管理や複数プロジェクトの同時運用が容易になり、柔軟なデータ整理と効率的なバックアップ運用を実現します。これにより、業務中の待機時間を最小化するとともに、解析作業やAI処理、シミュレーションなどの大量データを扱う高度な作業でも、安定かつスムーズなワークフローを維持できます。加えて、M.2 SSDとデータ用ストレージの組み合わせにより、ストレージ間のデータ移動や読み書きも高速化され、全体的な作業効率をさらに高めることが可能です。
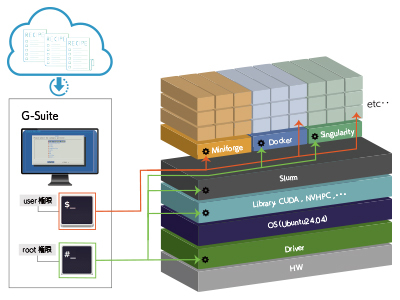
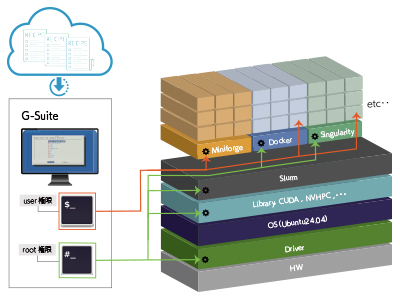
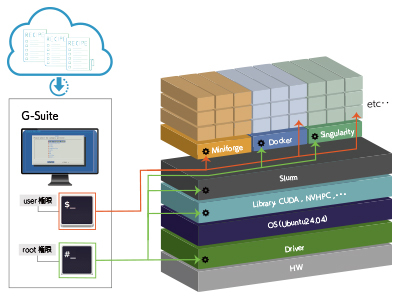
DeepLearning開発環境「G-Suite」
G-Suiteは、これまでジーデップ・アドバンスが提供してきた「G-Works」の仕組み(Deep Learning の主要なフレームワークを、各世代のGPU に最適化してビルドしたソフトウェア群)を継承し、さらに発展させたOS ネイティブ環境+コンテナ環境のハイブリッドアプリケーションリソースマネージメントツールです。インターネット上のWeb サイトから様々なレシピやサポートツール群をダウンロードし、簡易解説書やチュートリアルを含むアプリケーション実行環境を構築することが可能です。Ubuntu 24.04に対応し、開発環境は miniforgeをベースとしています。各世代のGPU に最適化してビルドしたソフトウェア群に加え、OS ネイティブ環境+コンテナ環境をハイブリッドにサポートしています。
Ubuntu 22.04に対応する「G-Works4.0」を選択されたい場合は こちら からご覧ください。
大切なシステムを丸ごと守る、安心の完全バックアップIntegrated Backup搭載
GDEP Advance Integrated Backup(以下 Integrated Backup)はジーデップ・アドバンスが提供する コンピュータのシステム領域を完全バックアップするためのユーティリティツールです。 システムディスクのパーティション、ファイルシステムフォーマット、データ内容をすべて記録することが可能で、日付やコメントをつけてバックアップ内容を管理できます。ブートディスク消失時の復旧や、過去にバックアップしたの状態への復帰などが容易に行えます。 【動作条件】 ・システムディスク以外にデータディスクが一つ以上装備されている必要があります。 ・バックアップイメージはシステムディスク以外のディスクに独立して組み込まれます。 ・OSをシャットダウンさせたうえで、バックアップが入っているディスクからブートさせます。 ・バックアップデータは日付別に分類されて保存されます。
GWS-IARGA-1Gは、Intel® Core™ Ultra プロセッサを採用し、Performanceコア(Pコア)とEfficiencyコア(Eコア)によるハイブリッド・アーキテクチャを実装しています。これにより、スレッドレベルでの動的スケジューリングが最適化され、シングルスレッド性能を要する処理から並列性の高いマルチスレッド処理まで、タスク負荷に応じた効率的なリソース配分が可能です。またGPUには、RTX™ 6000 Blackwell Max-Q Workstation Edition、RTX™ 6000 Blackwell Workstation Edition、またはNVIDIA GeForce RTX 5090のいずれかを搭載可能。これらのGPUは、Blackwell アーキテクチャによるFP8/FP16演算性能と高帯域のメモリ帯域幅を備えており、AIモデルの学習・推論、3Dレンダリング、ディープラーニング推論などGPUコンピュート負荷の高いワークロードにおいて卓越した処理スループットを発揮します。加えて、最大256GBのDDR5メモリをサポートしており、大規模データセットやマルチアプリケーション環境でも安定した処理性能を維持できます。同時に、システムドライブとしてセットアップされたM.2 SSDにより、OSおよび主要アプリケーションの起動を高速化します。その上、データ用ストレージスロットを2基備え、プロジェクトごとのデータ分離や作業用・保管用データの効率的運用が可能です。 カスタマイズメニューに無い構成はお気軽に弊社までお問い合わせ下さい。お客様のご要望に合わせて抜群のコストパフォーマンスと安定した利用環境をご提供します。
Intel Core Ultra を採用
GWS-IARGA-1Gは、Intel Core Ultra を搭載することで、AI時代に最適化された高性能環境を実現します。高性能コア(Pコア)と高効率コア(Eコア)がリアルタイムにタスクを解析し、負荷に応じて自動的に最適化。これにより、重いAI演算から軽いバックグラウンド処理まで、あらゆるワークロードで安定した処理能力を発揮します。さらに、AI専用エンジン NPU(Neural Processing Unit)により、生成AIや機械学習、データ解析といった高度なAIワークロードも効率的に実行可能です。内蔵の Intel Arc GPU がグラフィック処理を強化し、3Dレンダリングや科学計算、AI推論などもスムーズに処理できます。また高速メモリや PCIe Gen 5 SSD との連携により、大規模データの読み書きも高速化。これにより、AI開発や解析作業、シミュレーションなど、多様な業務において卓越した演算性能と安定性を提供します。
最大1基の高性能GPUを搭載
GWS-IARGA-1Gは、Blackwell GPU を搭載することで、GPU負荷の高い処理を高速かつ効率的に実行できます。高度な並列演算能力を持つ Blackwell アーキテクチャにより、AIモデルの学習や推論、大規模データ解析を迅速に処理。さらに、リアルタイムレンダリングや3Dグラフィックス計算も滑らかに実行でき、複雑なシミュレーションや高度な解析作業でも優れた演算性能を発揮します。Blackwell GPU は専用の高速メモリを備えており、大量データをGPU内で直接処理可能です。加えて、CPUやストレージからGPUへのデータ転送速度が向上しているため、GPUがデータ待ちになる時間を最小化。これにより、大規模データや複数のAIタスクも滞りなく処理でき、GPUの演算能力をフルに活かすことができます。AI開発、科学計算、生成AIモデルの推論など、多様なGPUワークロードにおいて、Blackwell GPU は高効率な並列演算能力と持続的安定動作を提供します。
効率化ストレージ設計
GWS-IARGA-1Gは、M.2 SSD をブートストレージに採用することで、OS やアプリケーションの起動時間を大幅に短縮し、システム全体の応答性と操作感を向上させます。さらに、データ用ストレージを2枚搭載することで、大容量データの管理や複数プロジェクトの同時運用が容易になり、柔軟なデータ整理と効率的なバックアップ運用を実現します。これにより、業務中の待機時間を最小化するとともに、解析作業やAI処理、シミュレーションなどの大量データを扱う高度な作業でも、安定かつスムーズなワークフローを維持できます。加えて、M.2 SSDとデータ用ストレージの組み合わせにより、ストレージ間のデータ移動や読み書きも高速化され、全体的な作業効率をさらに高めることが可能です。
DeepLearning開発環境「G-Suite」
G-Suiteは、これまでジーデップ・アドバンスが提供してきた「G-Works」の仕組み(Deep Learning の主要なフレームワークを、各世代のGPU に最適化してビルドしたソフトウェア群)を継承し、さらに発展させたOS ネイティブ環境+コンテナ環境のハイブリッドアプリケーションリソースマネージメントツールです。インターネット上のWeb サイトから様々なレシピやサポートツール群をダウンロードし、簡易解説書やチュートリアルを含むアプリケーション実行環境を構築することが可能です。Ubuntu 24.04に対応し、開発環境は miniforgeをベースとしています。各世代のGPU に最適化してビルドしたソフトウェア群に加え、OS ネイティブ環境+コンテナ環境をハイブリッドにサポートしています。
Ubuntu 22.04に対応する「G-Works4.0」を選択されたい場合は こちら からご覧ください。
大切なシステムを丸ごと守る、安心の完全バックアップIntegrated Backup搭載
GDEP Advance Integrated Backup(以下 Integrated Backup)はジーデップ・アドバンスが提供する コンピュータのシステム領域を完全バックアップするためのユーティリティツールです。 システムディスクのパーティション、ファイルシステムフォーマット、データ内容をすべて記録することが可能で、日付やコメントをつけてバックアップ内容を管理できます。ブートディスク消失時の復旧や、過去にバックアップしたの状態への復帰などが容易に行えます。 【動作条件】 ・システムディスク以外にデータディスクが一つ以上装備されている必要があります。 ・バックアップイメージはシステムディスク以外のディスクに独立して組み込まれます。 ・OSをシャットダウンさせたうえで、バックアップが入っているディスクからブートさせます。 ・バックアップデータは日付別に分類されて保存されます。
UNI-R5B はAMD B550 チップセットマザーボードに7nm製造プロセス ZEN3アーキテクチャーを採用したAMD Ryzen プロセッサーを搭載しています。最大8個のZen3コア、最大16MBのL3キャッシュ、DDR4-3200メモリに対応し、Radeonグラフィックによるパワフルなオンボードグラフィック機能を内蔵しています。CPUクーラーには世界屈指の空冷メーカー Noctua製「NH-U12S redux」を採用しており、メインストリーム系ながらハイエンドに迫る性能を発揮します。用途に応じ、内蔵グラフィックを使用したエントリーモデルからNVIDIA RTXシリーズを搭載したグラフィックWSモデルまで選択いただけるコストパフォーマンスに優れたモデルです。
AMD新APU Ryzen 5000Gシリーズ を採用
最大8コアを搭載したAMD Ryzen™ 5000シリーズ・デスクトップ・プロセッサーを利用することで、データの処理やコンテンツ制作を容易に遂行できるようになります。電力効率が高く、低発熱かつ静音な最先端の7nmテクノロジーで構築されたこのプロセッサーは、ミニ、スモール・フォームファクター、タワーなど、あらゆるサイズのデスクトップPCでハイパフォーマンスを実現します。
世界屈指の空冷最強メーカー Noctua製 「NH-U12S redux」を選択可能
メインストリーム系ながらハイエンドに迫る性能を発揮。ナローヒートシンクデザインを使用した、12cmファン搭載サイドフロー型のCPUクーラーです。
高品質な部品を採用し、安定性を重視したプロフェッショナルユーザー向けマザーボード
AMD B550チップセットマザーボードを採用。大型PWMヒートシンクと7W/mKのサーマルパッドがCPU温度を低く保ち、CPUの性能を高負荷時でも最大限に発揮します。ヘビーユーザーの要望に応える高い拡張性を備え、低遅延で高速なLANを搭載し、最新のストレージデバイスに対応しています。
UNI-R5B はAMD B550 チップセットマザーボードに7nm製造プロセス ZEN3アーキテクチャーを採用したAMD Ryzen プロセッサーを搭載しています。最大8個のZen3コア、最大16MBのL3キャッシュ、DDR4-3200メモリに対応し、Radeonグラフィックによるパワフルなオンボードグラフィック機能を内蔵しています。CPUクーラーには世界屈指の空冷メーカー Noctua製「NH-U12S redux」を採用しており、メインストリーム系ながらハイエンドに迫る性能を発揮します。用途に応じ、内蔵グラフィックを使用したエントリーモデルからNVIDIA RTXシリーズを搭載したグラフィックWSモデルまで選択いただけるコストパフォーマンスに優れたモデルです。
AMD新APU Ryzen 5000Gシリーズ を採用
最大8コアを搭載したAMD Ryzen™ 5000シリーズ・デスクトップ・プロセッサーを利用することで、データの処理やコンテンツ制作を容易に遂行できるようになります。電力効率が高く、低発熱かつ静音な最先端の7nmテクノロジーで構築されたこのプロセッサーは、ミニ、スモール・フォームファクター、タワーなど、あらゆるサイズのデスクトップPCでハイパフォーマンスを実現します。
世界屈指の空冷最強メーカー Noctua製 「NH-U12S redux」を選択可能
メインストリーム系ながらハイエンドに迫る性能を発揮。ナローヒートシンクデザインを使用した、12cmファン搭載サイドフロー型のCPUクーラーです。
高品質な部品を採用し、安定性を重視したプロフェッショナルユーザー向けマザーボード
AMD B550チップセットマザーボードを採用。大型PWMヒートシンクと7W/mKのサーマルパッドがCPU温度を低く保ち、CPUの性能を高負荷時でも最大限に発揮します。ヘビーユーザーの要望に応える高い拡張性を備え、低遅延で高速なLANを搭載し、最新のストレージデバイスに対応しています。
UNI-R5B はAMD B550 チップセットマザーボードに7nm製造プロセス ZEN3アーキテクチャーを採用したAMD Ryzen プロセッサーを搭載しています。最大8個のZen3コア、最大16MBのL3キャッシュ、DDR4-3200メモリに対応し、Radeonグラフィックによるパワフルなオンボードグラフィック機能を内蔵しています。CPUクーラーには世界屈指の空冷メーカー Noctua製「NH-U12S redux」を採用しており、メインストリーム系ながらハイエンドに迫る性能を発揮します。用途に応じ、内蔵グラフィックを使用したエントリーモデルからNVIDIA RTXシリーズを搭載したグラフィックWSモデルまで選択いただけるコストパフォーマンスに優れたモデルです。
AMD新APU Ryzen 5000Gシリーズ を採用
最大8コアを搭載したAMD Ryzen™ 5000シリーズ・デスクトップ・プロセッサーを利用することで、データの処理やコンテンツ制作を容易に遂行できるようになります。電力効率が高く、低発熱かつ静音な最先端の7nmテクノロジーで構築されたこのプロセッサーは、ミニ、スモール・フォームファクター、タワーなど、あらゆるサイズのデスクトップPCでハイパフォーマンスを実現します。
世界屈指の空冷最強メーカー Noctua製 「NH-U12S redux」を選択可能
メインストリーム系ながらハイエンドに迫る性能を発揮。ナローヒートシンクデザインを使用した、12cmファン搭載サイドフロー型のCPUクーラーです。
高品質な部品を採用し、安定性を重視したプロフェッショナルユーザー向けマザーボード
AMD B550チップセットマザーボードを採用。大型PWMヒートシンクと7W/mKのサーマルパッドがCPU温度を低く保ち、CPUの性能を高負荷時でも最大限に発揮します。ヘビーユーザーの要望に応える高い拡張性を備え、低遅延で高速なLANを搭載し、最新のストレージデバイスに対応しています。
DeepLearningSTATION II APは、当社独自のケース設計によりNVIDIA BlackwellアーキテクチャGPUであるRTX PRO 6000 Blackwell Max-Qシリーズを最大4基搭載可能なAIワークステーションです。CPUには開発コードネーム“Shimada Peak”、Zen 5アーキテクチャをベースに構築されたAMD Ryzen™ Threadripper™ PRO 9000シリーズを採用し、シングルソケットで最大96コアのメニーコア環境を実現します。最大5.4GHzの高クロックにより、軽度にスレッド化されたアプリケーションにおいても優れたコアパフォーマンスを発揮し、AMDメモリー・ガードによるリアルタイムの完全なシステムメモリー暗号化機能も備えています。また、最大144レーンのPCI Express 5.0により、理論値224GT/秒の広帯域でGPU間の高速通信を実現し、計算処理におけるボトルネックを大きく解消します。ストレージにはフロントアクセスが可能な2台の3.5インチHDDベイと、2.5インチSSDを最大2台内蔵でき、高い拡張性を備えています。GPUカードはNVIDIA BlackwellアーキテクチャGPUであるRTX PROシリーズ(2025年8月現在)に対応しており、LLMなどの複雑かつ大規模なAI学習にも対応可能な高性能ワークステーションです。さらに、AI開発・運用を効率化するG-Suiteに対応しており、環境構築や運用負荷を軽減しながら、導入後すぐにディープラーニング開発を開始することが可能です。ハードウェア性能を最大限に引き出し、研究・開発の生産性向上に貢献します。加えて、100V-15A入力の高性能電源を2基搭載したDual PSU構成により、合計2000W以上の電源供給が可能です。これにより、サーバールームなど特別な電源環境を必要とせず、一般的なオフィス環境においてもハイエンドなマルチGPU構成を実現します。さらに、オプションのラックマウントレールを装着することで、デスクサイド利用のみならず19インチラックへの搭載にも対応し、設置環境に応じた柔軟な運用が可能です。
カスタマイズメニューにない構成についても、お気軽にお問い合わせください。お客様のご要望に応じて、優れたコストパフォーマンスと安定した運用環境をご提供いたします。
NVIDIA RTX PRO 6000 Blackwell シリーズ製品比較レポート G-Suiteとは?できることをわかりやすく解説
当社独自設計 4GPU ワークステーションケース
DeepLearningSTATION II APは、当社独自のケース設計によりBlackwellアーキテクチャGPUであるRTX PRO 6000Blackwell Max-Qリーズを最大4基搭載可能なAIワークステーションです。CPUには開発コードネーム“Shimada Peak”「Zen 5」アーキテクチャをベースに構築されたAMD Ryzen™ Threadripper™ PRO 9000シリーズ を採用し、シングルソケットで最大96個のメニーコア環境を実現。最大5.4GHzのCPUクロックによって軽度にスレッド化されたアプリケーションのコアパフォーマンスを最適化し、AMDメモリー・ガードによるリアルタイムの完全なシステム・メモリー暗号化機能を備えます。また、144 レーンのPCI Express5.0により理論値224GT/秒の広帯域でGPU間の通信が可能となり、計算のボトルネックを大きく解消できます。ストレージにはフロントアクセスが可能な2台の3.5インチHDDベイと、2.5インチSSDが最大2台内蔵でき、高い拡張性を実現します。GPUカードはBlackWellアーキテクチャGPUであるRTX PROシリーズに対応しており(2025年8月現在)、LLMなどの複雑で大規模なAI学習でもご利用いただけるワークステーションです。
大容量ストレージを搭載
フロントアクセス可能な2基の3.5インチ 大容量HDDホットスワップベイを装備し、オプションで冗長化にも対応しています。内蔵ベイは2.5インチの高速SSDを最大で4基搭載可能で、システムとデータエリアを分けた運用が可能です。フロントベイはセキュリティーキーを標準装備しており、サイドパネルはワイヤーロックにも対応いる為、セキュリティー面も考慮した設計となっています。
デュアルパワーサプライユニット搭載
当社独自のケース設計により、内部に2つの電源ユニットを搭載出来る「Dual PSU設計」となっています。100Vx2入力で理論値2400Wの消費電力までに対応し、高性能CPUに加えてハイエンドGPUを最大で4枚まで搭載可能です。CPU冷却は液冷を採用し、可能な限り静粛性を維持することでデスクサイドでの利用を可能としました。
ラックマウントにも対応
オプションのラックマウントキットを装着することで、6.5Uサイズで19インチラックへの搭載が可能です。居室だけでは無くサーバールームやデータセンターなど設置場所を選びません。
LLMなどの大規模AI開発向けアプリケーションリソースマネージメントツール 「 G-Suite 」をプレインストール
G-Suiteは、これまでジーデップ・アドバンスが提供してきた「G-Works」の仕組み(Deep Learning の主要なフレームワークを、各世代のGPU に最適化してビルドしたソフトウェア群)を継承し、さらに発展させたOS ネイティブ環境+コンテナ環境のハイブリッドアプリケーションリソースマネージメントツールです。インターネット上のWeb サイトから様々なレシピやサポートツール群をダウンロードし、簡易解説書やチュートリアルを含むアプリケーション実行環境を構築することが可能です。Ubuntu 24.04に対応し、開発環境は miniforgeをベースとしています。各世代のGPU に最適化してビルドしたソフトウェア群に加え、OS ネイティブ環境+コンテナ環境をハイブリッドにサポートしています。
Ubuntu 22.04に対応する「G-Works4.0」を選択されたい場合は こちら からご覧ください。
DeepLearningSTATION II APは、当社独自のケース設計によりBlackwellアーキテクチャGPUであるRTX PRO 6000Blackwell Max-Qリーズを最大4基搭載可能なAIワークステーションです。CPUには開発コードネーム“Shimada Peak”「Zen 5」アーキテクチャをベースに構築されたAMD Ryzen™ Threadripper™ PRO 9000シリーズ を採用し、シングルソケットで最大96個のメニーコア環境を実現。最大5.4GHzのCPUクロックによって軽度にスレッド化されたアプリケーションのコアパフォーマンスを最適化し、AMDメモリー・ガードによるリアルタイムの完全なシステム・メモリー暗号化機能を備えます。また、144 レーンのPCI Express5.0により理論値224GT/秒の広帯域でGPU間の通信が可能となり、計算のボトルネックを大きく解消できます。ストレージにはフロントアクセスが可能な2台の3.5インチHDDベイと、2.5インチSSDが最大2台内蔵でき、高い拡張性を実現します。GPUカードはBlackWellアーキテクチャGPUであるRTX PROシリーズに対応しており(2025年8月現在)、LLMなどの複雑で大規模なAI学習でもご利用いただけるワークステーションです。さらに100V-15A入力の高性能電源を2基搭載したDual PSU構成によりトータル2000W以上の電源供給を可能にし、サーバールームなど特別な電源環境を備えていない居室でもハイエンドマルチGPUが利用可能なハードウェアスペックを誇ります。加えてオプションのラックマウントレールを装着することにより、デスクサイド利用のみならず19インチラックへの搭載も可能となっています。
カスタマイズメニューに無い構成はお気軽に弊社までお問い合わせ下さい。お客様のご要望に合わせて抜群のコストパフォーマンスと安定した利用環境をご提供します。
NVIDIA RTX PRO 6000 Blackwell シリーズ製品比較レポート
当社独自設計 4GPU ワークステーションケース
DeepLearningSTATION II APは、当社独自のケース設計によりBlackwellアーキテクチャGPUであるRTX PRO 6000Blackwell Max-Qリーズを最大4基搭載可能なAIワークステーションです。CPUには開発コードネーム“Shimada Peak”「Zen 5」アーキテクチャをベースに構築されたAMD Ryzen™ Threadripper™ PRO 9000シリーズ を採用し、シングルソケットで最大96個のメニーコア環境を実現。最大5.4GHzのCPUクロックによって軽度にスレッド化されたアプリケーションのコアパフォーマンスを最適化し、AMDメモリー・ガードによるリアルタイムの完全なシステム・メモリー暗号化機能を備えます。また、144 レーンのPCI Express5.0により理論値224GT/秒の広帯域でGPU間の通信が可能となり、計算のボトルネックを大きく解消できます。ストレージにはフロントアクセスが可能な2台の3.5インチHDDベイと、2.5インチSSDが最大2台内蔵でき、高い拡張性を実現します。GPUカードはBlackWellアーキテクチャGPUであるRTX PROシリーズに対応しており(2025年8月現在)、LLMなどの複雑で大規模なAI学習でもご利用いただけるワークステーションです。
大容量ストレージを搭載
フロントアクセス可能な2基の3.5インチ 大容量HDDホットスワップベイを装備し、オプションで冗長化にも対応しています。内蔵ベイは2.5インチの高速SSDを最大で4基搭載可能で、システムとデータエリアを分けた運用が可能です。フロントベイはセキュリティーキーを標準装備しており、サイドパネルはワイヤーロックにも対応いる為、セキュリティー面も考慮した設計となっています。
デュアルパワーサプライユニット搭載
当社独自のケース設計により、内部に2つの電源ユニットを搭載出来る「Dual PSU設計」となっています。100Vx2入力で理論値2400Wの消費電力までに対応し、高性能CPUに加えてハイエンドGPUを最大で4枚まで搭載可能です。CPU冷却は液冷を採用し、可能な限り静粛性を維持することでデスクサイドでの利用を可能としました。
ラックマウントにも対応
オプションのラックマウントキットを装着することで、6.5Uサイズで19インチラックへの搭載が可能です。居室だけでは無くサーバールームやデータセンターなど設置場所を選びません。
LLMなどの大規模AI開発向けアプリケーションリソースマネージメントツール 「 G-Suite 」をプレインストール
G-Suiteは、これまでジーデップ・アドバンスが提供してきた「G-Works」の仕組み(Deep Learning の主要なフレームワークを、各世代のGPU に最適化してビルドしたソフトウェア群)を継承し、さらに発展させたOS ネイティブ環境+コンテナ環境のハイブリッドアプリケーションリソースマネージメントツールです。インターネット上のWeb サイトから様々なレシピやサポートツール群をダウンロードし、簡易解説書やチュートリアルを含むアプリケーション実行環境を構築することが可能です。Ubuntu 24.04に対応し、開発環境は miniforgeをベースとしています。各世代のGPU に最適化してビルドしたソフトウェア群に加え、OS ネイティブ環境+コンテナ環境をハイブリッドにサポートしています。
Ubuntu 22.04に対応する「G-Works4.0」を選択されたい場合は こちら からご覧ください。
DeepLearningSTATION II APは、当社独自のケース設計によりBlackwellアーキテクチャGPUであるRTX PRO 6000Blackwell Max-Qリーズを最大4基搭載可能なAIワークステーションです。CPUには開発コードネーム“Shimada Peak”「Zen 5」アーキテクチャをベースに構築されたAMD Ryzen™ Threadripper™ PRO 9000シリーズ を採用し、シングルソケットで最大96個のメニーコア環境を実現。最大5.4GHzのCPUクロックによって軽度にスレッド化されたアプリケーションのコアパフォーマンスを最適化し、AMDメモリー・ガードによるリアルタイムの完全なシステム・メモリー暗号化機能を備えます。また、144 レーンのPCI Express5.0により理論値224GT/秒の広帯域でGPU間の通信が可能となり、計算のボトルネックを大きく解消できます。ストレージにはフロントアクセスが可能な2台の3.5インチHDDベイと、2.5インチSSDが最大2台内蔵でき、高い拡張性を実現します。GPUカードはBlackWellアーキテクチャGPUであるRTX PROシリーズに対応しており(2025年8月現在)、LLMなどの複雑で大規模なAI学習でもご利用いただけるワークステーションです。さらに100V-15A入力の高性能電源を2基搭載したDual PSU構成によりトータル2000W以上の電源供給を可能にし、サーバールームなど特別な電源環境を備えていない居室でもハイエンドマルチGPUが利用可能なハードウェアスペックを誇ります。加えてオプションのラックマウントレールを装着することにより、デスクサイド利用のみならず19インチラックへの搭載も可能となっています。
カスタマイズメニューに無い構成はお気軽に弊社までお問い合わせ下さい。お客様のご要望に合わせて抜群のコストパフォーマンスと安定した利用環境をご提供します。
NVIDIA RTX PRO 6000 Blackwell シリーズ製品比較レポート
当社独自設計 4GPU ワークステーションケース
DeepLearningSTATION II APは、当社独自のケース設計によりBlackwellアーキテクチャGPUであるRTX PRO 6000Blackwell Max-Qリーズを最大4基搭載可能なAIワークステーションです。CPUには開発コードネーム“Shimada Peak”「Zen 5」アーキテクチャをベースに構築されたAMD Ryzen™ Threadripper™ PRO 9000シリーズ を採用し、シングルソケットで最大96個のメニーコア環境を実現。最大5.4GHzのCPUクロックによって軽度にスレッド化されたアプリケーションのコアパフォーマンスを最適化し、AMDメモリー・ガードによるリアルタイムの完全なシステム・メモリー暗号化機能を備えます。また、144 レーンのPCI Express5.0により理論値224GT/秒の広帯域でGPU間の通信が可能となり、計算のボトルネックを大きく解消できます。ストレージにはフロントアクセスが可能な2台の3.5インチHDDベイと、2.5インチSSDが最大2台内蔵でき、高い拡張性を実現します。GPUカードはBlackWellアーキテクチャGPUであるRTX PROシリーズに対応しており(2025年8月現在)、LLMなどの複雑で大規模なAI学習でもご利用いただけるワークステーションです。
大容量ストレージを搭載
フロントアクセス可能な2基の3.5インチ 大容量HDDホットスワップベイを装備し、オプションで冗長化にも対応しています。内蔵ベイは2.5インチの高速SSDを最大で4基搭載可能で、システムとデータエリアを分けた運用が可能です。フロントベイはセキュリティーキーを標準装備しており、サイドパネルはワイヤーロックにも対応いる為、セキュリティー面も考慮した設計となっています。
デュアルパワーサプライユニット搭載
当社独自のケース設計により、内部に2つの電源ユニットを搭載出来る「Dual PSU設計」となっています。100Vx2入力で理論値2400Wの消費電力までに対応し、高性能CPUに加えてハイエンドGPUを最大で4枚まで搭載可能です。CPU冷却は液冷を採用し、可能な限り静粛性を維持することでデスクサイドでの利用を可能としました。
ラックマウントにも対応
オプションのラックマウントキットを装着することで、6.5Uサイズで19インチラックへの搭載が可能です。居室だけでは無くサーバールームやデータセンターなど設置場所を選びません。
LLMなどの大規模AI開発向けアプリケーションリソースマネージメントツール 「 G-Suite 」をプレインストール
G-Suiteは、これまでジーデップ・アドバンスが提供してきた「G-Works」の仕組み(Deep Learning の主要なフレームワークを、各世代のGPU に最適化してビルドしたソフトウェア群)を継承し、さらに発展させたOS ネイティブ環境+コンテナ環境のハイブリッドアプリケーションリソースマネージメントツールです。インターネット上のWeb サイトから様々なレシピやサポートツール群をダウンロードし、簡易解説書やチュートリアルを含むアプリケーション実行環境を構築することが可能です。Ubuntu 24.04に対応し、開発環境は miniforgeをベースとしています。各世代のGPU に最適化してビルドしたソフトウェア群に加え、OS ネイティブ環境+コンテナ環境をハイブリッドにサポートしています。
Ubuntu 22.04に対応する「G-Works4.0」を選択されたい場合は こちら からご覧ください。
UNI-R7X は、最新の AMD X870 チップセットマザーボード に、5nm 製造プロセスを採用した Zen 4 アーキテクチャ 第5世代 AMD Ryzen™ プロセッサー を搭載したモデルです。最大16コアの Zen 4 コア、最大 64MB の L3 キャッシュ、DDR5 メモリ対応により、高い処理能力と高速応答性を実現しています。高クロックの P-core 系 Zen 4 コアは、スレッド数の少ない 3D 設計や軽量レンダリングタスクに優れているだけでなく、最大16コア構成により、マルチスレッド・レンダリングやリアリティキャプチャなどの重い処理にも柔軟に対応できるバランスの取れた性能を発揮します。さらに、統合 RDNA2 グラフィックス を備え、AVX-512 命令セット、PCIe 5.0 をサポート。X870 チップセット経由では USB4(最大40Gbps) をはじめとする次世代 I/O に対応し、高速なデータ転送や外部デバイスとの高い互換性を提供します。すべてをこなすデスクトップ・プロセッサーとして、卓越したシングルスレッドおよびマルチスレッド性能を両立し、クリエイティブ制作から高度な演算処理まで、幅広いワークフローで最大限のパフォーマンスを発揮します。次世代のデスクトップ PC がもたらすパワーを、ぜひご体感ください。
第5世代(ZEN 4)AMD Ryzen プロセッサー搭載を搭載
最大16コア32スレッドのZen4コア、最大5.7GHzのブーストクロック、最大80MBキャッシュを備えたAMD Ryzen 7000 シリーズ・プロセッサーは先を行く性能を発揮します。時間を節約できる演算能力で、クリエイターの創作活動を支援します。タスクの種類を問わず、PCIe 5.0のスピードとストレージを備え、最大32個のプロセッシング・スレッドと専用のビデオ・アクセラレーターを搭載したこのプロセッサーがあれば、より高速に作業を遂行することができます。
次世代ワークステーションを支える AMD X870 マザーボード
UNI-R7Xの マザーボードは最新の AMD X870 チップセットを採用し、科学計算やシミュレーション用途で求められる高い計算負荷にも耐えるワークステーション基盤を提供します。 PCIe Gen5、DDR5高速メモリ、USB4などの先進的なインターフェースにより、大容量データの高速処理や、GPUアクセラレーションを活用した数値解析・物理シミュレーションを強力にサポートします。 さらに、業界初のクイックリリース式M.2ヒートシンクと大型アルミ合金ヒートシンクを備え、長時間連続稼働が必要なモデリング作業や計算ジョブでも安定したスループットを維持。 インテリジェント冷却設計により、熱負荷の高いストレージや拡張カード使用時でも信頼性の高い運用が可能です。 高帯域ネットワーク(Wi-Fi 7 / 2.5GbE)と堅牢な電源設計を組み合わせ、研究開発・工学分野のワークステーションに求められる安定性・拡張性を両立しています。
最大128GBまで搭載可能な広帯域4800MHz DDR5メモリー
メモリはDDR-5規格広帯域 4800MHzモジュールをDual-Cannelで実装、合計4つのメモリスロットを確保しております。マザーボード上には強化DIMMスロッが表面実装されており、より優れた物理的強度とより安定したメモリ信号を実現します。
PCI-Express 5.0 に対応
最新のPCI Express 5.0規格に対応し、前世代の2倍となる128 Gb/秒の転送速度に対応します。この驚異的な帯域幅により、将来の超高速SSDの性能を最大限に引き出すことができます。
最大5基のストレージベイを搭載
HDD ケージシステムには 3.5 インチまたは 2.5 インチドライブを最大 5台まで設置可能、従来よりも更に優れた拡張性を実現。ユーザー個人の好みに応じてケースレイアウトを変更可能です。
UNI-R7X はAMD X670E チップセットマザーボードに5nm製造プロセス ZEN4アーキテクチャーを採用した第5世代(ZEN 4)AMD Ryzen プロセッサーを搭載しています。最大16個のZen4コア、最大64MBのL3キャッシュ、DDR5-4800メモリ対応、統合RDNA2グラフィックス、AVX512インストラクションサポート、高性能105W+および65Wソリューションをターゲット、PCIe5.0対応、チップセット経由で最大20GbpsのUSBType-Cに対応、等々。デスクトップPCを次世代に導く性能をご体感ください。
第5世代(ZEN 4)AMD Ryzen プロセッサー搭載を搭載
最大16コア32スレッドのZen4コア、最大5.7GHzのブーストクロック、最大80MBキャッシュを備えたAMD Ryzen 7000 シリーズ・プロセッサーは先を行く性能を発揮します。時間を節約できる演算能力で、クリエイターの創作活動を支援します。タスクの種類を問わず、PCIe 5.0のスピードとストレージを備え、最大32個のプロセッシング・スレッドと専用のビデオ・アクセラレーターを搭載したこのプロセッサーがあれば、より高速に作業を遂行することができます。
堅牢なコンポーネントを装備し、安定性を重視したマザーボード
AMD X670Eチップセットマザーボードを採用。それぞれのフェーズの電流と温度の監視向けに最適化されているので、RyzenCPU に円滑かつ安定した電源を供給し、性能を向上させて、低温と優れたエネルギー効率をお届けします。
最大128GBまで搭載可能な広帯域4800MHz DDR5メモリー
メモリはDDR-5規格広帯域 4800MHzモジュールをDual-Cannelで実装、合計4つのメモリスロットを確保しております。マザーボード上には強化DIMMスロッが表面実装されており、より優れた物理的強度とより安定したメモリ信号を実現します。
PCI-Express 5.0 に対応
最新のPCI Express 5.0規格に対応し、前世代の2倍となる128 Gb/秒の転送速度に対応します。この驚異的な帯域幅により、将来の超高速SSDの性能を最大限に引き出すことができます。
最大5基のストレージベイを搭載
HDD ケージシステムには 3.5 インチまたは 2.5 インチドライブを最大 5台まで設置可能、従来よりも更に優れた拡張性を実現。ユーザー個人の好みに応じてケースレイアウトを変更可能です。
UNI-R7X はAMD X670E チップセットマザーボードに5nm製造プロセス ZEN4アーキテクチャーを採用した第5世代(ZEN 4)AMD Ryzen プロセッサーを搭載しています。最大16個のZen4コア、最大64MBのL3キャッシュ、DDR5-4800メモリ対応、統合RDNA2グラフィックス、AVX512インストラクションサポート、高性能105W+および65Wソリューションをターゲット、PCIe5.0対応、チップセット経由で最大20GbpsのUSBType-Cに対応、等々。デスクトップPCを次世代に導く性能をご体感ください。
第5世代(ZEN 4)AMD Ryzen プロセッサー搭載を搭載
最大16コア32スレッドのZen4コア、最大5.7GHzのブーストクロック、最大80MBキャッシュを備えたAMD Ryzen 7000 シリーズ・プロセッサーは先を行く性能を発揮します。時間を節約できる演算能力で、クリエイターの創作活動を支援します。タスクの種類を問わず、PCIe 5.0のスピードとストレージを備え、最大32個のプロセッシング・スレッドと専用のビデオ・アクセラレーターを搭載したこのプロセッサーがあれば、より高速に作業を遂行することができます。
堅牢なコンポーネントを装備し、安定性を重視したマザーボード
AMD X670Eチップセットマザーボードを採用。それぞれのフェーズの電流と温度の監視向けに最適化されているので、RyzenCPU に円滑かつ安定した電源を供給し、性能を向上させて、低温と優れたエネルギー効率をお届けします。
最大128GBまで搭載可能な広帯域4800MHz DDR5メモリー
メモリはDDR-5規格広帯域 4800MHzモジュールをDual-Cannelで実装、合計4つのメモリスロットを確保しております。マザーボード上には強化DIMMスロッが表面実装されており、より優れた物理的強度とより安定したメモリ信号を実現します。
PCI-Express 5.0 に対応
最新のPCI Express 5.0規格に対応し、前世代の2倍となる128 Gb/秒の転送速度に対応します。この驚異的な帯域幅により、将来の超高速SSDの性能を最大限に引き出すことができます。
最大5基のストレージベイを搭載
HDD ケージシステムには 3.5 インチまたは 2.5 インチドライブを最大 5台まで設置可能、従来よりも更に優れた拡張性を実現。ユーザー個人の好みに応じてケースレイアウトを変更可能です。
DeepLearning BOXⅢはNVIDIA Blackwell アーキテクチャーGPUであるRTX PRO 6000 Blackwellシリーズを最大3基搭載可能なGPUディープラーニングワークステーションです。CPUにはインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids) W3500シリーズを採用し、シングルソケットで最大 60 個のメニーコア環境を実現。インテル スマートキャッシュはキャッシュとメモリー間のデータ交換の高速化によるレイテンシーを低減させます。また、最大 112 レーンの PCI Express 5.0 を備え、最大 224GT/ 秒の広帯域でGPU間を接続することで計算のボトルネックを大きく解消することが期待できます。GPUカードはRTX PRO 6000 Blackwellシリーズに対応しており、LLMなどの複雑で大規模なAI学習でもご利用いただけるワークステーションです。さらに100V-15A入力の高性能電源を2基搭載したDual PSU構成でトータル2000W以上の電源供給を可能にし、サーバールームなど特別な電源環境を備えていない居室でもハイエンドマルチGPUが利用可能なハードウェアスペックを誇ります。
カスタマイズメニューに無い構成はお気軽に弊社までお問い合わせ下さい。お客様のご要望に合わせて抜群のコストパフォーマンスと安定した利用環境をご提供します。
NVIDIA RTX PRO 6000 Blackwell シリーズ製品比較レポート G-Suiteとは?できることをわかりやすく解説
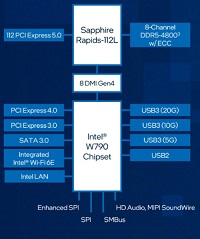
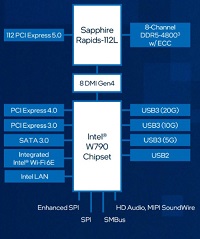
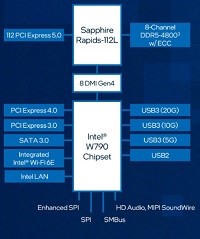
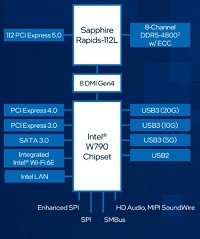
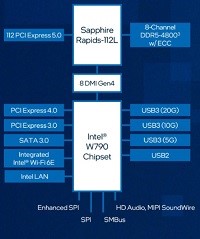
インテル Xeon W プロセッサー 搭載
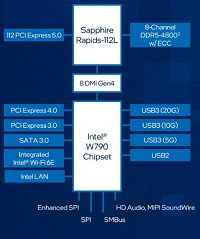
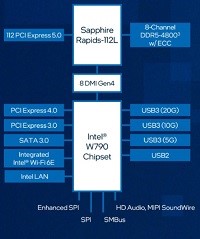
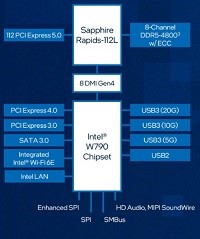
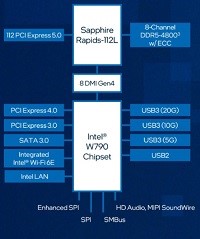
最新の インテル® Xeon® W プロセッサー・ファミリー(開発コード Sapphire Rapids)は、さまざまなクリエイターのために設計されています。インテル® Xeon® W-3400/2400 プロセッサー搭載のプラットフォームは、VFX、3D レンダリング、複雑な 3D CAD、および AI 開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。また。最新のDeeplearningBOXIIIは液体冷却ユニットにより冷却が行われていることで、安全で静音な環境で利用することができます。
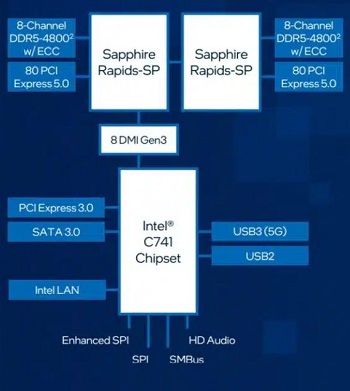
強化されたプラットフォーム
最新のDeeplearning BOXは、インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し、生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルな複雑なコンピューティングの需要に応えることが簡単にできます。
ウルトラハイエンドGPUカードを 最大3枚搭載可能
コアパーツであるGPUは、最大3枚フル帯域で搭載が可能。PCI Expressの最新世代のPCI Express 5.0レーンに対応。
DeepLearning開発環境「G-Suite」
G-Suiteは、これまでジーデップ・アドバンスが提供してきた「G-Works」の仕組み(Deep Learning の主要なフレームワークを、各世代のGPU に最適化してビルドしたソフトウェア群)を継承し、さらに発展させたOS ネイティブ環境+コンテナ環境のハイブリッドアプリケーションリソースマネージメントツールです。インターネット上のWeb サイトから様々なレシピやサポートツール群をダウンロードし、簡易解説書やチュートリアルを含むアプリケーション実行環境を構築することが可能です。Ubuntu 24.04に対応し、開発環境は miniforgeをベースとしています。各世代のGPU に最適化してビルドしたソフトウェア群に加え、OS ネイティブ環境+コンテナ環境をハイブリッドにサポートしています。
Ubuntu 22.04に対応する「G-Works4.0」を選択されたい場合は こちら からご覧ください。
大切なシステムを丸ごと守る、安心の完全バックアップIntegrated Backup搭載
GDEP Advance Integrated Backup(以下 Integrated Backup)はジーデップ・アドバンスが提供する コンピュータのシステム領域を完全バックアップするためのユーティリティツールです。 システムディスクのパーティション、ファイルシステムフォーマット、データ内容をすべて記録することが可能で、日付やコメントをつけてバックアップ内容を管理できます。ブートディスク消失時の復旧や、過去にバックアップしたの状態への復帰などが容易に行えます。 【動作条件】 ・システムディスク以外にデータディスクが一つ以上装備されている必要があります。 ・バックアップイメージはシステムディスク以外のディスクに独立して組み込まれます。 ・OSをシャットダウンさせたうえで、バックアップが入っているディスクからブートさせます。 ・バックアップデータは日付別に分類されて保存されます。
DeepLearning BOXIII はインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids) W3400シリーズを搭載した GPUディープラーニングワークステーションです。「G-Works 4.0」をインストール
インテル Xeon W プロセッサー 搭載
最新の インテル® Xeon® W プロセッサー・ファミリー(開発コード Sapphire Rapids)は、さまざまなクリエイターのために設計されています。インテル® Xeon® W-3400/2400 プロセッサー搭載のプラットフォームは、VFX、3D レンダリング、複雑な 3D CAD、および AI 開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。また。最新のDeeplearningBOXIIIは液体冷却ユニットにより冷却が行われていることで、安全で静音な環境で利用することができます。
強化されたプラットフォーム
最新のDeeplearning BOXは、インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し、生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルな複雑なコンピューティングの需要に応えることが簡単にできます。
ウルトラハイエンドGPUカードを 最大4枚を搭載可能
コアパーツであるGPUは、最大4枚フル帯域で搭載が可能。PCI Expressの最新世代のPCI Express 5.0レーンに対応。
バージョンアップされたDeepLearning開発環境「G-Works4.0」
新しいG-Works 4.0はWandBによる課題の可視化に加えて、Ubuntu 22.04 LTSに対応し、業界標準となっている仮想環境Dockerに加え、AI/HPCアプリケーションに適したSingularity、およびワークロードマネジメント用にSlurmをインストールしました。また、NVIDIA社が提供するNVIDIA GPU Cloud (NGC)の内容を検索できるngcスクリプトも配置してありますので、コマンドラインから、利用可能なDocker Imageを簡単に探し出すことができ利便性を高めています。
G-Worksの詳細はこちら からご覧ください。
DeepLearning BOXIII はインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids) W3400シリーズを搭載した GPUディープラーニングワークステーションです。LLM などの複雑で大規模なAI学習でも利用できる、最新のAdaLovelaceアーキテクチャGPUであるRTX Adaシリーズを搭載したモデルをご用意。100V-15A入力の高性能電源を2基搭載したDual PSU構成でトータル2000W以上の電源供給を可能にしており、サーバールームなど特別な電源環境を備えていない居室でのハイエンドマルチGPUが利用可能なハードウェアスペックを誇ります。「G-Works 4.0」をインストール
インテル Xeon W プロセッサー 搭載
最新の インテル® Xeon® W プロセッサー・ファミリー(開発コード Sapphire Rapids)は、さまざまなクリエイターのために設計されています。インテル® Xeon® W-3400/2400 プロセッサー搭載のプラットフォームは、VFX、3D レンダリング、複雑な 3D CAD、および AI 開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。また。最新のDeeplearningBOXIIIは液体冷却ユニットにより冷却が行われていることで、安全で静音な環境で利用することができます。
強化されたプラットフォーム
最新のDeeplearning BOXは、インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し、生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルな複雑なコンピューティングの需要に応えることが簡単にできます。
ウルトラハイエンドGPUカードを 最大4枚を搭載可能
コアパーツであるGPUは、最大4枚フル帯域で搭載が可能。PCI Expressの最新世代のPCI Express 5.0レーンに対応。
バージョンアップされたDeepLearning開発環境「G-Works4.0」
新しいG-Works 4.0はWandBによる課題の可視化に加えて、Ubuntu 22.04 LTSに対応し、業界標準となっている仮想環境Dockerに加え、AI/HPCアプリケーションに適したSingularity、およびワークロードマネジメント用にSlurmをインストールしました。また、NVIDIA社が提供するNVIDIA GPU Cloud (NGC)の内容を検索できるngcスクリプトも配置してありますので、コマンドラインから、利用可能なDocker Imageを簡単に探し出すことができ利便性を高めています。
G-Worksの詳細はこちら からご覧ください。
GWS-ISAGA-2Gはインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids) Wシリーズを搭載したデスクサイドGPUワークステーションです。Xeon Wの採用によりシングルソケットでメニーコア環境を実現。インテル スマートキャッシュはキャッシュとメモリー間のデータ交換の高速化によるレイテンシーを低減させます。また、PCI Express 5.0 を備え、理論値32GT/sの広帯域なインターフェースで Microsoft DirectStorageなどのデータ転送技術とNVIDIA Blackwell アーキテクチャーのハイエンドGPUを最大2基まで最適に動作させることが可能です。さらに最大 224GT/ 秒の広帯域でGPU間を接続することで計算のボトルネックを大きく解消することが期待できます。GPUカードはNVIDIA Blackwell アーキテクチャーに対応。ストレージには高速なM.2NVMe1台と4台の3.5インチHDDが搭載可能です。GPU演算に加えて、高速演算やシミュレーション、グラフィック作業などCPUパワーを必要とする作業に満足のいくパフォーマンスを提供できるモデルです。
カスタマイズメニューに無い構成はお気軽に弊社までお問い合わせ下さい。お客様のご要望に合わせて抜群のコストパフォーマンスと安定した利用環境をご提供します。
NVIDIA RTX PRO 6000 Blackwell シリーズ製品比較レポート
NVIDIA Blackwell アーキテクチャーGPUカードが搭載可能
NVIDIA Blackwell アーキテクチャは、AI、レイトレーシング、ニューラルグラフィックス技術を組み合わせており、パフォーマンスとメモリの大幅な向上を実現します。これにより、先進的なクリエイティブ、設計、エンジニアリングワークフローを推進します。
インテル Xeon W プロセッサー 搭載
最新の インテル® Xeon® W プロセッサー・ファミリー(開発コード Sapphire Rapids)はさまざまなクリエイターのために設計されています。インテル® Xeon® W-3400/2400 プロセッサー搭載のプラットフォームは、VFX、3D レンダリング、複雑な 3D CAD、および AI 開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。また、最新のGSW-W9/4G は液体冷却ユニットにより冷却が行われていることで、安全で静音な環境で利用することができます。
強化されたプラットフォーム
インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルな複雑なコンピューティングの需要に応えることが簡単にできます。
安定度抜群の高効率電源
採用されている電源は高品質のDC-DCコンバータを使用した大容量高効率ユニットです。100V環境で1200W の容量を実現しワークステーション用途はもちろん、サーバーレベルの要求仕様も満たす品質と高いTDPを要求する演算用GPUカードも安定した性能を発揮出来る余裕のマージン設計です。
大切なシステムを丸ごと守る、安心の完全バックアップIntegrated Backup搭載
GDEP Advance Integrated Backup(以下 Integrated Backup)はジーデップ・アドバンスが提供する コンピュータのシステム領域を完全バックアップするためのユーティリティツールです。 システムディスクのパーティション、ファイルシステムフォーマット、データ内容をすべて記録することが可能で、日付やコメントをつけてバックアップ内容を管理できます。ブートディスク消失時の復旧や、過去にバックアップしたの状態への復帰などが容易に行えます。 【動作条件】 ・システムディスク以外にデータディスクが一つ以上装備されている必要があります。 ・バックアップイメージはシステムディスク以外のディスクに独立して組み込まれます。 ・OSをシャットダウンさせたうえで、バックアップが入っているディスクからブートさせます。 ・バックアップデータは日付別に分類されて保存されます。
GWS-ISAGA-2Gはインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids) Wシリーズを搭載したデスクサイドGPUワークステーションです。最新のXeon Wの採用によりシングルソケットでメニーコア環境を実現。インテル ターボ・ブースト・マックス・テクノロジー 3.0 は 最大 4.8GHz の CPUクロックによって軽度にスレッド化されたアプリケーションのコアパフォーマンスを最適化し、インテル スマートキャッシュはキャッシュとメモリー間のデータ交換の高速化によるレイテンシーを低減させます。
NVIDIA Ada Lovelace アーキテクチャ 世代 TDP 450W クラスGPUカードが搭載可能
第 4 世代 Tensor コアにより、新しいFP8 Transformerエンジンを使用して驚異的に速い最大 5 倍のスループットの向上と、1.4 Tensor-petaFLOPS の性能を実現します。Ada の第 3 世代 RT コアは、レイ-トライアングル交差のスループットが 2 倍になり、RT-TFLOP 性能が 2 倍以上向上します。これらプロフェッショナル グラフィックス、AI、コンピューティング性能を実現するために設計されております。
インテル Xeon W プロセッサー 搭載
最新の インテル® Xeon® W プロセッサー・ファミリー(開発コード Sapphire Rapids)はさまざまなクリエイターのために設計されています。インテル® Xeon® W-3400/2400 プロセッサー搭載のプラットフォームは、VFX、3D レンダリング、複雑な 3D CAD、および AI 開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。また、最新のDeeplearningBOXIIIは液体冷却ユニットにより冷却が行われていることで、安全で静音な環境で利用することができます。
強化されたプラットフォーム
インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルな複雑なコンピューティングの需要に応えることが簡単にできます。
安定度抜群の高効率電源
採用されている電源は高品質のDC-DCコンバータを使用した大容量高効率ユニットです。100V環境で1200W の容量を実現しワークステーション用途はもちろん、サーバーレベルの要求仕様も満たす品質と高いTDPを要求する演算用GPUカードも安定した性能を発揮出来る余裕のマージン設計です。
GWS-ISAGA-2Gはインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids) Wシリーズを搭載したデスクサイドGPUワークステーションです。最新のXeon Wの採用によりシングルソケットでメニーコア環境を実現。インテル ターボ・ブースト・マックス・テクノロジー 3.0 は 最大 4.8GHz の CPUクロックによって軽度にスレッド化されたアプリケーションのコアパフォーマンスを最適化し、インテル スマートキャッシュはキャッシュとメモリー間のデータ交換の高速化によるレイテンシーを低減させます。
NVIDIA Ada Lovelace アーキテクチャ 世代 TDP 450W クラスGPUカードが搭載可能
第 4 世代 Tensor コアにより、新しいFP8 Transformerエンジンを使用して驚異的に速い最大 5 倍のスループットの向上と、1.4 Tensor-petaFLOPS の性能を実現します。Ada の第 3 世代 RT コアは、レイ-トライアングル交差のスループットが 2 倍になり、RT-TFLOP 性能が 2 倍以上向上します。これらプロフェッショナル グラフィックス、AI、コンピューティング性能を実現するために設計されております。
インテル Xeon W プロセッサー 搭載
最新の インテル® Xeon® W プロセッサー・ファミリー(開発コード Sapphire Rapids)はさまざまなクリエイターのために設計されています。インテル® Xeon® W-3400/2400 プロセッサー搭載のプラットフォームは、VFX、3D レンダリング、複雑な 3D CAD、および AI 開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。また、最新のDeeplearningBOXIIIは液体冷却ユニットにより冷却が行われていることで、安全で静音な環境で利用することができます。
強化されたプラットフォーム
インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルな複雑なコンピューティングの需要に応えることが簡単にできます。
安定度抜群の高効率電源
採用されている電源は高品質のDC-DCコンバータを使用した大容量高効率ユニットです。100V環境で1200W の容量を実現しワークステーション用途はもちろん、サーバーレベルの要求仕様も満たす品質と高いTDPを要求する演算用GPUカードも安定した性能を発揮出来る余裕のマージン設計です。
ローカルRAGスターターBOXは、LLMアプリケーションの開発や高速化など数々のAI開発実績を誇る株式会社Ridge-iと共同開発したQ&Aサポートチケット付ワークステーションです。
セキュアなローカル環境
ローカルRAGスターターBOXは、クローズドな環境で機密性の高い自社データを活用したLLMの構築を行う開発者向けにソフトウェア環境構築済みのオンプレミスの開発向けモデルです。開発中のデータをローカル環境内に留め外部へ持ち出さないため、情報漏洩リスクを最小化します。そのため厳格なセキュリティポリシーが求められる業種でも機密性、正確性、リアルタイム性が担保された、より精度の高いLLMの構築を行うことが可能になります。
短期導入・即運用可能
ローカルRAGスターターBOXは、LLM/RAG開発に適したハードウェアシステム構成に加え、開発環境には Dify OpenWebUIと Ollama Xinference を実装したワークステーションです。 AIモデルには2025年1月7日に公開された最新のMicrosoft Phi-4、2024年公開のLlama 3.1など複数のモデルをプリインストールしています。そのため、届いたその日から最短時間で基本機能が稼働し、迅速に業務への導入が可能です。
安心のQ&Aチケット
初期セットアップ済みのLLM/RAG開発環境の操作方法について不明な点は、、LLMアプリケーションの開発や高速化など数々のAI開発実績を誇るRidge-i社のQ&Aチケットが付属したワークステーションとなり、Q&Aサポートを受けながらスムーズな導入が可能です。
抜群のコストパフォーマンス
ローカルRAGスターターBOXは、お客様のビジネスへのAI活用がスムーズにスタートできるよう、エントリー、スタンダード、ハイスペックの3タイプのモデルを展開したワークステーションです。ハードウェア構成として NVIDIA Ada Lovelaceアーキテクチャを採用したRTX Adaシリーズを搭載。最大48GB のGDDR6メモリと広帯域なNVLINKを組み合わせることにより高いAI学習性能及び推論性能を実現します。また、ソフトウェア環境構築は LLM/RAGの開発環境のプリインストールだけではなく、各モデルにQ&Aチケットが3回分付帯して1,998,000円(税別・送料別)から始められるお求めやすい価格でご用意しました。
他に類を見ない拡張性と柔軟性
ローカルRAGスターターBOXは、エントリー、スタンダード、ハイスペック、3タイプのモデルに対して、お客様のご予算に合わせてGPUカードの交換や増設などにご予算に合わせたカスタマイズが可能なワークステーションです。また導入後のGPUやストレージの追加なども柔軟に対応しますので、必要なタイミングでマシンパフォーマンスの向上が可能となります。また、ハードのみならず、PoC推進のためにAIのプロフェッショナルであるRidge-i社による本格的なコンサルテーションや開発をセット提供(別途有償)できるよう柔軟なオプションと提供形態をご用意しています。まずはお気軽にご相談下さい。
※PoCでの利用シーンを想定して1マシンを1ユーザ(1グループ)で占有してご利用いただく開発環境となります。
ローカルRAGスターターBOXは、LLMアプリケーションの開発や高速化など数々のAI開発実績を誇る株式会社Ridge-iと共同開発したQ&Aサポートチケット付ワークステーションです。
セキュアなローカル環境
ローカルRAGスターターBOXは、クローズドな環境で機密性の高い自社データを活用したLLMの構築を行う開発者向けにソフトウェア環境構築済みのオンプレミスの開発向けモデルです。開発中のデータをローカル環境内に留め外部へ持ち出さないため、情報漏洩リスクを最小化します。そのため厳格なセキュリティポリシーが求められる業種でも機密性、正確性、リアルタイム性が担保された、より精度の高いLLMの構築を行うことが可能になります。
短期導入・即運用可能
ローカルRAGスターターBOXは、LLM/RAG開発に適したハードウェアシステム構成に加え、開発環境には Dify OpenWebUIと Ollama Xinference を実装したワークステーションです。 AIモデルには2025年1月7日に公開された最新のMicrosoft Phi-4、2024年公開のLlama 3.1など複数のモデルをプリインストールしています。そのため、届いたその日から最短時間で基本機能が稼働し、迅速に業務への導入が可能です。
安心のQ&Aチケット
初期セットアップ済みのLLM/RAG開発環境の操作方法について不明な点は、、LLMアプリケーションの開発や高速化など数々のAI開発実績を誇るRidge-i社のQ&Aチケットが付属したワークステーションとなり、Q&Aサポートを受けながらスムーズな導入が可能です。
抜群のコストパフォーマンス
ローカルRAGスターターBOXは、お客様のビジネスへのAI活用がスムーズにスタートできるよう、エントリー、スタンダード、ハイスペックの3タイプのモデルを展開したワークステーションです。ハードウェア構成として NVIDIA Ada Lovelaceアーキテクチャを採用したRTX Adaシリーズを搭載。最大48GB のGDDR6メモリと広帯域なNVLINKを組み合わせることにより高いAI学習性能及び推論性能を実現します。また、ソフトウェア環境構築は LLM/RAGの開発環境のプリインストールだけではなく、各モデルにQ&Aチケットが3回分付帯して1,998,000円(税別・送料別)から始められるお求めやすい価格でご用意しました。
他に類を見ない拡張性と柔軟性
ローカルRAGスターターBOXは、エントリー、スタンダード、ハイスペック、3タイプのモデルに対して、お客様のご予算に合わせてGPUカードの交換や増設などにご予算に合わせたカスタマイズが可能なワークステーションです。また導入後のGPUやストレージの追加なども柔軟に対応しますので、必要なタイミングでマシンパフォーマンスの向上が可能となります。また、ハードのみならず、PoC推進のためにAIのプロフェッショナルであるRidge-i社による本格的なコンサルテーションや開発をセット提供(別途有償)できるよう柔軟なオプションと提供形態をご用意しています。まずはお気軽にご相談下さい。
※PoCでの利用シーンを想定して1マシンを1ユーザ(1グループ)で占有してご利用いただく開発環境となります。
ローカルRAGスターターBOXは、LLMアプリケーションの開発や高速化など数々のAI開発実績を誇る株式会社Ridge-iと共同開発したQ&Aサポートチケット付ワークステーションです。
セキュアなローカル環境
ローカルRAGスターターBOXは、クローズドな環境で機密性の高い自社データを活用したLLMの構築を行う開発者向けにソフトウェア環境構築済みのオンプレミスの開発向けモデルです。開発中のデータをローカル環境内に留め外部へ持ち出さないため、情報漏洩リスクを最小化します。そのため厳格なセキュリティポリシーが求められる業種でも機密性、正確性、リアルタイム性が担保された、より精度の高いLLMの構築を行うことが可能になります。
短期導入・即運用可能
ローカルRAGスターターBOXは、LLM/RAG開発に適したハードウェアシステム構成に加え、開発環境には Dify OpenWebUIと Ollama Xinference を実装したワークステーションです。 AIモデルには2025年1月7日に公開された最新のMicrosoft Phi-4、2024年公開のLlama 3.1など複数のモデルをプリインストールしています。そのため、届いたその日から最短時間で基本機能が稼働し、迅速に業務への導入が可能です。
安心のQ&Aチケット
初期セットアップ済みのLLM/RAG開発環境の操作方法について不明な点は、、LLMアプリケーションの開発や高速化など数々のAI開発実績を誇るRidge-i社のQ&Aチケットが付属したワークステーションとなり、Q&Aサポートを受けながらスムーズな導入が可能です。
抜群のコストパフォーマンス
ローカルRAGスターターBOXは、お客様のビジネスへのAI活用がスムーズにスタートできるよう、エントリー、スタンダード、ハイスペックの3タイプのモデルを展開したワークステーションです。ハードウェア構成として NVIDIA Ada Lovelaceアーキテクチャを採用したRTX Adaシリーズを搭載。最大48GB のGDDR6メモリと広帯域なNVLINKを組み合わせることにより高いAI学習性能及び推論性能を実現します。また、ソフトウェア環境構築は LLM/RAGの開発環境のプリインストールだけではなく、各モデルにQ&Aチケットが3回分付帯して1,998,000円(税別・送料別)から始められるお求めやすい価格でご用意しました。
他に類を見ない拡張性と柔軟性
ローカルRAGスターターBOXは、エントリー、スタンダード、ハイスペック、3タイプのモデルに対して、お客様のご予算に合わせてGPUカードの交換や増設などにご予算に合わせたカスタマイズが可能なワークステーションです。また導入後のGPUやストレージの追加なども柔軟に対応しますので、必要なタイミングでマシンパフォーマンスの向上が可能となります。また、ハードのみならず、PoC推進のためにAIのプロフェッショナルであるRidge-i社による本格的なコンサルテーションや開発をセット提供(別途有償)できるよう柔軟なオプションと提供形態をご用意しています。まずはお気軽にご相談下さい。
※PoCでの利用シーンを想定して1マシンを1ユーザ(1グループ)で占有してご利用いただく開発環境となります。
DeepLearningSTATION II は、当社独自のケース設計によりNVIDIA BlackwellアーキテクチャーGPUであるRTX PRO 6000 Blackwellシリーズを最大4基搭載可能なAIワークステーションです。CPUにはインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids)W3500シリーズを採用し、シングルソケットで最大60コアのメニーコア環境を実現します。インテル スマートキャッシュによりキャッシュとメモリー間のデータ交換を高速化し、レイテンシーを低減します。また、最大112レーンのPCI Express 5.0を備え、最大224GT/秒の広帯域でGPU間を接続することで、計算処理におけるボトルネックの大幅な解消が期待できます。ストレージにはフロントアクセスが可能な2台の3.5インチHDDベイと、2.5インチSSDを最大4台内蔵でき、高い拡張性を実現します。GPUカードはNVIDIA BlackwellアーキテクチャーGPUであるRTX PRO 6000 Blackwellシリーズに対応しており、LLMなどの複雑かつ大規模なAI学習にも対応可能な高性能ワークステーションです。さらに、AI開発・運用を効率化するG-Suiteに対応しており、環境構築や運用負荷を軽減しながら、導入後すぐにディープラーニング開発を開始することが可能です。ハードウェア性能を最大限に引き出し、研究・開発の生産性向上に貢献します。加えて、100V-15A入力の高性能電源を2基搭載したDual PSU構成により、合計2000W以上の電源供給が可能です。これにより、サーバールームなどの特別な電源環境を必要とせず、一般的なオフィス環境においてもハイエンドなマルチGPU構成を実現します。さらに、オプションのラックマウントレールを装着することで、デスクサイド利用のみならず19インチラックへの搭載にも対応し、設置環境に応じた柔軟な運用が可能です。カスタマイズメニューにない構成についても、お気軽にお問い合わせください。お客様のご要望に応じて、優れたコストパフォーマンスと安定した運用環境をご提供いたします。
※本製品はWindows版もご用意しております。ご希望の際はお気軽にお問い合わせください。 NVIDIA RTX PRO 6000 Blackwell シリーズ製品比較レポート G-Suiteとは?できることをわかりやすく解説 ▼ より詳しい情報は以下の特設ページでご案内しております。https://www.gdep.co.jp/lp-deeplearningstation2/
VIDEO
独自設計 4GPU ワークステーションケース
DeepLearning STATION IIは、NVIDIAエリートパートナーであるジーデップ・アドバンスの独自設計により最大4枚のハイエンドGPUを搭載可能なAIワークステーションです。
フロントアクセス可能なストレージベイ
フロントアクセス可能な2基の3.5インチ 大容量HDDスワップベイを装備しオプションで冗長化にも対応しています。内蔵ベイには2.5インチの高速SSDを最大で4基搭載可能でシステムとデータエリアを分けた運用が可能です。
デュアルパワーサプライユニット搭載
オプションの 19インチラック マウントキットを装着することで6.5Uサイズで19インチラックへの搭載が可能です。
ラックマウントにも対応
オプションの 19インチラック マウントキットを装着することで6.5Uサイズで19インチラックへの搭載が可能です。
DeepLearning開発環境「G-Suite」
G-Suiteは、これまでジーデップ・アドバンスが提供してきた「G-Works」の仕組み(Deep Learning の主要なフレームワークを、各世代のGPU に最適化してビルドしたソフトウェア群)を継承し、さらに発展させたOS ネイティブ環境+コンテナ環境のハイブリッドアプリケーションリソースマネージメントツールです。インターネット上のWeb サイトから様々なレシピやサポートツール群をダウンロードし、簡易解説書やチュートリアルを含むアプリケーション実行環境を構築することが可能です。Ubuntu 24.04に対応し、開発環境は miniforgeをベースとしています。各世代のGPU に最適化してビルドしたソフトウェア群に加え、OS ネイティブ環境+コンテナ環境をハイブリッドにサポートしています。
Ubuntu 22.04に対応する「G-Works4.0」を選択されたい場合はこちら からご覧ください。
DeepLearning STATIONIIは、当社独自のケース設計により最大4枚のGPUを搭載可能なAIワークステーションです。「G-Works 4.0」をインストール
独自設計 4GPU ワークステーションケース
DeepLearning STATION IIは、NVIDIAエリートパートナーであるジーデップ・アドバンスの独自設計により最大4枚のハイエンドGPUを搭載可能なAIワークステーションです。
フロントアクセス可能なストレージベイ
フロントアクセス可能な2基の3.5インチ 大容量HDDスワップベイを装備しオプションで冗長化にも対応しています。内蔵ベイには2.5インチの高速SSDを最大で4基搭載可能でシステムとデータエリアを分けた運用が可能です。
デュアルパワーサプライユニット搭載
オプションの 19インチラック マウントキットを装着することで6.5Uサイズで19インチラックへの搭載が可能です。
ラックマウントにも対応
オプションの 19インチラック マウントキットを装着することで6.5Uサイズで19インチラックへの搭載が可能です。
当社独自のDeepLearning開発環境「G-Works4.0」をインストール
当社独自のDeepLearning開発環境である「G-Works 4.0」は、OSネーティブでディープラーニングフレームワークを利用できる環境に加えて、MLOpsプラットフォームであるWandBをプリインストールしており、実験結果のトラッキングや学習効率の可視化が可能です。
こちら からご覧ください。
DeepLearning STATIONIIは、当社独自のケース設計により最大4枚のGPUを搭載可能なAIワークステーションです。「G-Works 4.0」をインストール
独自設計 4GPU ワークステーションケース
DeepLearning STATION IIは、NVIDIAエリートパートナーであるジーデップ・アドバンスの独自設計により最大4枚のハイエンドGPUを搭載可能なAIワークステーションです。
フロントアクセス可能なストレージベイ
フロントアクセス可能な2基の3.5インチ 大容量HDDスワップベイを装備しオプションで冗長化にも対応しています。内蔵ベイには2.5インチの高速SSDを最大で4基搭載可能でシステムとデータエリアを分けた運用が可能です。
デュアルパワーサプライユニット搭載
オプションの 19インチラック マウントキットを装着することで6.5Uサイズで19インチラックへの搭載が可能です。
ラックマウントにも対応
オプションの 19インチラック マウントキットを装着することで6.5Uサイズで19インチラックへの搭載が可能です。
当社独自のDeepLearning開発環境「G-Works4.0」をインストール
当社独自のDeepLearning開発環境である「G-Works 4.0」は、OSネーティブでディープラーニングフレームワークを利用できる環境に加えて、MLOpsプラットフォームであるWandBをプリインストールしており、実験結果のトラッキングや学習効率の可視化が可能です。
こちら からご覧ください。
DeepLearning STATIONIIは、当社独自のケース設計により最大4枚のGPUを搭載可能なAIワークステーションです。「G-Works 4.0」をインストール
独自設計 4GPU ワークステーションケース
DeepLearning STATION IIは、NVIDIAエリートパートナーであるジーデップ・アドバンスの独自設計により最大4枚のハイエンドGPUを搭載可能なAIワークステーションです。
フロントアクセス可能なストレージベイ
フロントアクセス可能な2基の3.5インチ 大容量HDDスワップベイを装備しオプションで冗長化にも対応しています。内蔵ベイには2.5インチの高速SSDを最大で4基搭載可能でシステムとデータエリアを分けた運用が可能です。
デュアルパワーサプライユニット搭載
オプションの 19インチラック マウントキットを装着することで6.5Uサイズで19インチラックへの搭載が可能です。
ラックマウントにも対応
オプションの 19インチラック マウントキットを装着することで6.5Uサイズで19インチラックへの搭載が可能です。
当社独自のDeepLearning開発環境「G-Works4.0」をインストール
当社独自のDeepLearning開発環境である「G-Works 4.0」は、OSネーティブでディープラーニングフレームワークを利用できる環境に加えて、MLOpsプラットフォームであるWandBをプリインストールしており、実験結果のトラッキングや学習効率の可視化が可能です。
こちら からご覧ください。
DeepLearingBOXⅢ/WinはNVIDIA Blackwell アーキテクチャーGPUであるRTX PRO 6000 Blackwellシリーズを最大3基搭載可能なGPUディープラーニングワークステーションです。CPUにはインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids) W3500シリーズを採用し、シングルソケットで最大 60 個のメニーコア環境を実現。インテル スマートキャッシュはキャッシュとメモリー間のデータ交換の高速化によるレイテンシーを低減させます。また、最大 112 レーンの PCI Express 5.0 を備え、最大 224GT/ 秒の広帯域でGPU間を接続することで計算のボトルネックを大きく解消することが期待できます。GPUカードはNVIDIA Blackwell アーキテクチャーGPUであるRTX PRO 6000 Blackwellシリーズに対応しており、LLMなどの複雑で大規模なAI学習でもご利用いただけるワークステーションです。さらに100V-15A入力の高性能電源を2基搭載したDual PSU構成でトータル2000W以上の電源供給を可能にしており、サーバールームなど特別な電源環境を備えていない居室でもハイエンドマルチGPUが利用可能なハードウェアスペックを誇ります。NVIDIA RTX PRO 6000 Blackwell シリーズ製品比較レポート Windows11 WSL2セッティング済み
WSL2において以下のコンテナ環境でAI開発環境が提供されます。
製品初期設定時にはインターネット接続が必要です。
インテル Xeon W プロセッサー 搭載
最新の インテル® Xeon® W プロセッサー・ファミリー(開発コード Sapphire Rapids)は、さまざまなクリエイターのために設計されています。インテル® Xeon® W-3400/2400 プロセッサー搭載のプラットフォームは、VFX、3D レンダリング、複雑な 3D CAD、および AI 開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。また。最新のDeeplearningBOXIIIは液体冷却ユニットにより冷却が行われていることで、安全で静音な環境で利用することができます。
強化されたプラットフォーム
最新のDeeplearning BOXは、インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し、生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルな複雑なコンピューティングの需要に応えることが簡単にできます。
ウルトラハイエンドGPUカードを 最大3基搭載可能
コアパーツであるGPUは、最大3基フル帯域で搭載が可能。PCI Expressの最新世代のPCI Express 5.0レーンに対応しており、搭載可能なGPUはNVIDIA Blackwell アーキテクチャーGPU を最大3基搭載可能です。NVLinkにも対応し、2基1組でNVLinkブリッジを介して最大112GB/Secという広帯域でGPU間の高速なデータの転送を実現します。また、標準でCEM5に対応ケーブルを標準採用しており、最新世代のGPU搭載もサポートしております。
WSL2セッティング済みAI学習フレームワーク搭載
Windows 11 ProをOSに採用した本システムはLinux OS仮想環境を共存させ、Linuxのネイティブアプリケーションを実行可能とするWindows Subsystem for Linux Version 2 (WSL2) を利用しています。多くのAIアプリケーションがLinux上で開発されている中、それらのAIアプリケーションとWindowsデスクトップ環境の統合が容易になります。システム仕様に最適なDeep Learning環境をWindows上で容易に構築できるこの仕組みはユーザーのAI開発環境構築の負担を大幅に削減し、ファイルシステムへのアクセスも、Windows – Linuxの双方向でほぼシームレスに扱うことが可能でます。ユーザーがAI開発において面倒で複雑な開発環境設定を行うことなく、届いたその日からご利用いただけます。
DeepLearning BOXIIIはインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids) W3400シリーズを搭載した GPUディープラーニングワークステーションです。Windows11 WSL2セッティング済み
WSL2において以下のコンテナ環境でAI開発環境が提供されます。
製品初期設定時にはインターネット接続が必要です。
インテル Xeon W プロセッサー 搭載
最新の インテル® Xeon® W プロセッサー・ファミリー(開発コード Sapphire Rapids)は、さまざまなクリエイターのために設計されています。インテル® Xeon® W-3400/2400 プロセッサー搭載のプラットフォームは、VFX、3D レンダリング、複雑な 3D CAD、および AI 開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。また。最新のDeeplearningBOXIIIは液体冷却ユニットにより冷却が行われていることで、安全で静音な環境で利用することができます。
強化されたプラットフォーム
最新のDeeplearning BOXは、インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し、生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルな複雑なコンピューティングの需要に応えることが簡単にできます。
ウルトラハイエンドGPUカードを 最大3基搭載可能
コアパーツであるGPUは、最大3基フル帯域で搭載が可能。PCI Expressの最新世代のPCI Express 5.0レーンに対応しており、搭載可能なGPUはNVIDIA Blackwell アーキテクチャーGPU を最大3基搭載可能です。NVLinkにも対応し、2基1組でNVLinkブリッジを介して最大112GB/Secという広帯域でGPU間の高速なデータの転送を実現します。また、標準でCEM5に対応ケーブルを標準採用しており、最新世代のGPU搭載もサポートしております。
WSL2セッティング済みAI学習フレームワーク搭載
Windows 11 ProをOSに採用した本システムはLinux OS仮想環境を共存させ、Linuxのネイティブアプリケーションを実行可能とするWindows Subsystem for Linux Version 2 (WSL2) を利用しています。多くのAIアプリケーションがLinux上で開発されている中、それらのAIアプリケーションとWindowsデスクトップ環境の統合が容易になります。システム仕様に最適なDeep Learning環境をWindows上で容易に構築できるこの仕組みはユーザーのAI開発環境構築の負担を大幅に削減し、ファイルシステムへのアクセスも、Windows – Linuxの双方向でほぼシームレスに扱うことが可能でます。ユーザーがAI開発において面倒で複雑な開発環境設定を行うことなく、届いたその日からご利用いただけます。
DeepLearning BOXIIIはインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids) W3400シリーズを搭載した GPUディープラーニングワークステーションです。Windows11 WSL2セッティング済み
WSL2において以下のコンテナ環境でAI開発環境が提供されます。
製品初期設定時にはインターネット接続が必要です。
GWS-ISASM-2Gはインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids) Wシリーズを搭載したデスクサイドGPUワークステーションです。最新のXeon Wの採用によりシングルソケットでメニーコア環境を実現。インテル ターボ・ブースト・マックス・テクノロジー 3.0 は 最大 4.8GHz の CPUクロックによって軽度にスレッド化されたアプリケーションのコアパフォーマンスを最適化し、インテル スマートキャッシュはキャッシュとメモリー間のデータ交換の高速化によるレイテンシーを低減させます。
NVIDIA Ada Lovelace アーキテクチャ 世代 TDP 450W クラスGPUカードが搭載可能
第 4 世代 Tensor コアにより、新しいFP8 Transformerエンジンを使用して驚異的に速い最大 5 倍のスループットの向上と、1.4 Tensor-petaFLOPS の性能を実現します。Ada の第 3 世代 RT コアは、レイ-トライアングル交差のスループットが 2 倍になり、RT-TFLOP 性能が 2 倍以上向上します。これらプロフェッショナル グラフィックス、AI、コンピューティング性能を実現するために設計されております。
インテル Xeon W プロセッサー 搭載
最新の インテル® Xeon® W プロセッサー・ファミリー(開発コード Sapphire Rapids)はさまざまなクリエイターのために設計されています。インテル® Xeon® W-3400/2400 プロセッサー搭載のプラットフォームは、VFX、3D レンダリング、複雑な 3D CAD、および AI 開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。
強化されたプラットフォーム
インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルな複雑なコンピューティングの需要に応えることが簡単にできます。
安定度抜群の高効率電源
採用されている電源は高品質のDC-DCコンバータを使用した大容量高効率ユニットです。100V環境で1200W の容量を実現しワークステーション用途はもちろん、サーバーレベルの要求仕様も満たす品質と高いTDPを要求する演算用GPUカードも安定した性能を発揮出来る余裕のマージン設計です。
GWS-ISASM-2Gはインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids) Wシリーズを搭載したデスクサイドGPUワークステーションです。最新のXeon Wの採用によりシングルソケットでメニーコア環境を実現。インテル ターボ・ブースト・マックス・テクノロジー 3.0 は 最大 4.8GHz の CPUクロックによって軽度にスレッド化されたアプリケーションのコアパフォーマンスを最適化し、インテル スマートキャッシュはキャッシュとメモリー間のデータ交換の高速化によるレイテンシーを低減させます。
NVIDIA Ada Lovelace アーキテクチャ 世代 TDP 450W クラスGPUカードが搭載可能
第 4 世代 Tensor コアにより、新しいFP8 Transformerエンジンを使用して驚異的に速い最大 5 倍のスループットの向上と、1.4 Tensor-petaFLOPS の性能を実現します。Ada の第 3 世代 RT コアは、レイ-トライアングル交差のスループットが 2 倍になり、RT-TFLOP 性能が 2 倍以上向上します。これらプロフェッショナル グラフィックス、AI、コンピューティング性能を実現するために設計されております。
インテル Xeon W プロセッサー 搭載
最新の インテル® Xeon® W プロセッサー・ファミリー(開発コード Sapphire Rapids)はさまざまなクリエイターのために設計されています。インテル® Xeon® W-3400/2400 プロセッサー搭載のプラットフォームは、VFX、3D レンダリング、複雑な 3D CAD、および AI 開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。
強化されたプラットフォーム
インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルな複雑なコンピューティングの需要に応えることが簡単にできます。
安定度抜群の高効率電源
採用されている電源は高品質のDC-DCコンバータを使用した大容量高効率ユニットです。100V環境で1200W の容量を実現しワークステーション用途はもちろん、サーバーレベルの要求仕様も満たす品質と高いTDPを要求する演算用GPUカードも安定した性能を発揮出来る余裕のマージン設計です。
GWS-ISASM-2Gはインテル® Xeon® W プロセッサー(開発コード:Sapphire Rapids) Wシリーズを搭載したデスクサイドGPUワークステーションです。最新のXeon Wの採用によりシングルソケットでメニーコア環境を実現。インテル ターボ・ブースト・マックス・テクノロジー 3.0 は 最大 4.8GHz の CPUクロックによって軽度にスレッド化されたアプリケーションのコアパフォーマンスを最適化し、インテル スマートキャッシュはキャッシュとメモリー間のデータ交換の高速化によるレイテンシーを低減させます。
NVIDIA Ada Lovelace アーキテクチャ 世代 TDP 450W クラスGPUカードが搭載可能
第 4 世代 Tensor コアにより、新しいFP8 Transformerエンジンを使用して驚異的に速い最大 5 倍のスループットの向上と、1.4 Tensor-petaFLOPS の性能を実現します。Ada の第 3 世代 RT コアは、レイ-トライアングル交差のスループットが 2 倍になり、RT-TFLOP 性能が 2 倍以上向上します。これらプロフェッショナル グラフィックス、AI、コンピューティング性能を実現するために設計されております。
インテル Xeon W プロセッサー 搭載
最新の インテル® Xeon® W プロセッサー・ファミリー(開発コード Sapphire Rapids)はさまざまなクリエイターのために設計されています。インテル® Xeon® W-3400/2400 プロセッサー搭載のプラットフォームは、VFX、3D レンダリング、複雑な 3D CAD、および AI 開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。
強化されたプラットフォーム
インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルな複雑なコンピューティングの需要に応えることが簡単にできます。
安定度抜群の高効率電源
採用されている電源は高品質のDC-DCコンバータを使用した大容量高効率ユニットです。100V環境で1200W の容量を実現しワークステーション用途はもちろん、サーバーレベルの要求仕様も満たす品質と高いTDPを要求する演算用GPUカードも安定した性能を発揮出来る余裕のマージン設計です。
GSV-ATRSM-5U8Gは、最新のNVIDIA H200 NVL(141GB)やRTX PRO 6000 Blackwell Max-Qなど、先進的なGPUを最大8基まで搭載可能な5Uラックマウント型GPUサーバーです。生成AI、大規模HPC、VDI、3Dレンダリング、医用イメージングといった高負荷なワークロードに対応するために設計されており、あらゆる次世代計算ニーズに応えます。CPUには、AMDの次世代アーキテクチャ「EPYC 9005/9004シリーズ(Turin)」をデュアルソケットで搭載可能。最大192コア・500W TDPにより、圧倒的な並列処理能力と高効率な計算性能を発揮します。メモリは、DDR5 ECC RDIMM/MRDIMMを最大24スロット・6TBまでサポートし、最大6000MT/sの転送速度に対応。AIトレーニングや大規模シミュレーションに最適な高速・大容量メモリ構成が可能です。
拡張性にも優れ、PCIe 5.0 x16スロットを9基搭載。NVIDIA NVLink Bridge(オプション)によるGPU間の高速通信にも対応します。ストレージは、2.5インチNVMeホットスワップベイを4基、さらに1基のM.2 NVMeスロットを備え、リードライトの高速性と柔軟な構成を両立。OCP 3.0/AIOMスロットによるネットワーク機能の拡張性も確保しています。
冷却面では、高性能ファン合計10基により安定したエアフローを維持。電源には、96%以上の効率を誇るTitaniumレベルの2700W冗長電源を6基(4+2構成)を搭載し、常時高負荷が想定される環境でも高可用性を維持します。
※NVIDIA RTX PRO 6000 Blackwell Server Edition を8基搭載される場合は、動作温度環境を27度以下に設定いただく必要があります。詳しくは当社までお問い合わせください。 NVIDIA RTX PRO 6000 Blackwell シリーズ製品比較レポート
AMD 第5世代 AMD EPYC CPU 「Turin」 搭載
AMD EPYC™ Turinは、次世代のデータセンターおよびHPC向けに設計された第5世代EPYCプロセッサで、Zen 5アーキテクチャを採用しています。最大192コア/384スレッドという圧倒的な並列処理能力を備え、AI、HPC、仮想化、クラウド、データ分析などの高負荷ワークロードに最適です。最新のDDR5メモリとPCIe 5.0をサポートし、広帯域かつ低レイテンシのデータ転送を実現。優れた電力効率とセキュリティ機能を兼ね備え、次世代インフラの中核を担う高性能CPUです。
最新の NVIDIA Blackwell世代GPUや、Hopper世代 GPU H200 を最大8枚搭載可能
GSV-ATRSM-5U8Gは、NVIDIAの最新GPUであるRTX 6000 Blackwell Max-Q(Blackwellアーキテクチャ)をはじめ、Hopper世代のH200、Ada世代のRTX 6000 Adaなどに対応した高性能GPUサーバーです。AI推論や生成AI、HPC、3Dレンダリングといった多様なワークロードに最適な性能を提供します。特にBlackwell Max-QはFP8演算や高度なTransformer処理を省電力で実現し、高効率かつ高密度なAI環境を構築可能。第6世代Intel® Xeon® Scalableプロセッサー(Granite Rapids)との組み合わせにより、柔軟かつ拡張性の高いシステム構成が可能です。
エンタープライズ NVMe SSD
GSVシリーズに搭載されているNVMe SSDはビジネスインテリジェンス(BI)、オンライントランザクション処理(OLTP)、ソフトウェア・デファインド・ストレージ(SDS)、仮想化環境などの様々な企業向けアプリケーションおよび関連ワークロードに適したリードインテンシブSSDです。 あらゆる状態において、高い安定性能を維持し優れた耐久性と高速性を実現します。
DeepLearning開発環境「G-Suite」
G-Suiteは、これまでジーデップ・アドバンスが提供してきた「G-Works」の仕組み(Deep Learning の主要なフレームワークを、各世代のGPU に最適化してビルドしたソフトウェア群)を継承し、さらに発展させたOS ネイティブ環境+コンテナ環境のハイブリッドアプリケーションリソースマネージメントツールです。インターネット上のWeb サイトから様々なレシピやサポートツール群をダウンロードし、簡易解説書やチュートリアルを含むアプリケーション実行環境を構築することが可能です。Ubuntu 24.04に対応し、開発環境は miniforgeをベースとしています。各世代のGPU に最適化してビルドしたソフトウェア群に加え、OS ネイティブ環境+コンテナ環境をハイブリッドにサポートしています。
こちら からご覧ください。
大切なシステムを丸ごと守る、安心の完全バックアップIntegrated Backup搭載
GDEP Advance Integrated Backup(以下 Integrated Backup)はジーデップ・アドバンスが提供する コンピュータのシステム領域を完全バックアップするためのユーティリティツールです。 システムディスクのパーティション、ファイルシステムフォーマット、データ内容をすべて記録することが可能で、日付やコメントをつけてバックアップ内容を管理できます。ブートディスク消失時の復旧や、過去にバックアップしたの状態への復帰などが容易に行えます。 【動作条件】 ・システムディスク以外にデータディスクが一つ以上装備されている必要があります。 ・バックアップイメージはシステムディスク以外のディスクに独立して組み込まれます。 ・OSをシャットダウンさせたうえで、バックアップが入っているディスクからブートさせます。 ・バックアップデータは日付別に分類されて保存されます。
GSV-ATRSM-5U8Gは、最新のNVIDIA H200 NVL(141GB)やRTX PRO 6000 Blackwell Max-Qなど、先進的なGPUを最大8基まで搭載可能な5Uラックマウント型GPUサーバーです。生成AI、大規模HPC、VDI、3Dレンダリング、医用イメージングといった高負荷なワークロードに対応するために設計されており、あらゆる次世代計算ニーズに応えます。CPUには、AMDの次世代アーキテクチャ「EPYC 9005/9004シリーズ(Turin)」をデュアルソケットで搭載可能。最大192コア・500W TDPにより、圧倒的な並列処理能力と高効率な計算性能を発揮します。メモリは、DDR5 ECC RDIMM/MRDIMMを最大24スロット・6TBまでサポートし、最大6000MT/sの転送速度に対応。AIトレーニングや大規模シミュレーションに最適な高速・大容量メモリ構成が可能です。※NVIDIA RTX PRO 6000 Blackwell Server Edition を8基搭載される場合は、動作温度環境を27度以下に設定いただく必要があります。詳しくは当社までお問い合わせください。
AMD 第5世代 AMD EPYC CPU 「Turin」 搭載
AMD EPYC™ Turinは、次世代のデータセンターおよびHPC向けに設計された第5世代EPYCプロセッサで、Zen 5アーキテクチャを採用しています。最大192コア/384スレッドという圧倒的な並列処理能力を備え、AI、HPC、仮想化、クラウド、データ分析などの高負荷ワークロードに最適です。最新のDDR5メモリとPCIe 5.0をサポートし、広帯域かつ低レイテンシのデータ転送を実現。優れた電力効率とセキュリティ機能を兼ね備え、次世代インフラの中核を担う高性能CPUです。
最新の NVIDIA Blackwell世代GPUや、Hopper世代 GPU H200 を最大8枚搭載可能
GSV-ATRSM-5U8Gは、NVIDIAの最新GPUであるRTX 6000 Blackwell Max-Q(Blackwellアーキテクチャ)をはじめ、Hopper世代のH200、Ada世代のRTX 6000 Adaなどに対応した高性能GPUサーバーです。AI推論や生成AI、HPC、3Dレンダリングといった多様なワークロードに最適な性能を提供します。特にBlackwell Max-QはFP8演算や高度なTransformer処理を省電力で実現し、高効率かつ高密度なAI環境を構築可能。第6世代Intel® Xeon® Scalableプロセッサー(Granite Rapids)との組み合わせにより、柔軟かつ拡張性の高いシステム構成が可能です。
エンタープライズ NVMe SSD
GSVシリーズに搭載されているNVMe SSDはビジネスインテリジェンス(BI)、オンライントランザクション処理(OLTP)、ソフトウェア・デファインド・ストレージ(SDS)、仮想化環境などの様々な企業向けアプリケーションおよび関連ワークロードに適したリードインテンシブSSDです。 あらゆる状態において、高い安定性能を維持し優れた耐久性と高速性を実現します。
DeepLearning開発環境「G-Suite」
G-Suiteは、これまでジーデップ・アドバンスが提供してきた「G-Works」の仕組み(Deep Learning の主要なフレームワークを、各世代のGPU に最適化してビルドしたソフトウェア群)を継承し、さらに発展させたOS ネイティブ環境+コンテナ環境のハイブリッドアプリケーションリソースマネージメントツールです。インターネット上のWeb サイトから様々なレシピやサポートツール群をダウンロードし、簡易解説書やチュートリアルを含むアプリケーション実行環境を構築することが可能です。Ubuntu 24.04に対応し、開発環境は miniforgeをベースとしています。各世代のGPU に最適化してビルドしたソフトウェア群に加え、OS ネイティブ環境+コンテナ環境をハイブリッドにサポートしています。 こちら からご覧ください。
大切なシステムを丸ごと守る、安心の完全バックアップIntegrated Backup搭載
GDEP Advance Integrated Backup(以下 Integrated Backup)はジーデップ・アドバンスが提供する
コンピュータのシステム領域を完全バックアップするためのユーティリティツールです。
システムディスクのパーティション、ファイルシステムフォーマット、データ内容をすべて記録することが可能で、日付やコメントをつけてバックアップ内容を管理できます。ブートディスク消失時の復旧や、過去にバックアップしたの状態への復帰などが容易に行えます。
【動作条件】
・システムディスク以外にデータディスクが一つ以上装備されている必要があります。
・バックアップイメージはシステムディスク以外のディスクに独立して組み込まれます。
・OSをシャットダウンさせたうえで、バックアップが入っているディスクからブートさせます。
・バックアップデータは日付別に分類されて保存されます。
GSV-ATRSM-5U8Gは、最新のNVIDIA H200 NVL(141GB)やRTX PRO 6000 Blackwell Max-Qなど、先進的なGPUを最大8基まで搭載可能な5Uラックマウント型GPUサーバーです。生成AI、大規模HPC、VDI、3Dレンダリング、医用イメージングといった高負荷なワークロードに対応するために設計されており、あらゆる次世代計算ニーズに応えます。CPUには、AMDの次世代アーキテクチャ「EPYC 9005/9004シリーズ(Turin)」をデュアルソケットで搭載可能。最大192コア・500W TDPにより、圧倒的な並列処理能力と高効率な計算性能を発揮します。メモリは、DDR5 ECC RDIMM/MRDIMMを最大24スロット・6TBまでサポートし、最大6000MT/sの転送速度に対応。AIトレーニングや大規模シミュレーションに最適な高速・大容量メモリ構成が可能です。※NVIDIA RTX PRO 6000 Blackwell Server Edition を8基搭載される場合は、動作温度環境を27度以下に設定いただく必要があります。詳しくは当社までお問い合わせください。
AMD 第5世代 AMD EPYC CPU 「Turin」 搭載
AMD EPYC™ Turinは、次世代のデータセンターおよびHPC向けに設計された第5世代EPYCプロセッサで、Zen 5アーキテクチャを採用しています。最大192コア/384スレッドという圧倒的な並列処理能力を備え、AI、HPC、仮想化、クラウド、データ分析などの高負荷ワークロードに最適です。最新のDDR5メモリとPCIe 5.0をサポートし、広帯域かつ低レイテンシのデータ転送を実現。優れた電力効率とセキュリティ機能を兼ね備え、次世代インフラの中核を担う高性能CPUです。
最新の NVIDIA Blackwell世代GPUや、Hopper世代 GPU H200 を最大8枚搭載可能
GSV-ATRSM-5U8Gは、NVIDIAの最新GPUであるRTX 6000 Blackwell Max-Q(Blackwellアーキテクチャ)をはじめ、Hopper世代のH200、Ada世代のRTX 6000 Adaなどに対応した高性能GPUサーバーです。AI推論や生成AI、HPC、3Dレンダリングといった多様なワークロードに最適な性能を提供します。特にBlackwell Max-QはFP8演算や高度なTransformer処理を省電力で実現し、高効率かつ高密度なAI環境を構築可能。第6世代Intel® Xeon® Scalableプロセッサー(Granite Rapids)との組み合わせにより、柔軟かつ拡張性の高いシステム構成が可能です。
エンタープライズ NVMe SSD
GSVシリーズに搭載されているNVMe SSDはビジネスインテリジェンス(BI)、オンライントランザクション処理(OLTP)、ソフトウェア・デファインド・ストレージ(SDS)、仮想化環境などの様々な企業向けアプリケーションおよび関連ワークロードに適したリードインテンシブSSDです。 あらゆる状態において、高い安定性能を維持し優れた耐久性と高速性を実現します。
DeepLearning開発環境「G-Suite」
G-Suiteは、これまでジーデップ・アドバンスが提供してきた「G-Works」の仕組み(Deep Learning の主要なフレームワークを、各世代のGPU に最適化してビルドしたソフトウェア群)を継承し、さらに発展させたOS ネイティブ環境+コンテナ環境のハイブリッドアプリケーションリソースマネージメントツールです。インターネット上のWeb サイトから様々なレシピやサポートツール群をダウンロードし、簡易解説書やチュートリアルを含むアプリケーション実行環境を構築することが可能です。Ubuntu 24.04に対応し、開発環境は miniforgeをベースとしています。各世代のGPU に最適化してビルドしたソフトウェア群に加え、OS ネイティブ環境+コンテナ環境をハイブリッドにサポートしています。 こちら からご覧ください。
大切なシステムを丸ごと守る、安心の完全バックアップIntegrated Backup搭載
GDEP Advance Integrated Backup(以下 Integrated Backup)はジーデップ・アドバンスが提供する
コンピュータのシステム領域を完全バックアップするためのユーティリティツールです。
システムディスクのパーティション、ファイルシステムフォーマット、データ内容をすべて記録することが可能で、日付やコメントをつけてバックアップ内容を管理できます。ブートディスク消失時の復旧や、過去にバックアップしたの状態への復帰などが容易に行えます。
【動作条件】
・システムディスク以外にデータディスクが一つ以上装備されている必要があります。
・バックアップイメージはシステムディスク以外のディスクに独立して組み込まれます。
・OSをシャットダウンさせたうえで、バックアップが入っているディスクからブートさせます。
・バックアップデータは日付別に分類されて保存されます。
GSV-ATRSM-5U8Gは、最新のNVIDIA H200 NVL(141GB)やRTX PRO 6000 Blackwell Max-Qなど、先進的なGPUを最大8基まで搭載可能な5Uラックマウント型GPUサーバーです。生成AI、大規模HPC、VDI、3Dレンダリング、医用イメージングといった高負荷なワークロードに対応するために設計されており、あらゆる次世代計算ニーズに応えます。CPUには、AMDの次世代アーキテクチャ「EPYC 9005/9004シリーズ(Turin)」をデュアルソケットで搭載可能。最大192コア・500W TDPにより、圧倒的な並列処理能力と高効率な計算性能を発揮します。メモリは、DDR5 ECC RDIMM/MRDIMMを最大24スロット・6TBまでサポートし、最大6000MT/sの転送速度に対応。AIトレーニングや大規模シミュレーションに最適な高速・大容量メモリ構成が可能です。※NVIDIA RTX PRO 6000 Blackwell Server Edition を8基搭載される場合は、動作温度環境を27度以下に設定いただく必要があります。詳しくは当社までお問い合わせください。
AMD 第5世代 AMD EPYC CPU 「Turin」 搭載
AMD EPYC™ Turinは、次世代のデータセンターおよびHPC向けに設計された第5世代EPYCプロセッサで、Zen 5アーキテクチャを採用しています。最大192コア/384スレッドという圧倒的な並列処理能力を備え、AI、HPC、仮想化、クラウド、データ分析などの高負荷ワークロードに最適です。最新のDDR5メモリとPCIe 5.0をサポートし、広帯域かつ低レイテンシのデータ転送を実現。優れた電力効率とセキュリティ機能を兼ね備え、次世代インフラの中核を担う高性能CPUです。
最新の NVIDIA Blackwell世代GPUや、Hopper世代 GPU H200 を最大8枚搭載可能
GSV-ATRSM-5U8Gは、NVIDIAの最新GPUであるRTX 6000 Blackwell Max-Q(Blackwellアーキテクチャ)をはじめ、Hopper世代のH200、Ada世代のRTX 6000 Adaなどに対応した高性能GPUサーバーです。AI推論や生成AI、HPC、3Dレンダリングといった多様なワークロードに最適な性能を提供します。特にBlackwell Max-QはFP8演算や高度なTransformer処理を省電力で実現し、高効率かつ高密度なAI環境を構築可能。第6世代Intel® Xeon® Scalableプロセッサー(Granite Rapids)との組み合わせにより、柔軟かつ拡張性の高いシステム構成が可能です。
エンタープライズ NVMe SSD
GSVシリーズに搭載されているNVMe SSDはビジネスインテリジェンス(BI)、オンライントランザクション処理(OLTP)、ソフトウェア・デファインド・ストレージ(SDS)、仮想化環境などの様々な企業向けアプリケーションおよび関連ワークロードに適したリードインテンシブSSDです。 あらゆる状態において、高い安定性能を維持し優れた耐久性と高速性を実現します。
DeepLearning開発環境「G-Suite」
G-Suiteは、これまでジーデップ・アドバンスが提供してきた「G-Works」の仕組み(Deep Learning の主要なフレームワークを、各世代のGPU に最適化してビルドしたソフトウェア群)を継承し、さらに発展させたOS ネイティブ環境+コンテナ環境のハイブリッドアプリケーションリソースマネージメントツールです。インターネット上のWeb サイトから様々なレシピやサポートツール群をダウンロードし、簡易解説書やチュートリアルを含むアプリケーション実行環境を構築することが可能です。Ubuntu 24.04に対応し、開発環境は miniforgeをベースとしています。各世代のGPU に最適化してビルドしたソフトウェア群に加え、OS ネイティブ環境+コンテナ環境をハイブリッドにサポートしています。 こちら からご覧ください。
大切なシステムを丸ごと守る、安心の完全バックアップIntegrated Backup搭載
GDEP Advance Integrated Backup(以下 Integrated Backup)はジーデップ・アドバンスが提供する
コンピュータのシステム領域を完全バックアップするためのユーティリティツールです。
システムディスクのパーティション、ファイルシステムフォーマット、データ内容をすべて記録することが可能で、日付やコメントをつけてバックアップ内容を管理できます。ブートディスク消失時の復旧や、過去にバックアップしたの状態への復帰などが容易に行えます。
【動作条件】
・システムディスク以外にデータディスクが一つ以上装備されている必要があります。
・バックアップイメージはシステムディスク以外のディスクに独立して組み込まれます。
・OSをシャットダウンさせたうえで、バックアップが入っているディスクからブートさせます。
・バックアップデータは日付別に分類されて保存されます。
ザイリンクスの Alveo™ U50 データセンター アクセラレータ カードは、金融コンピューティング、機械学習、計算用ストレージ、データ検索/分析などあらゆるワークロードに対応し、最適化されたアクセラレーション機能を提供します。ザイリンクスの UltraScale+™ アーキテクチャをベースに構築され、75 ワットと電力効率に優れたロープロファイル型のフォームファクターにパッケージングされた U50 は、100Gbps ネットワーク I/O、PCIe Gen4、HBM を統合し、あらゆるサーバー形態で運用可能です。
Alveo アクセラレータ カードは、変化するアクセラレーション要件やアルゴリズム規格に柔軟に対応でき、ハードウェアを変更しなくてもあらゆるワークロードを加速できる上に、総保有コスト (TCO) を削減できます。
Alveo アクセラレータ カードの利用は、一般的なデータセンター ワークロード向けにザイリンクスおよびパートナーが提供するアプリケーションの広範なエコシステムでサポートされています。カスタム ソリューションを構築する場合は、アプリケーション開発者ツール (
SDAccel™ ツール ) および
Machine Learning Suite を利用することで、差別化したアプリケーションを市場へ送り出すことができます。
※このカードはPassive(ファンレス)設計であり、高い冷却性能を有する筐体への搭載を前提としています。
※ジーデップ・アドバンスのサーバー、ワークステーションは最新の高負荷GPUカードが安定して最高のパフォーマンスが発揮できるよう、
このカードを搭載したモデルはこちらから DeepLearningBOX III DeepLearningSTATION II
プロフェッショナル向けのパフォーマンスと機能
最大のパフォーマンスを求めるプロフェッショナル向けに設計されたNVIDIA RTX PRO™ ソリューションは、幅広い設計、エンジニアリング、AI ワークフロー向けに厳密にテストされ、NVIDIA RTX Enterprise ドライバーにより最適化されています。96GB のGDDR7 メモリ搭載により、膨大なデータセット、複雑なシミュレーション、AI 強化アプリケーションを高いパフォーマンスと精度で処理できます。また、Blackwellストリーミング マルチプロセッサ(SM)は、GPU あたり最大24,064のCUDAコアを搭載し、FP32スループットは前世代比で最大1.4倍向上します。
NVIDIA Blackwell アーキテクチャー
NVIDIA Blackwell アーキテクチャは、AI、レイトレーシング、ニューラルグラフィックス技術を組み合わせており、パフォーマンスとメモリの大幅な向上を実現します。これにより、先進的なクリエイティブ、設計、エンジニアリングワークフローを推進します。
高帯域で大容量なGDDR7 メモリ
新しく改良されたGDDR7 メモリは、帯域幅と容量が大幅に向上したことで、アプリケーションをより高速で複雑なデータセットで作業できるようになりました。
PCIe Gen5
NVIDIA RTX PRO™はPCI Express Gen5 をサポートし、PCIe Gen4 の2 倍の速度となるx16 接続で最大64GB/ 秒の帯域幅を実現します。AI やデータサイエンスなどのデータ集約型タスクにおいて、CPU メモリからのデータ転送速度が大幅に向上。更に、PCIe パフォーマンスの向上により、GPU ダイレクトメモリアクセス(DMA)転送、GPUDirect ストレージでの入出力も高速化されます。これらのデータ転送の高速化を通じて、プロフェッショナル向けの計算およびグラフィックス処理をこれまで以上に効率的に行うことができます。
※ジーデップ・アドバンスのサーバー、ワークステーションは最新の高負荷GPUカードが安定して最高のパフォーマンスが発揮できるよう、
このカードを搭載したモデルはこちらから DeepLearningBOX III DeepLearningSTATION II
プロフェッショナル向けのパフォーマンスと機能
最大のパフォーマンスを求めるプロフェッショナル向けに設計されたNVIDIA RTX PRO™ ソリューションは、幅広い設計、エンジニアリング、AI ワークフロー向けに厳密にテストされ、NVIDIA RTX Enterprise ドライバーにより最適化されています。96GB のGDDR7 メモリ搭載により、膨大なデータセット、複雑なシミュレーション、AI 強化アプリケーションを高いパフォーマンスと精度で処理できます。
NVIDIA Blackwell アーキテクチャー
NVIDIA Blackwell アーキテクチャは、AI、レイトレーシング、ニューラルグラフィックス技術を組み合わせており、パフォーマンスとメモリの大幅な向上を実現します。これにより、先進的なクリエイティブ、設計、エンジニアリングワークフローを推進します。
高帯域で大容量なGDDR7 メモリ
新しく改良されたGDDR7 メモリは、帯域幅と容量が大幅に向上したことで、アプリケーションをより高速で複雑なデータセットで作業できるようになりました。
PCIe Gen5
NVIDIA RTX PRO™はPCI Express Gen5 をサポートし、PCIe Gen4 の2 倍の速度となるx16 接続で最大64GB/ 秒の帯域幅を実現します。AI やデータサイエンスなどのデータ集約型タスクにおいて、CPU メモリからのデータ転送速度が大幅に向上。更に、PCIe パフォーマンスの向上により、GPU ダイレクトメモリアクセス(DMA)転送、GPUDirect ストレージでの入出力も高速化されます。これらのデータ転送の高速化を通じて、プロフェッショナル向けの計算およびグラフィックス処理をこれまで以上に効率的に行うことができます。
2025年3月、NVIDIAより最大のパフォーマンスを追究するプロフェッショナル向けに設計されたNVIDIA RTX PRO™がリリースされました。
プロフェッショナル向けのパフォーマンスと機能
最大のパフォーマンスを求めるプロフェッショナル向けに設計されたNVIDIA RTX PRO™ ソリューションは、幅広い設計、エンジニアリング、AI ワークフロー向けに厳密にテストされ、NVIDIA RTX Enterprise ドライバーにより最適化されています。96GB のGDDR7 メモリ搭載により、膨大なデータセット、複雑なシミュレーション、AI 強化アプリケーションを高いパフォーマンスと精度で処理できます。
NVIDIA Blackwell アーキテクチャー
NVIDIA Blackwell アーキテクチャは、AI、レイトレーシング、ニューラルグラフィックス技術を組み合わせており、パフォーマンスとメモリの大幅な向上を実現します。これにより、先進的なクリエイティブ、設計、エンジニアリングワークフローを推進します。
高帯域で大容量なGDDR7 メモリ
新しく改良されたGDDR7 メモリは、帯域幅と容量が大幅に向上したことで、アプリケーションをより高速で複雑なデータセットで作業できるようになりました。
PCIe Gen5
NVIDIA RTX PRO™はPCI Express Gen5 をサポートし、PCIe Gen4 の2 倍の速度となるx16 接続で最大64GB/ 秒の帯域幅を実現します。AI やデータサイエンスなどのデータ集約型タスクにおいて、CPU メモリからのデータ転送速度が大幅に向上。更に、PCIe パフォーマンスの向上により、GPU ダイレクトメモリアクセス(DMA)転送、GPUDirect ストレージでの入出力も高速化されます。これらのデータ転送の高速化を通じて、プロフェッショナル向けの計算およびグラフィックス処理をこれまで以上に効率的に行うことができます。
2025年3月、NVIDIAより最大のパフォーマンスを追究するプロフェッショナル向けに設計されたNVIDIA RTX PRO™がリリースされました。
プロフェッショナル向けのパフォーマンスと機能
最大のパフォーマンスを求めるプロフェッショナル向けに設計されたNVIDIA RTX PRO™ ソリューションは、幅広い設計、エンジニアリング、AI ワークフロー向けに厳密にテストされ、NVIDIA RTX Enterprise ドライバーにより最適化されています。96GB のGDDR7 メモリ搭載により、膨大なデータセット、複雑なシミュレーション、AI 強化アプリケーションを高いパフォーマンスと精度で処理できます。
NVIDIA Blackwell アーキテクチャー
NVIDIA Blackwell アーキテクチャは、AI、レイトレーシング、ニューラルグラフィックス技術を組み合わせており、パフォーマンスとメモリの大幅な向上を実現します。これにより、先進的なクリエイティブ、設計、エンジニアリングワークフローを推進します。
高帯域で大容量なGDDR7 メモリ
新しく改良されたGDDR7 メモリは、帯域幅と容量が大幅に向上したことで、アプリケーションをより高速で複雑なデータセットで作業できるようになりました。
PCIe Gen5
NVIDIA RTX PRO™はPCI Express Gen5 をサポートし、PCIe Gen4 の2 倍の速度となるx16 接続で最大64GB/ 秒の帯域幅を実現します。AI やデータサイエンスなどのデータ集約型タスクにおいて、CPU メモリからのデータ転送速度が大幅に向上。更に、PCIe パフォーマンスの向上により、GPU ダイレクトメモリアクセス(DMA)転送、GPUDirect ストレージでの入出力も高速化されます。これらのデータ転送の高速化を通じて、プロフェッショナル向けの計算およびグラフィックス処理をこれまで以上に効率的に行うことができます。
NVIDIA® H200 NVL は、最新のGPUアーキテクチャ「Hopper」を採用し、大容量141GBのHBM3eメモリと4.8TB/sの帯域幅を実現し生成AIに最適化されたGPUです。700億パラメータの大規模言語モデル 「Llama2 70B」の推論を前モデルである、NVIDIA H100と比較して1.9倍、1750億パラメータの大規模言語モデル「GPT3-175B」の推論で1.6倍高速化し、HPCアプリケーションにおいてはCPU (Xeon® Platinum 8480+ 2CPU) に比べて110倍の高速化を実現します。
NVIDIA® H200は、大規模言語モデル研究の新たな可能性を広げる強力なツールとして、従来のGPUでは困難だった大規模なモデルのトレーニングと推論を短時間で高精度に行うことができます。HBM3eメモリの大幅な容量増加により、より複雑なモデルを扱えるようになり、研究の幅が広がります。
さらに、2枚の「H200 NVL」をNVLink™で接続することにより282GBの広大なメモリ空間を実現。各GPU間は900GB/sの広帯域で疎通可能となり、生成AIのような大規模AIモデルの学習に最適です。
※本製品は消費電力が非常に高くNVIDIAが認定したシステムにのみ搭載可能です。動作認証済のシステムや搭載方法については弊社にご相談下さい。 ※NVLinkでのGPU接続は、NVIDIA H100 NVL を2枚接続する際に有効です。異なるGPUカードとの接続は動作保障外となりますのでご注意下さい。
NVIDIA H100 for PCIe NVIDIA H100 NVL for PCIe NVIDIA H200 NVL for PCIe
アーキテクチャ Hopper
Hopper
Hopper
FP64 24 TFLOPS
30TFLOPS
30 TFLOPS
FP64 Tensor コア 30 TFLOPS
60TFLOPS
60 TFLOPS
FP32 30 TFLOPS
60TFLOPS
60 TFLOPS
TF32 Tensor コア* 395 TFLOPS
835TFLOPS
835 TFLOPS
BFLOAT16 Tensor コア* 395 TFLOPS
1,671TFLOPS
1,671 TFLOPS
FP16 Tensor コア* 1,513 TFLOPS
1,671TFLOPS
1,671 TFLOPS
FP8 Tensor コア* 3,026 TFLOPS
3,341TFLOPS
3,341 TFLOPS
INT8 Tensor コア* 3,026 TOPS
3,341 TOPS
3,341 TFLOPS
GPU メモリ 80 GB HBM2e
94GB HBM3
141GB HBM3e
GPU メモリ帯域幅 2TB/秒
3.9TB/秒
4.8TB/秒
デコーダー 7 NVDEC
7 NVDEC
7 NVDEC
TDP 約350W
350-400W (構成可能)
最大600W(設定可能)
マルチインスタンス GPU 最大 7 個の MIG(第3世代)
各 12GB の最大 14 個の MIG
最大7パーティション(各16.5GB)
フォーム ファクター PCIe Dual Slot
PCIe Dual Slot
PCIe Dual Slot
冷却方法 Passive
Passive
Passive
NVIDIA AI Enterprise 含む(5年間)
含む(5年間)
含む(5年間)
保証 3年
3年
3年
【レンタルでの導入も可能】 GPUレンタルのメリットとして初期投資の削減が可能になります。 高性能なGPUを購入する必要がなく、必要なときだけレンタルできるため、コスト効率をご検討される方にお勧めです。 ご希望の場合、見積もり画面から選択できます。
このカードを搭載したモデルはこちらから
➡【
GSV-IGRAS-4U8G 】【
GSV-ATRSM-5U8G 】
※ジーデップ・アドバンスのサーバー、ワークステーションは最新の高負荷GPUカードが安定して最高のパフォーマンスが発揮できるよう、 NVIDIA社やベアボーンメーカーと連携し、ハードウェア・OS・ミドルウェア・開発ツールまで最適化した形でご提供しています。
大容量で高速なHBM3eメモリによる高いパフォーマンス
NVIDIA Hopper アーキテクチャをベースとする NVIDIA H200 は、毎秒 4.8 テラバイト (TB/s) で 141 ギガバイト (GB) の HBM3eメモリを提供する初の GPU です。
これは、NVIDIA H100 Tensor コア GPU の約 2 倍の容量で、メモリ帯域幅は 1.4 倍です。H200 の大容量かつ高速なメモリは、生成 AI と LLM を加速し、エネルギー効率を向上させ、総所有コストを低減し、HPC ワークロードに最適化されています。
LLM・推論速度がH100と比較して最大 2倍向上
生成AIで話題のLLM(大規模言語モデル)は、文章作成や情報検索など働き方を大きく変えようとしています。大学や企業も、この強力なAIを活用して顧客サービスの向上や新たなビジネスモデルの創出を目指しています。AI 推論アクセラレータは、大規模なユーザーベース向けにデプロイする場合、最小のTCOで最高のスループットを実現する必要があります。
LLMを円滑に稼働させるためには、高性能なコンピュータが必要不可欠です。NVIDIA H200 AIアクセラレータは、この課題を解決する画期的なGPUです。700億パラメータの大規模言語モデル 「Llama2 70B」の推論を前モデルである、NVIDIA H100と比較して1.9倍、1750億パラメータの大規模言語モデル「GPT3-175B」の推論で1.6倍高速化し、LLMの処理速度を最大約2倍に向上させることで、より多くのユーザーに、より迅速かつ高品質なAIサービスを提供することが可能になります。
HPCアプリケーションに対してデータ転送110倍に高速化(対CPU)
NVIDIA H200は、膨大なデータを高速に処理する能力に長けたGPUです。GPUはデータの読み書き速度を示す指標としてメモリ帯域幅があり、H200は前モデルのH100 80GBの2.0TB/s、H100 NVL 94GBの3.9TB/s からさらに進化して4.8TB/s のメモリ帯域をもっています。スーパーコンピューターで複雑な計算を行う場合、大量のデータをメモリーとCPUの間で何度もやり取りが行われるのですが、これがボトルネックとなり計算速度が遅くなってしまうことがあります。
NVIDIA H200は、このボトルネックを解消するために、4.8TB/sと非常に高いメモリ帯域幅を実現しています。データをスムーズにやり取りできるため、シミュレーションやAIの学習など、大規模な計算を短時間で処理することが可能です。
エネルギーとTCOの効率化
NVIDIA H200は、驚異的な性能を発揮しながらも、同時にTCO(総所有コスト)を大幅に削減できる画期的なGPUです。
前世代のH100と同等の電力消費量でありながらはるかに高いパフォーマンスを実現します。AIモデルの学習や、大規模なシミュレーションなど、高度な計算処理を必要とする分野においてこの高いエネルギー効率は、電気料金の削減に直結し、TCOを大幅に抑えることに貢献します。
高いエネルギー効率を実現することで消費電力を削減し環境負荷を軽減します。これは、サステナビリティ社会の実現に向けた重要なファクター言えるでしょう。
NVIDIA AI Enterprise エンタープライズサポートを含む5年のソフトウェアサブスクリプションが付属
NVIDIA H200とNVIDIA AI Enterpriseの組み合わせは、AI 対応プラットフォームの構築が簡素化され、生成AIやコンピュータビジョンなど、多様なAIモデルの開発と導入を加速させ、企業レベルのセキュリティと安定性を確保します。AI開発者は複雑な環境設定に煩わされることなく、AIモデルの開発に集中することができます。
これらの要素が組み合わさることで、企業はAIの導入障壁を下げ、より迅速にビジネスにAIを導入し、競争優位性を確立することができます。
1. Preliminary specifications. May be subject to change.
2. With sparsity.
NVIDIA® RTX PRO 6000 Blackwell Server Edition は、最新GPUアーキテクチャ「Blackwell」を採用した、データセンター向けの次世代GPUです。96GBの大容量GDDR7メモリと最大3.7ペタFLOPSに達するAI演算性能を備え、第5世代Tensorコアと第4世代RTコアにより生成AIや大規模言語モデル(LLM)、エージェントAIの推論処理に最適化されています。前世代のNVIDIA L40Sと比較して、生成AI推論では最大6倍、レンダリングでは最大4倍、エネルギー効率においては最大18倍の性能向上を実現。従来膨大な計算リソースと時間を要した高度なシミュレーションや高精度ビジュアライゼーションも、短時間で実行可能としました。これにより、研究開発、生産設計、映像制作、メタバースなど、あらゆる領域において新たなイノベーションを加速させます。
このカードを搭載したモデルはこちらからGSV-IGRAX-4U8G GSV-ATRSM-5U8G
データセンター向けのパフォーマンスと機能
NVIDIA ® RTX PRO™ Blackwell Server Editionは、AIとビジュアルコンピューティングのための究極のデータセンターGPUであり、マルチモーダルAI推論や物理AIから科学計算、グラフィックス、ビデオアプリケーションまで、最も要求の厳しいエンタープライズワークロードに対して画期的な加速を提供します。前世代L40S比で推論性能最大6倍、レンダリング性能最大4倍、エネルギー効率最大18倍を実現し、LLM推論におけるHGX H100と比較して2倍以上のコストパフォーマンスなど、幅広いエンタープライズワークロードにおいて飛躍的な性能向上を実現します。
Blackwellアーキテクチャの革新
NVIDIA ® RTX PRO™ Blackwell は、AI、グラフィックス、ビデオ処理、データサイエンスなど、多岐にわたる分野で革新的な性能を提供する次世代GPUプラットフォームです。その高度な技術と機能として、第5世代Tensorコアによる最大5倍のLLM推論性能向上とFP4精度サポート、第4世代レイトレーシングコアによる100倍の三角形処理能力とフォトリアルな3D表現が可能です。また、次世代ビデオエンジンによるマルチモーダルAI推論と4:2:2エンコード/デコード対応、GDDR7メモリ(96GB/1.6TB/s)による大規模データ処理を行うことができます。
高帯域で大容量なGDDR7 メモリ
NVIDIA ® RTX PRO™ Blackwell Server Editionは、データセンターでのデプロイに最適化された設計と96GBの超高速GDDR7メモリを備え、パッシブ冷却方式を採用しています。最大8つのGPUをサーバーに搭載可能で、ミッションクリティカルなAIアプリケーションを支え、医療、製造、地質学から小売、メディア、ライブブロードキャストまで幅広い業界でのユースケースを加速します。
PCIe Gen5
NVIDIA RTX PRO™はPCI Express Gen5 をサポートし、PCIe Gen4 の2 倍の速度となるx16 接続で最大64GB/ 秒の帯域幅を実現します。AI やデータサイエンスなどのデータ集約型タスクにおいて、CPU メモリからのデータ転送速度が大幅に向上。更に、PCIe パフォーマンスの向上により、GPU ダイレクトメモリアクセス(DMA)転送、GPUDirect ストレージでの入出力も高速化されます。これらのデータ転送の高速化を通じて、プロフェッショナル向けの計算およびグラフィックス処理をこれまで以上に効率的に行うことができます。
NVIDIA® RTX PRO 6000 Blackwell Server Edition は、最新GPUアーキテクチャ「Blackwell」を採用した、データセンター向けの次世代GPUです。96GBの大容量GDDR7メモリと最大3.7ペタFLOPSに達するAI演算性能を備え、第5世代Tensorコアと第4世代RTコアにより生成AIや大規模言語モデル(LLM)、エージェントAIの推論処理に最適化されています。前世代のNVIDIA L40Sと比較して、生成AI推論では最大6倍、レンダリングでは最大4倍、エネルギー効率においては最大18倍の性能向上を実現。従来膨大な計算リソースと時間を要した高度なシミュレーションや高精度ビジュアライゼーションも、短時間で実行可能としました。これにより、研究開発、生産設計、映像制作、メタバースなど、あらゆる領域において新たなイノベーションを加速させます。
このカードを搭載したモデルはこちらからGSV-IGRAX-4U8G GSV-ATRSM-5U8G
データセンター向けのパフォーマンスと機能
NVIDIA ® RTX PRO™ Blackwell Server Editionは、AIとビジュアルコンピューティングのための究極のデータセンターGPUであり、マルチモーダルAI推論や物理AIから科学計算、グラフィックス、ビデオアプリケーションまで、最も要求の厳しいエンタープライズワークロードに対して画期的な加速を提供します。前世代L40S比で推論性能最大6倍、レンダリング性能最大4倍、エネルギー効率最大18倍を実現し、LLM推論におけるHGX H100と比較して2倍以上のコストパフォーマンスなど、幅広いエンタープライズワークロードにおいて飛躍的な性能向上を実現します。
Blackwellアーキテクチャの革新
NVIDIA ® RTX PRO™ Blackwell は、AI、グラフィックス、ビデオ処理、データサイエンスなど、多岐にわたる分野で革新的な性能を提供する次世代GPUプラットフォームです。その高度な技術と機能として、第5世代Tensorコアによる最大5倍のLLM推論性能向上とFP4精度サポート、第4世代レイトレーシングコアによる100倍の三角形処理能力とフォトリアルな3D表現が可能です。また、次世代ビデオエンジンによるマルチモーダルAI推論と4:2:2エンコード/デコード対応、GDDR7メモリ(96GB/1.6TB/s)による大規模データ処理を行うことができます。
高帯域で大容量なGDDR7 メモリ
NVIDIA ® RTX PRO™ Blackwell Server Editionは、データセンターでのデプロイに最適化された設計と96GBの超高速GDDR7メモリを備え、パッシブ冷却方式を採用しています。最大8つのGPUをサーバーに搭載可能で、ミッションクリティカルなAIアプリケーションを支え、医療、製造、地質学から小売、メディア、ライブブロードキャストまで幅広い業界でのユースケースを加速します。
PCIe Gen5
NVIDIA RTX PRO™はPCI Express Gen5 をサポートし、PCIe Gen4 の2 倍の速度となるx16 接続で最大64GB/ 秒の帯域幅を実現します。AI やデータサイエンスなどのデータ集約型タスクにおいて、CPU メモリからのデータ転送速度が大幅に向上。更に、PCIe パフォーマンスの向上により、GPU ダイレクトメモリアクセス(DMA)転送、GPUDirect ストレージでの入出力も高速化されます。これらのデータ転送の高速化を通じて、プロフェッショナル向けの計算およびグラフィックス処理をこれまで以上に効率的に行うことができます。
NVIDIA® RTX PRO 6000 Blackwell Server Edition は、最新GPUアーキテクチャ「Blackwell」を採用した、データセンター向けの次世代GPUです。96GBの大容量GDDR7メモリと最大3.7ペタFLOPSに達するAI演算性能を備え、第5世代Tensorコアと第4世代RTコアにより生成AIや大規模言語モデル(LLM)、エージェントAIの推論処理に最適化されています。前世代のNVIDIA L40Sと比較して、生成AI推論では最大6倍、レンダリングでは最大4倍、エネルギー効率においては最大18倍の性能向上を実現。従来膨大な計算リソースと時間を要した高度なシミュレーションや高精度ビジュアライゼーションも、短時間で実行可能としました。これにより、研究開発、生産設計、映像制作、メタバースなど、あらゆる領域において新たなイノベーションを加速させます。
このカードを搭載したモデルはこちらからGSV-IGRAX-4U8G GSV-ATRSM-5U8G
データセンター向けのパフォーマンスと機能
NVIDIA ® RTX PRO™ Blackwell Server Editionは、AIとビジュアルコンピューティングのための究極のデータセンターGPUであり、マルチモーダルAI推論や物理AIから科学計算、グラフィックス、ビデオアプリケーションまで、最も要求の厳しいエンタープライズワークロードに対して画期的な加速を提供します。前世代L40S比で推論性能最大6倍、レンダリング性能最大4倍、エネルギー効率最大18倍を実現し、LLM推論におけるHGX H100と比較して2倍以上のコストパフォーマンスなど、幅広いエンタープライズワークロードにおいて飛躍的な性能向上を実現します。
Blackwellアーキテクチャの革新
NVIDIA ® RTX PRO™ Blackwell は、AI、グラフィックス、ビデオ処理、データサイエンスなど、多岐にわたる分野で革新的な性能を提供する次世代GPUプラットフォームです。その高度な技術と機能として、第5世代Tensorコアによる最大5倍のLLM推論性能向上とFP4精度サポート、第4世代レイトレーシングコアによる100倍の三角形処理能力とフォトリアルな3D表現が可能です。また、次世代ビデオエンジンによるマルチモーダルAI推論と4:2:2エンコード/デコード対応、GDDR7メモリ(96GB/1.6TB/s)による大規模データ処理を行うことができます。
高帯域で大容量なGDDR7 メモリ
NVIDIA ® RTX PRO™ Blackwell Server Editionは、データセンターでのデプロイに最適化された設計と96GBの超高速GDDR7メモリを備え、パッシブ冷却方式を採用しています。最大8つのGPUをサーバーに搭載可能で、ミッションクリティカルなAIアプリケーションを支え、医療、製造、地質学から小売、メディア、ライブブロードキャストまで幅広い業界でのユースケースを加速します。
PCIe Gen5
NVIDIA RTX PRO™はPCI Express Gen5 をサポートし、PCIe Gen4 の2 倍の速度となるx16 接続で最大64GB/ 秒の帯域幅を実現します。AI やデータサイエンスなどのデータ集約型タスクにおいて、CPU メモリからのデータ転送速度が大幅に向上。更に、PCIe パフォーマンスの向上により、GPU ダイレクトメモリアクセス(DMA)転送、GPUDirect ストレージでの入出力も高速化されます。これらのデータ転送の高速化を通じて、プロフェッショナル向けの計算およびグラフィックス処理をこれまで以上に効率的に行うことができます。
NVIDIA RTX PRO 5000 72GB Blackwell は、最新のNVIDIA Blackwellアーキテクチャを採用し、72GBの超高速GDDR7メモリと高度なAI演算機能を備えたプロフェッショナル向けGPUです。AI開発やローカルLLM推論、生成AIワークフロー、高精度シミュレーション、3Dモデリング、映像制作といったGPUメモリ使用量が性能を左右するワークロードにおいて、48GB構成を超える明確な余裕を提供します。また72GBの大容量GPUメモリにより、大規模モデルや高解像度3D/映像データをGPU メモリ上に保持したまま処理することが可能となり、モデル分割や頻繁なスワップ処理によるオーバーヘッドを低減。推論、レンダリング、シミュレーションといった計算処理を、より安定したスループットで継続的に実行できます。複数モデルを併用する AI 推論や、巨大な 3D シーンを扱う制作・設計業務においても、メモリ不足による性能変動を抑制します。加えて、PCI Express Gen 5 に対応することでCPU–GPU間のデータ転送帯域を拡張し、大規模データを扱うAI、CAE、データサイエンス用途におけるボトルネックを低減。さらにDisplayPort 2.1 をサポートし、最大16K解像度を含む高解像度・高リフレッシュレート環境を構築可能です。RTX PRO 6000 クラスほどの演算規模や構成を必要としない一方で、48GB構成ではメモリ余力に課題を感じる現場に向けて、本製品は性能、メモリ容量、構成合理性のバランスを重視した“現実的なハイエンド GPU” として、AI・可視化・設計・映像制作ワークフローを効率的に支援します。
大容量72GB GDDR7が支える、安定したプロフェッショナルワークロード
NVIDIA RTX PRO 5000 72GB Blackwellは、72GBの大容量GDDR7メモリを搭載することで、より大規模なAI モデルや高解像度3D データを、メモリ分割や頻繁なスワップ処理を最小限に抑えた状態で扱うことが可能です。モデルの分割実行やデータの退避・再読み込みといったオーバーヘッドを減らすことで、推論・レンダリング・シミュレーションといった処理をより効率的かつ安定して実行できます。特に、ローカルLLMの推論、大規模シーンを扱う3Dモデリング、複数レイヤーを含む高解像度ビデオ編集など、GPUメモリ使用量がボトルネックになりやすいワークロードにおいて、その余裕度が性能の安定性として直結します。また、AI 開発環境、3D制作ツール、解析ソフトウェアなど複数のアプリケーションを同時に使用するプロフェッショナルなワークフローにおいても、メモリ不足によるパフォーマンス低下を抑え、一貫した処理性能を維持します。
最新世代TensorコアとRTコアによる、AI・レイトレーシング処理の実務高速化
最新世代のTensorコアおよびRTコアを搭載することで、AI 推論、生成 AI、レイトレーシング処理を従来世代から大幅に高速化します。FP4などの低精度演算を活用したローカルLLM推論や、生成AIによる画像・映像生成を、実務に耐えるスループットで実行可能です。また、RTコアによる高速なレイトレーシング処理により、AIを活用したレンダリングや可視化処理においても、リアルタイム性と高い描画品質を両立。設計検証、シミュレーション結果の可視化、フォトリアルな3D表現を必要とするワークフローを、ローカル環境で効率的に推進します。
ニューラルシェーダー対応による次世代グラフィックス基盤
最新のSM(Streaming Multiprocessor)およびCUDAコアを搭載することで、前世代と比較して演算効率と処理スループットを大幅に向上。並列処理性能が強化され、AI演算、物理シミュレーション、レンダリングなどの高負荷ワークロードにおいても安定したパフォーマンスを発揮します。さらに、Blackwell世代で導入されたニューラルシェーダーにより、従来のグラフィックスパイプラインにAI処理を直接組み込むことが可能となり、リアルタイム性と表現力を両立した次世代グラフィックス表現を実現。AIを活用した高度な可視化、シミュレーション、インタラクティブな表現を加速します。これにより、現在の業務要件だけでなく、今後拡大が見込まれるAI活用型ワークフローや次世代アプリケーションにも柔軟に対応でき、長期運用を前提としたワークステーション環境においても高い投資対効果を提供します。
PCIe Gen 5とDisplayPort 2.1による、高速データ転送と超高解像度表示
PCI Express Gen 5 に対応することで、CPUとGPU間のデータ転送帯域を大幅に拡張し、大規模データを扱うAI、CAE、データサイエンス用途において高い効果を発揮します。特に、頻繁なデータの入出力やリアルタイム性が求められる処理において、ボトルネックを低減し、計算リソースを最大限に活用することが可能です。さらにDisplayPort 2.1 をサポートし、最大16K解像度を含む超高解像度表示や高リフレッシュレート環境に対応。帯域幅の向上により、複数の高解像度ディスプレイを組み合わせたマルチモニター構成でも安定した表示性能を維持し、設計・解析・映像制作など、情報量の多い作業環境において高い作業効率と快適性を提供します。
実務要件に最適化された現実的ハイエンドポジション
最上位クラスのGPUを導入するほどの演算性能や構成規模は求めていない一方で、48GB構成では大規模モデルや高解像度データの取り扱いにおいて余力不足を感じる。
NVIDIA RTX PRO 5000 Blackwell は、革新的な NVIDIA Blackwell アーキテクチャを採用し、48GB の超高速 GDDR7 メモリと 4,000 AI TOPS の演算性能を搭載したプロフェッショナル向け GPU です。AI 開発、LLM 推論、生成 AI ワークフローから、高精度シミュレーション、ビデオ制作、3D モデリングに至るまで、デスクトップ環境でのあらゆる処理を加速します。ローカル AI アシスタントのシームレスな実行、ニューラルレンダリングによるフォトリアルなビジュアル生成、エンジニアリングや科学研究における高精度なシミュレーションの最適化を、効率的かつスピーディーに実現します。さらに、PCI Express Gen 5 のサポートにより、従来の PCIe Gen 4 と比較して帯域幅が 2 倍に拡張され、CPU メモリからのデータ転送速度が大幅に向上。これにより、AI、データサイエンス、3D モデリングなどデータ集約型タスクのパフォーマンスを飛躍的に高めます。加えて、DisplayPort 2.1 に対応し、240Hz で最大 8K、60Hz で最大 16K の高解像度表示が可能。比類のない視覚的明瞭さと滑らかなパフォーマンスを実現し、マルチタスクや共同作業に理想的なマルチモニター環境を提供します。さらに HDR や高い色深度のサポートにより、ビデオ編集、3D デザイン、ライブ配信などの精密なクリエイティブ作業でも正確な色表現を保証します。
NVIDIA Blackwellアーキテクチャ_第 5 世代の Tensor コア / 第 4 世代の RT コア
NVIDIA RTX PRO 5000 Blackwellにおける第5世代Tensorコアは、前世代と比較して最大3倍のパフォーマンス向上を実現し、FP4精度とDLSS 4マルチフレーム生成技術をサポートしています。これにより、ローカルLLMの高速処理、新しいAIモデルの迅速なプロトタイピング、コンテンツ作成とグラフィックスの品質向上が可能となります。一方、第4世代RTコアは、前世代比で最大2倍の性能を発揮し、M&Eコンテンツの制作、AECO設計、製造プロトタイピングにおけるレンダリング速度を大幅に向上させます。さらに、RTX Mega Geometryのようなニューラルグラフィックス技術を活用することで、レイトレーシングのトライアングル生成が最大100倍まで高速化され、写真のようにリアルで物理的に正確なシーンや臨場感のある3Dデザインを実現できます。
NVIDIA Blackwellアーキテクチャ_CUDA コア /48GB の GPU メモリ
NVIDIA RTX PRO 5000 Blackwellは、最新のSM(Streaming Multiprocessor)およびCUDAコアテクノロジを搭載したモデルです。このSMは、処理スループットの向上を実現し、プログラマブルシェーダー内部にニューラルネットワークを統合する新しいニューラルシェーダーを備えています。これにより、今後10年間にわたるAIを活用したグラフィックスイノベーションが加速されます。さらに、新たに改良されたGDDR7メモリにより、帯域幅と容量が大幅に増加し、アプリケーションの実行速度が向上し、より大規模で複雑なデータセットの処理が可能。48GBのGPUメモリを活用することで、大規模な3DプロジェクトやAIプロジェクトの実行、臨場感のあるVR環境の探索、より大規模なマルチアプリケーションワークフローを推進することができます。
NVIDIA Blackwellアーキテクチャ_第 9 世代の NVENC / 第 6 世代の NVDEC
NVIDIA RTX PRO 5000 Blackwellの第9世代のNVIDIA NVENCエンジンは、4:2:2 H.264およびHEVCエンコーディングのサポートが追加され、プロフェッショナル向けビデオアプリケーションの品質が向上。また、第6世代のNVIDIA NVDECエンジンは、H.264デコードスループットを最大2倍に引き上げ、4:2:2 H.264およびHEVCデコードをサポートしています。これにより、プロフェッショナルユーザーは高品質なビデオ再生、高速なビデオデータ取り込み、そして高度なAIを活用したビデオ編集機能を活用できるようになります。
NVIDIA Blackwellアーキテクチャ_PCIe Gen 5 / DisplayPort 2.1
NVIDIA RTX PRO 5000 Blackwellは、PCI Express Gen 5のサポートにより、PCIe Gen 4と比較して帯域幅が2倍に向上し、CPUメモリからのデータ転送速度が大幅に改善されました。これにより、AI、データサイエンス、3Dモデリングなどのデータ集約型タスクのパフォーマンスが高速化されます。さらに、DisplayPort 2.1を活用することで、プロフェッショナルユーザーは比類のない視覚的な明瞭さとパフォーマンスを実現し、240Hzで最大8K、60Hzで最大16Kの高解像度表示が可能です。帯域幅の増加により、シームレスなマルチモニターセットアップが実現され、マルチタスクや共同作業に最適な環境を提供します。
マルチワークロードの高速化
NVIDIA RTX PRO 5000 Blackwellは、AI 開発・AI を活用したレンダリングとグラフィックス・HPC・ビデオ コンテンツとストリーミング・データサイエンスなど、マルチワークロードにおいて驚異的なピードと品質で高い処理能力を発揮します。
NVIDIA RTX PRO 4500 Blackwell は、32GB の超高速 GDDR7 メモリと革新的な Blackwell アーキテクチャを搭載し、次世代のパフォーマンスを体感できるプロフェッショナル向けグラフィックスカードです。AI を活用した体験を加速し、ワークフローを強化するために設計されており、複雑な設計課題に対応し、ニューラルレンダリング技術を用いて魅力的なビジュアルコンテンツを創造します。さらに、PCI Express Gen 5 のサポートにより、従来の PCIe Gen 4 と比べて帯域幅が 2 倍となり、CPU メモリからのデータ転送速度が大幅に向上。これにより、AI、データサイエンス、3D モデリングなどのデータ集約型タスクにおいても高速かつ効率的な処理が可能です。加えて、DisplayPort 2.1 を備え、240Hz で最大 8K、60Hz で最大 16K の高解像度表示に対応。比類のない視覚的な明瞭さと滑らかなパフォーマンスを実現し、HDR や高い色深度のサポートによって、ビデオ編集、3D デザイン、ライブ配信などの精密なクリエイティブ作業においても正確な色表現を提供します。
NVIDIA Blackwellアーキテクチャ_第 5 世代の Tensor コア / 第 4 世代の RT コア
NVIDIA RTX PRO 4500 Blackwellにおける第5世代Tensorコアは、前世代比で最大3倍のパフォーマンスを実現し、FP4精度とDLSS 4マルチフレーム生成テクノロジのサポートが追加されています。これにより、ローカルLLMの高速化、新しいAIモデルのプロトタイプ作成、コンテンツ作成とグラフィックスの向上が促進されます。また、第4世代RTコアは、前世代比で最大2倍のパフォーマンスを実現し、M&Eコンテンツの作成、AECO設計、製造プロトタイピングにおけるレンダリングを高速化します。さらに、RTX Mega Geometryといったニューラルグラフィックスベースの技術を使用することで、最大100倍のレイトレーシング三角ポリゴンを生成可能にし、写真のようにリアルで物理的に正確なシーンと臨場感のある3Dデザインを作成することができます。
NVIDIA Blackwellアーキテクチャ_CUDA コア /32GB の GPU メモリ
NVIDIA RTX PRO 4500 Blackwellは、最新のSM(Streaming Multiprocessor)およびCUDAコアテクノロジを搭載したモデルです。このSMは、処理スループットの向上を実現し、プログラマブルシェーダー内部にニューラルネットワークを統合する新しいニューラルシェーダーを備えています。これにより、今後10年間にわたるAIを活用したグラフィックスイノベーションが加速されます。また、新たに改良されたGDDR7メモリにより、帯域幅と容量が大幅に向上し、アプリケーションの実行速度が加速され、より大規模で複雑なデータセットの処理が可能になります。32GBのGPUメモリを搭載することで、大規模な3DおよびAIプロジェクトに取り組むことができ、広大なVR環境を探索し、より大きなマルチアプリケーションのワークフローを実現できます。
NVIDIA Blackwellアーキテクチャ_第 9 世代の NVENC / 第 6 世代の NVDEC
NVIDIA RTX PRO 4500 Blackwellの第9世代のNVIDIA NVENCエンジンは、4:2:2 H.264およびHEVCエンコーディングのサポートが追加され、プロフェッショナル向けビデオアプリケーションの品質が向上。また、第6世代のNVIDIA NVDECエンジンは、H.264デコードスループットを最大2倍に引き上げ、4:2:2 H.264およびHEVCデコードをサポートしています。これにより、プロフェッショナルユーザーは高品質なビデオ再生、高速なビデオデータ取り込み、そして高度なAIを活用したビデオ編集機能を活用できるようになります。
NVIDIA Blackwellアーキテクチャ_PCIe Gen 5 / DisplayPort 2.1
NVIDIA RTX PRO 4500 Blackwellは、PCI Express Gen 5のサポートにより、PCIe Gen 4と比較して帯域幅が2倍に向上し、CPUメモリからのデータ転送速度が大幅に改善されました。これにより、AI、データサイエンス、3Dモデリングなどのデータ集約型タスクのパフォーマンスが高速化されます。さらに、DisplayPort 2.1を活用することで、プロフェッショナルユーザーは比類のない視覚的な明瞭さとパフォーマンスを実現し、240Hzで最大8K、60Hzで最大16Kの高解像度表示が可能です。帯域幅の増加により、シームレスなマルチモニターセットアップが実現され、マルチタスクや共同作業に最適な環境を提供します。
マルチワークロードの高速化
NVIDIA RTX PRO 4500 Blackwellは、AI 開発・AI を活用したレンダリングとグラフィックス・HPC・ビデオ コンテンツとストリーミング・データサイエンスなど、マルチワークロードにおいて驚異的なピードと品質で高い処理能力を発揮します。
NVIDIA RTX PRO™ 4000 Blackwell は、AI、ニューラルレンダリング、高精度ワークフロー向けに設計されたシングルスロットGPUです。NVIDIA Blackwell アーキテクチャ、24GB の超高速メモリ、第5世代 Tensor コア、第4世代 RT コアを搭載し、生成AI、3D モデリング、データサイエンスなどの大規模データ処理を高速化。複雑なワークフローにも安定したパフォーマンスを発揮します。
さらに、PCI Express Gen 5に 対応することで、従来の PCIe Gen 4 と比べて帯域幅が 2 倍に向上し、CPU メモリとの高速データ転送を実現。これにより、データ集約型タスクでの作業効率が大幅に向上します。
また、DisplayPort 2.1 による 8K/240Hz、16K/60Hz の高解像度表示に対応。HDR や高色深度のサポートにより、ビデオ編集、3D デザイン、ライブ配信などの精密作業でも優れた色精度を保証します。帯域幅の向上と高性能表示の組み合わせにより、マルチモニター環境でのマルチタスクやチームでの共同作業もスムーズに行えます。
NVIDIA Blackwellアーキテクチャ_第 5 世代の Tensor コア / 第 4 世代の RT コア
NVIDIA RTX PRO™ 4000 Blackwellの第5世代Tensorコアは、前世代と比較して最大3倍のパフォーマンス向上を実現し、FP4精度とDLSS 4マルチフレーム生成技術をサポートしています。これにより、ローカルLLMの高速処理、新しいAIモデルの迅速なプロトタイピング、コンテンツ作成とグラフィックスの品質向上が可能となります。一方、第4世代RTコアは、前世代比で最大2倍の性能を発揮し、M&Eコンテンツの制作、AECO設計、製造プロトタイピングにおけるレンダリング速度を大幅に向上させます。さらに、RTX Mega Geometryのようなニューラルグラフィックス技術を活用することで、レイトレーシングのトライアングル生成が最大100倍まで高速化され、写真のようにリアルで物理的に正確なシーンや臨場感のある3Dデザインを実現できます。
NVIDIA Blackwellアーキテクチャ_CUDA コア / 24 GB の GPU メモリ
NVIDIA RTX PRO™ 4000 Blackwellは、最新のSM(Streaming Multiprocessor)およびCUDAコアテクノロジを搭載したプロフェッショナル向けです。このSMは、処理スループットの向上を実現し、プログラマブルシェーダー内部にニューラルネットワークを統合する新しいニューラルシェーダーを備えています。これにより、今後10年間にわたるAIを活用したグラフィックスイノベーションが加速されます。さらに、新たに改良されたGDDR7メモリにより、帯域幅と容量が大幅に増加し、アプリケーションの実行速度が向上し、より大規模で複雑なデータセットの処理が可能。24GBのGPUメモリを活用することで、大規模な3DプロジェクトやAIプロジェクトの実行、臨場感のあるVR環境の探索、より大規模なマルチアプリケーションワークフローを推進することができます。
NVIDIA Blackwellアーキテクチャ_第 9 世代の NVENC / 第 6 世代の NVDEC
NVIDIA RTX PRO™ 4000 Blackwellの第9世代のNVIDIA NVENCエンジンは、4:2:2 H.264およびHEVCエンコーディングのサポートが追加され、プロフェッショナル向けビデオアプリケーションの品質が向上。また、第6世代のNVIDIA NVDECエンジンは、H.264デコードスループットを最大2倍に引き上げ、4:2:2 H.264およびHEVCデコードをサポートしています。これにより、プロフェッショナルユーザーは高品質なビデオ再生、高速なビデオデータ取り込み、そして高度なAIを活用したビデオ編集機能を活用できるようになります。
NVIDIA Blackwellアーキテクチャ_PCIe Gen 5 / DisplayPort 2.1
NVIDIA RTX PRO™ 4000 Blackwellは、PCI Express Gen 5のサポートによりPCIe Gen 4と比較して帯域幅が2倍に向上し、CPUメモリからのデータ転送速度が大幅に改善されました。これにより、AI、データサイエンス、3Dモデリングなどのデータ集約型タスクにおけるパフォーマンスが高速化されます。さらに、DisplayPort 2.1の採用により、プロフェッショナルは比類のない視覚的な明瞭さとパフォーマンスを得ることができ、240Hzで最大8K、60Hzで最大16Kの高解像度表示が可能です。帯域幅の増加により、シームレスなマルチモニター環境が実現され、マルチタスクや共同作業に最適な環境を提供します。加えて、HDRや高色深度のサポートにより、ビデオ編集、3Dデザイン、ライブ配信などの精密な作業においても高い色精度が確保されます。
マルチワークロードの高速化
NVIDIA RTX PRO™ 4000 Blackwellは生成AI・AIを活用したレンダリングとグラフィックス・デジタルコンテンツ制作・ビデオコンテンツとストリーミング・データサイエンスなど、マルチワークロードにおいて驚異的なピードと品質で高い処理能力を発揮します。
NVIDIA RTX PRO™ 4000 Blackwell SFF Editionは、最新のNVIDIA Blackwellアーキテクチャを基盤に、第5世代Tensorコア、第4世代RTコア、最新世代CUDAコアを統合した高性能GPUです。AI推論、リアルタイムレイトレーシング、高精度な数値演算処理を単一GPUで効率的に実行でき、3D設計、可視化、データ解析、AI開発など多様化するワークロードに対応します。FP4精度に対応したTensorコアは量子化モデルの推論効率を高め、生成AIやローカルLLMの処理を高速化。第4世代RTコアはレイトレーシング処理のスループットを向上させ、高忠実度ビジュアルをリアルタイムで生成します。さらに、24GBの高速GDDR7メモリにより大規模データや複雑な3Dシーンにも安定して対応。Small Form Factor設計により、省スペース環境や設置制約のあるワークステーションへの柔軟な導入を可能にし、限られた筐体サイズの中で妥協のない演算性能と拡張性を実現します。
Blackwellアーキテクチャによる統合型高性能GPU基盤
NVIDIA Blackwellアーキテクチャを採用し、第5世代Tensorコア、第4世代RTコア、最新世代CUDAコアを統合。高度化したSM設計と並列処理性能により、AI推論、リアルタイムレイトレーシング、高精度な数値演算処理を単一GPUで効率的に実行可能です。複数の演算パイプラインを同時に扱う複合ワークロードにも柔軟に対応し、GPUリソースを最大限に活用します。3D設計、可視化、データ解析、AI開発など多様化・高度化するプロフェッショナル用途に対して、安定性と拡張性を兼ね備えたバランスの取れた高い演算性能を提供し、ワークステーション環境の生産性向上に貢献します。
24GB GDDR7メモリによる大規模データ処理対応
第4世代RTコアを搭載し、レイ・トライアングル交差判定およびバウンディングボリューム階層(BVH)処理の効率を向上。前世代と比較してレイトレーシング処理のスループットが大幅に強化され、複雑なジオメトリや高密度メッシュを含むシーンでも安定したリアルタイム描画が可能です。同時にレイトレーシングとシェーディング処理を並列実行できる設計により、設計可視化やプロダクトレビュー環境において高忠実度ビジュアルを低レイテンシで生成します。さらにニューラルレンダリング技術との統合により、AIベースのデノイズやアップスケーリングを活用し、計算負荷を最適化しながら画質と応答性を両立します。
リアルタイムレイトレーシングとニューラルレンダリング
第4世代RTコアにより、フォトリアルなレイトレーシング処理を大幅に高速化。レイ・トライアングル交差判定やBVH処理の効率が向上し、複雑なジオメトリや高精度マテリアルを含むシーンでも安定したリアルタイム描画を実現します。設計レビュー、VFX制作、プロダクトビジュアライゼーション、科学可視化などのワークフローにおいて、物理的に正確なライティングや反射・屈折表現を即座に確認可能です。さらにAIを活用したニューラルレンダリング技術との組み合わせにより、デノイズやアップスケーリング処理を効率化し、画質向上と計算負荷の最適化を両立します。
AIおよび高度演算ワークロードへの最適化
第5世代TensorコアはFP4精度に対応し、量子化モデルの推論効率を高めながら高いスループットを実現します。生成AI、ローカルLLM、シミュレーション支援AIなどの推論処理を高速化し、長文コンテキスト処理や複雑なプロンプトチェーンにも安定して対応します。設計支援、自動化ワークフロー、データ分析、画像処理など幅広い分野でAI機能を活用でき、開発・検証サイクルの短縮と生産性向上に貢献します。さらに、AI推論とリアルタイムグラフィックス処理を同時に実行する複合ワークロードにも柔軟に対応し、GPUリソースを効率的に活用できます。
コンパクトSFF設計による柔軟な導入性
Small Form Factor設計により、省スペースワークステーションや設置制約のある環境への柔軟な導入が可能です。限られた筐体スペースや電力条件の中でも高い演算性能を維持できる設計となっており、既存のデスクトップ環境への組み込みにも適しています。オフィス用途から研究開発部門、設計現場、さらにはエッジコンピューティング環境まで幅広いシーンで高性能GPU基盤を構築可能です。大規模サーバーを必要とせず、部門単位での高密度GPU導入や分散型ワークステーション構成を実現し、限られた筐体サイズの中で妥協のない性能と拡張性を提供します。
NVIDIA RTX™ 4000 SFF Ada 世代は、プロフェッショナルが求める機能、性能、そしてコンパクトなデザインで大きな効果をもたらすことができます。NVIDIA Ada Lovelace アーキテクチャを採用し、コンパクトでパワフルな RTX 4000 SFF は、第 3 世代の RT コア、第 4 世代の Tensor コア、次世代 CUDA® コアと 20GB のグラフィックス メモリを組み合わせ、優れたレンダリング、AI、グラフィックス、コンピューティング ワークロード性能を実現します。
NVIDIA Ada Lovelace アーキテクチャ採用の CUDA コア
単精度浮動小数点 (FP32) 演算を前世代の 2 倍に高速化したことで、デスクトップ PC において、複雑な 3D コンピューター支援設計 (CAD) や、コンピューター支援エンジニアリング (CAE) などのグラフィックスやシミュレーションのワークフローの性能を大幅に向上します。
第 3 世代 RT コア
前世代と比較して最大 2 倍のスループットを実現した第 3 世代 RT コアは、動画コンテンツのフォトリアルなレンダリング、建築デザインの評価、製品デザインの仮想プロトタイピングなどのワークロードにおいて、大規模な高速化を実現します。また、このテクノロジにより、レイトレーシングされたモーション ブラー レンダリングを高速化し、ビジュアル精度が向上します。
第 4 世代 Tensor コア
第 4 世代の Tensor コアは、より高速な AI コンピューティング性能を提供し、前世代の 2 倍以上の性能を実現します。これらの新しい Tensor コアは、FP8 精度データ型の高速化をサポートし、独立した浮動小数点と整数のデータ パスを提供し、浮動小数点と整数の混合演算の実行をスピードアップします。
20 ギガバイト (GB) の GPU メモリ
20GB GDDR6 メモリを搭載した RTX 4000 SFF は、データ サイエンティスト、エンジニア、クリエイターが、レンダリング、データ サイエンス、シミュレーションなどで、大規模データセットやワークロードを扱うために必要な大容量メモリを提供します。
AV1 エンコーダー
Ada アーキテクチャベースの RTX 4000 SFF は、AV1 エンコーディングと共に第 8 世代専用ハードウェア エンコーダー (NVENC) を備え、ストリーミング サービス、放送局、ビデオ会議の新しい可能性を解き放ちます。H.264 よりも 40% 効率的で、1080p でストリーミングしているユーザーは、同じビットレートと品質で実行しながら、ストリーミングの解像度を 1440p まで上げることができます。
【同梱物】
NVIDIA RTX4000 SFF Ada BULK版
※ATXブラケットが装着されており、Low-profileブラケットが付属します
NVIDIA RTX4000 SFF Ada NVBOX版
※Low-profileブラケットが装着されており、ATXブラケットが付属します
NVIDIAエリートパートナ ジーデップ・アドバンスはGTC2022で発表された 最新ハイエンドGPU NVIDIA® RTX™ A5500 の取り扱いを開始しました。
※ジーデップ・アドバンスなら購入はもちろん 長期レンタル でもトータルコストが大きく変わらずおトクです。
NVIDIA RTX™ A5500 グラフィックス カードでデスクトップ PC のパワーを開放しよう。高い処理能力が要求されるマルチアプリケーション ワークフローに必要なパフォーマンス、信頼性、機能を提供します。NVIDIA Ampere アーキテクチャに基づいて構築され、24GBのGPUメモリを搭載したこのカードは、デザイナー、エンジニア、サイエンティスト、アーティストの無限の創造力に必要なものをすべて備えています。 【NVIDIA RTX製品比較】
RTX A6000 RTX A5500 RTX A5000 RTX A4500 RTX A4000
Ampere
Ampere
Ampere
Ampere
Ampere
48GB GDDR6
24GB GDDR6
24GB GDDR6
20GB GDDR6
16GB GDDR6
最大768GB/s
最大768GB/s
最大768GB/s
最大640GB/s
最大512GB/s
384bit
384bit
384bit
384bit
384bit
10752 CUDAコア
10240 CUDAコア
8192 CUDAコア
7168 CUDAコア
6144 CUDAコア
336 Tensorコア
320 Tensorコア
256 Tensorコア
224 Tensorコア
192 Tensorコア
84 RTコア
80 RTコア
64 RTコア
56 RTコア
48 RTコア
PCI Express 4.0 x16
PCI Express 4.0 x16
PCI Express 4.0 x16
PCI Express 4.0 x16
PCI Express 4.0 x16
NVLink対応
NVLink対応
NVLink対応
NVLink 対応
NVLink 非対応
TDP 300W
TDP 230W
TDP 230W
TDP 200W
TDP 140W
アクティブ冷却
アクティブ冷却
アクティブ冷却
アクティブ冷却
アクティブ冷却
GPUワークステーション も特別価格でご提供しています。
-国内正規流通品について- NVIDIA認定パートナー ジーデップ・アドバンスが扱っているNVIDIA社製GPUカードは全て「国内正規流通品」です。並行輸入品や組込向けのバルク品ではありません。並行輸入品には国内代理店の保証書が添付されておらず国内での保証修理が受けられません。そのため修理や交換に通常よりも長い時間を要します。またメーカー出荷時から時間が経過しており保証期間が短くなっている場合が多く、販売店が独自で交換保証を付ける等の対応を行っているケースもあります。 加えて並行輸入品は以下の様な正規代理店対応も受けられませんのでご注意下さい。 ・輸出関連資料の対応 非該当判定用パラメーターシートや米国輸出関連資料作成 ・環境物質資料の対応 RoHS2,REACH,SVHC その他大学研究機関定型形式での資料作成 ・紛争鉱物(コンフリクトミネラル)調査資料の対応 ・ドライバーのバグなどクリティカルな不具合に関するメーカーリレーションとその対応 ご購入の際には安心の国内正規流通品をお勧め致します。
NVIDIAエリートパートナ ジーデップ・アドバンスはGTC2022で発表された 最新ハイエンドGPU NVIDIA® RTX™ A5500 の取り扱いを開始しました。
※ジーデップ・アドバンスなら購入はもちろん 長期レンタル でもトータルコストが大きく変わらずおトクです。
NVIDIA RTX™ A5500 グラフィックス カードでデスクトップ PC のパワーを開放しよう。高い処理能力が要求されるマルチアプリケーション ワークフローに必要なパフォーマンス、信頼性、機能を提供します。NVIDIA Ampere アーキテクチャに基づいて構築され、24GBのGPUメモリを搭載したこのカードは、デザイナー、エンジニア、サイエンティスト、アーティストの無限の創造力に必要なものをすべて備えています。 【NVIDIA RTX製品比較】
RTX A6000 RTX A5500 RTX A5000 RTX A4500 RTX A4000
Ampere
Ampere
Ampere
Ampere
Ampere
48GB GDDR6
24GB GDDR6
24GB GDDR6
20GB GDDR6
16GB GDDR6
最大768GB/s
最大768GB/s
最大768GB/s
最大640GB/s
最大512GB/s
384bit
384bit
384bit
384bit
384bit
10752 CUDAコア
10240 CUDAコア
8192 CUDAコア
7168 CUDAコア
6144 CUDAコア
336 Tensorコア
320 Tensorコア
256 Tensorコア
224 Tensorコア
192 Tensorコア
84 RTコア
80 RTコア
64 RTコア
56 RTコア
48 RTコア
PCI Express 4.0 x16
PCI Express 4.0 x16
PCI Express 4.0 x16
PCI Express 4.0 x16
PCI Express 4.0 x16
NVLink対応
NVLink対応
NVLink対応
NVLink 対応
NVLink 非対応
TDP 300W
TDP 230W
TDP 230W
TDP 200W
TDP 140W
アクティブ冷却
アクティブ冷却
アクティブ冷却
アクティブ冷却
アクティブ冷却
GPUワークステーション も特別価格でご提供しています。
-国内正規流通品について- NVIDIA認定パートナー ジーデップ・アドバンスが扱っているNVIDIA社製GPUカードは全て「国内正規流通品」です。並行輸入品や組込向けのバルク品ではありません。並行輸入品には国内代理店の保証書が添付されておらず国内での保証修理が受けられません。そのため修理や交換に通常よりも長い時間を要します。またメーカー出荷時から時間が経過しており保証期間が短くなっている場合が多く、販売店が独自で交換保証を付ける等の対応を行っているケースもあります。 加えて並行輸入品は以下の様な正規代理店対応も受けられませんのでご注意下さい。 ・輸出関連資料の対応 非該当判定用パラメーターシートや米国輸出関連資料作成 ・環境物質資料の対応 RoHS2,REACH,SVHC その他大学研究機関定型形式での資料作成 ・紛争鉱物(コンフリクトミネラル)調査資料の対応 ・ドライバーのバグなどクリティカルな不具合に関するメーカーリレーションとその対応 ご購入の際には安心の国内正規流通品をお勧め致します。
生成AIの爆発的な普及により、あらゆる業界で大規模なコンピューティングリソースを導入する必要性が高まっています。パフォーマンス、効率、ROI*[1]向上のため、現代のデータセンターには、複雑なワークロード、高速コンピューティング、グラフィックス、ビデオ処理機能を提供する技術が必要です。
NVIDIA L40Sは、データセンター向けの最も強力なユニバーサルGPUであり、推論とトレーニング、グラフィックス、およびビデオアプリケーションに対して高性能かつ高速な処理を実現します。マルチモーダル*[2]生成 AI のプレミアプラットフォームとして、推論、トレーニング、グラフィックス、ビデオワークフローのエンドtoエンドでの高速処理を可能にし、次世代の AI 対応オーディオ、音声、ビデオ、2Dおよび 3D アプリケーションを強化します。
*[1] Return On Investment(投資利益率)。事業や施策において、投下した資本に対しての収益性を図る指標のこと。 *[2] Multi(複数)とModal(様式)を組み合わせたコンピューター用語。さまざまな種類の情報を利用して高度な判断を行うAIを指す。 GPU リソースの安定確保にむけて 現在、世界的なGPUの急激な需要増加によってNVIDIA H100やNVIDIA A100などのデータセンターGPUの納期が非常に長期化している状況です。ジーデップ・アドバンスでは NVIDIA A100を凌駕したAIトレーニングパフォーマンスを誇る新製品 NVIDIA L40S を搭載した製品ラインナップを増強し、多彩なポートフォリオでお客様のご要望にお応えして参ります。
GPUリソースの安定確保にむけて
NVIDIA L40S 製品 仕様比較
L40S
A100 80GB SXM
GPU Architecture
NVIDIA Ada Lovelace
NVIDIA Ampere
FP64
N/A
9.7 TFLOPS
FP32
91.6 TFLOPS
19.5 TFLOPS
RT Core
212 TFLOPS
N/A
TF32 TensorCore*
366 TFLOPS
312 TFLOPS
FP16/BF16 Tensor Core*
733 TFLOPS
624 TFLOPS
FP8 Tensor Core*
1466 TFLOPS
N/A
INT8 Tensor Core*
1466 TOPS
1248 TOPS
GPU Memory
48 GB GDDR6
80 GB HBM2e
GPU Memory Bandwidth
864 GB/s
2039 GB/s
L2 Cache
96 MB
40 MB
Power
Up to 350 W
Up to 400 W
Form Factor
2-slot FHFL
8-way HGX
Interconnect
PCIe Gen4 x16: 64 GB/s
PCIe Gen4 x16: 64 GB/s
強力なAIパフォーマンス
第4世代TensorコアとTransformer Engine、新しい半精度性能(FP8)フォーマットは、NVIDIA A100 Tensor Core GPUの推論性能を最大1.5倍上回ります。18,176個のNVIDIA Ada Lovelace GPUアーキテクチャーCUDA® コアを搭載し、A100の約5倍の単精度性能 (FP32)を提供します。
次世代グラフィックス機能
142基の第3世代RTコアと48GBのGDDR6メモリーにより、NVIDIA Ampereアーキテクチャー世代の最大2倍のリアルタイムレイトレーシング性能を実現し、美しく詳細なモデルやシーンの作成や、より忠実なグラフィックスを可能にします。
企業向けデータセンター対応
L40S GPU は、24 時間 365 日稼動するエンタープライズ データ センター運用に最適化されており、最大限のパフォーマンス、耐久性、アップタイムを確保するために、NVIDIA によって設計、構築、テスト、サポートされています。L40S GPU は最新のデータ センター標準を満たし、NEBS (Network Equipment-Building System) レベル 3 に対応し、Root of Trust 技術によるセキュア ブートを備え、データ センターにさらなるセキュリティ層を提供します。
DLSS3
L40S GPU は、NVIDIA DLSS 3 により超高速のレンダリングと滑らかなフレーム レートを可能にします。この画期的なフレーム生成技術は、Ada Lovelace アーキテクチャと L40S GPU のディープラーニングと最新のハードウェア イノベーション (第 4 世代 Tensor コアやオプティカル フロー アクセラレータなど) を活用し、レンダリング性能を高め、FPS (フレーム毎秒) を上げ、レイテンシを大幅に改善します。
400G NDR対応カード:ConnectX-7 InfiniBand アダプターは、超低レイテンシ400Gb / sスループット、革新的なNVIDIA In-Network Computingアクセラレーション エンジンを提供し、ハイパフォーマンスコンピューティング(HPC)、人工知能(AI)、ハイパースケールクラウドデータセンターに必要なスケーラビリティと機能豊富なテクノロジーを利用して、さらなる高速化を実現するカードです。
QM9700シリーズ - メラノックスQuantum 2 NDR 400Gb/s InfiniBandスマートスイッチ
QM9700シリーズ - メラノックスQuantum 2 NDR 400Gb/s InfiniBandスマートスイッチ
QMSB7800シリーズ – SWITCH-IB EDR 100Gb/s InfiniBand スマートスイッチ
NVIDIA MELLANOX
36-ポート ノンブロッキング管理型EDR 100Gb/s InfiniBand(インフィニバンド) スマートスイッチ
スイッチ仕様
・IBTA 1.2/1.3準拠
管理ポート
・10/100/1000 Ethernet(イーサネット) ポート
ファブリック管理機能
・最大2,000ノードのファブリック管理に対応したオンボードSubnet Manager
コネクタとケーブル
・QSFP28コネクタ
インジケータ
・ポート別のリンク/稼働状態表示用LED
物理仕様
・サイズ:4.4cm(高さ)x 42.8cm(幅) x 68.6cm(奥行)
パワーサプライ
・冗長電源用デュアルスロット
冷却装置
・正面から背面あるいは背面から正面へのエアフローによる冷却オプション
消費電力
・ATIS仕様に基づく消費電力:136W
発注型番
Managed
ポート
最大転送
電源
FRU
エア
筐体の
MSB7800-ES2F
○
36
EDR
2
Yes
P2C
Standard
MSB7800-ES2R
C2P
MSB7890-ES2F
×
P2C
MSB7890-ES2R
C2P
QMSB7800シリーズ – SWITCH-IB EDR 100Gb/s InfiniBand スマートスイッチ
NVIDIA MELLANOX
36-ポート ノンブロッキング管理型EDR 100Gb/s InfiniBand(インフィニバンド) スマートスイッチ
スイッチ仕様
・IBTA 1.2/1.3準拠
管理ポート
・10/100/1000 Ethernet(イーサネット) ポート
ファブリック管理機能
・最大2,000ノードのファブリック管理に対応したオンボードSubnet Manager
コネクタとケーブル
・QSFP28コネクタ
インジケータ
・ポート別のリンク/稼働状態表示用LED
物理仕様
・サイズ:4.4cm(高さ)x 42.8cm(幅) x 68.6cm(奥行)
パワーサプライ
・冗長電源用デュアルスロット
冷却装置
・正面から背面あるいは背面から正面へのエアフローによる冷却オプション
消費電力
・ATIS仕様に基づく消費電力:136W
発注型番
Managed
ポート
最大転送
電源
FRU
エア
筐体の
MSB7800-ES2F
○
36
EDR
2
Yes
P2C
Standard
MSB7800-ES2R
C2P
MSB7890-ES2F
×
P2C
MSB7890-ES2R
C2P
「NVIDIA A800 40GB Active」は、デスクサイド環境でありながらNVIDIA Ampereアーキテクチャを搭載した倍精度コンピューティングのサポートによりHPCアプリケーションに対して、最大9.7TFLOPSの FP64性能を発揮します。
さらに40GB HBMGPUに加えGPU間を第3世代NV Linkにより400GB/s高速インターコネクトで接続とマルチインスタンスGPU(MIG)による、マルチテナントによるGPUリソースの分割利用が可能になります。
また、「NVIDIA A800 40GB Active」は、デスクサイド ワークステーションにマルチGPU利用してコンピューティングパフォーマンスを高め、AI学習性能、AI推論、CSM(個体力学)、流体力学(CFD)、電磁気学 等のCAEのシュミレーション性能向上により計算時間を縮めます。
尚、本製品には、3年間のNVIDIA AI Enterprise のサブスクリプションが提供されます。
【NVIDIA@ A100 vs A800 比較】
仕様
A100 40GB PCIe
A800 40GB Active
GPUメモリー
40GB HBM2
メモリーインターフェース
5120-bit
メモリー帯域幅
1555.2 GB/s
CUDA コア
6912
Tensor コア
432
倍精度(64)演算性能
9.7 TFLOPS
単精度(32)演算性能
19.5 TFLOPS
マルチインスタンス GPU
最大7MIG
NVIDIA NVLink
Yes(×3)
Yes(×2)
NVLink 帯域幅
600GB/s
400GB/s
システムインターフェース
PCIe 4.0×16
消費電力
250W
240W
サーマル
Passive
Active
フォームファクタ
4.4"H×10.5" L -デュアルスロット
ディスプレイ対応
出力無し
電力供給コネクタ形状
1×CPU-8pin
1x PCIe CEM5 16-pin
重さ
1240g
1182g
カタログダウンロードは
こちら から
Ampereアーキテクチャを採用
NVIDIA Ampere アーキテクチャをベースにした NVIDIA A8000 GPU は、Ampereアーキテクチャ(GA102)を採用し 6912基のCUDAコアを搭載、B倍 精度浮動小数点 (FP64) 演算により最大 9.7 TFLOPS および単精度浮動小数点 (FP32) 演算の倍速処理により 19.5 TFLOPSの性能をサポートします。そのほかに 数多くの新しいアーキテクチャ機能と最適化により、AI や HPC のコンピューティング能力を最大限に提供できるように設計されています。
第3世代 Tensor コア
倍精度(FP64)およびTensor Float 32(TF32)精度のサポートにより、幅広いAIおよびHPCアプリケーションに対応する性能と汎用性を備え、旧世代と比較して性能と効率が最大2倍向上。構造的スパース性をハードウェアでサポートすることで、推論のスループットが2倍に向上。
マルチインスタンス GPU (MIG)
新しいマルチインスタンス GPU (MIG) 機能を使用すると、Tensor コア GPU を CUDA アプリケーション用に最大 7 つの GPU インスタンスに安全にパーティショニングすることができ、複数のユーザーに別々の GPU リソースを提供してアプリケーションや開発プロジェクトを高速化できます。 MIG を使用すると、各インスタンスのプロセッサに対して、メモリ システム全体を通るパスが個別に提供されます。つまり、オンチップのクロスバー ポート、L2 キャッシュ バンク、メモリ コントローラー、DRAM アドレス バスがすべて、個々のインスタンスに一意に割り当てられます。これにより L2 キャッシュの割り当てと DRAM 帯域幅がどのユーザーも同じになるため、あるユーザーのタスクがキャッシュのスラッシングを起こしていたり、DRAM インターフェイスを飽和させたりしていても、他のユーザーのワークロードは予測可能なスループットとレイテンシで実行できるようになります。
40 GB の HBM2 大容量メモリ
大量のコンピューティング スループットを提供するために、クラス最高の 1,555 GB/秒のメモリ帯域幅を持つ 40 GB の高速 HBM2 メモリを搭載しています。メモリ帯域幅は 前世代と比較して 73% 増加しています。さらにコンピューティング パフォーマンスを最大化するために、40 MB のレベル 2 (L2) キャッシュ (Volta の約 7 倍) を含め、はるかに多くのオンチップ メモリを搭載しています。
PCI Express Gen 4
PCI Express Gen3 の 2倍の帯域幅を提供する PCI Express Gen4 対応したことにより AI やデータサイエンスなどのデータ集約型タスク向けに CPU メモリからのデータ転送速度が向上します。
「NVIDIA A800 40GB Active」は、デスクサイド環境でありながらNVIDIA Ampereアーキテクチャを搭載した倍精度コンピューティングのサポートによりHPCアプリケーションに対して、最大9.7TFLOPSの FP64性能を発揮します。
さらに40GB HBMGPUに加えGPU間を第3世代NV Linkにより400GB/s高速インターコネクトで接続とマルチインスタンスGPU(MIG)による、マルチテナントによるGPUリソースの分割利用が可能になります。
また、「NVIDIA A800 40GB Active」は、デスクサイド ワークステーションにマルチGPU利用してコンピューティングパフォーマンスを高め、AI学習性能、AI推論、CSM(個体力学)、流体力学(CFD)、電磁気学 等のCAEのシュミレーション性能向上により計算時間を縮めます。
尚、本製品には、3年間のNVIDIA AI Enterprise のサブスクリプションが提供されます。
【NVIDIA@ A100 vs A800 比較】
仕様
A100 40GB PCIe
A800 40GB Active
GPUメモリー
40GB HBM2
メモリーインターフェース
5120-bit
メモリー帯域幅
1555.2 GB/s
CUDA コア
6912
Tensor コア
432
倍精度(64)演算性能
9.7 TFLOPS
単精度(32)演算性能
19.5 TFLOPS
マルチインスタンス GPU
最大7MIG
NVIDIA NVLink
Yes(×3)
Yes(×2)
NVLink 帯域幅
600GB/s
400GB/s
システムインターフェース
PCIe 4.0×16
消費電力
250W
240W
サーマル
Passive
Active
フォームファクタ
4.4"H×10.5" L -デュアルスロット
ディスプレイ対応
出力無し
電力供給コネクタ形状
1×CPU-8pin
1x PCIe CEM5 16-pin
重さ
1240g
1182g
カタログダウンロードは
こちら から
Ampereアーキテクチャを採用
NVIDIA Ampere アーキテクチャをベースにした NVIDIA A8000 GPU は、Ampereアーキテクチャ(GA102)を採用し 6912基のCUDAコアを搭載、B倍 精度浮動小数点 (FP64) 演算により最大 9.7 TFLOPS および単精度浮動小数点 (FP32) 演算の倍速処理により 19.5 TFLOPSの性能をサポートします。そのほかに 数多くの新しいアーキテクチャ機能と最適化により、AI や HPC のコンピューティング能力を最大限に提供できるように設計されています。
第3世代 Tensor コア
倍精度(FP64)およびTensor Float 32(TF32)精度のサポートにより、幅広いAIおよびHPCアプリケーションに対応する性能と汎用性を備え、旧世代と比較して性能と効率が最大2倍向上。構造的スパース性をハードウェアでサポートすることで、推論のスループットが2倍に向上。
マルチインスタンス GPU (MIG)
新しいマルチインスタンス GPU (MIG) 機能を使用すると、Tensor コア GPU を CUDA アプリケーション用に最大 7 つの GPU インスタンスに安全にパーティショニングすることができ、複数のユーザーに別々の GPU リソースを提供してアプリケーションや開発プロジェクトを高速化できます。 MIG を使用すると、各インスタンスのプロセッサに対して、メモリ システム全体を通るパスが個別に提供されます。つまり、オンチップのクロスバー ポート、L2 キャッシュ バンク、メモリ コントローラー、DRAM アドレス バスがすべて、個々のインスタンスに一意に割り当てられます。これにより L2 キャッシュの割り当てと DRAM 帯域幅がどのユーザーも同じになるため、あるユーザーのタスクがキャッシュのスラッシングを起こしていたり、DRAM インターフェイスを飽和させたりしていても、他のユーザーのワークロードは予測可能なスループットとレイテンシで実行できるようになります。
40 GB の HBM2 大容量メモリ
大量のコンピューティング スループットを提供するために、クラス最高の 1,555 GB/秒のメモリ帯域幅を持つ 40 GB の高速 HBM2 メモリを搭載しています。メモリ帯域幅は 前世代と比較して 73% 増加しています。さらにコンピューティング パフォーマンスを最大化するために、40 MB のレベル 2 (L2) キャッシュ (Volta の約 7 倍) を含め、はるかに多くのオンチップ メモリを搭載しています。
PCI Express Gen 4
PCI Express Gen3 の 2倍の帯域幅を提供する PCI Express Gen4 対応したことにより AI やデータサイエンスなどのデータ集約型タスク向けに CPU メモリからのデータ転送速度が向上します。
4Uラックマウント筐体にトップローディングで最大60基のストレージを搭載可能な大容量ファイルサーバー。第二世代Xeon® Scalable Family を2基とBroadcomのRAIDコントローラーを搭載。RIADレベル 0, 1, 5, 6, 10,50,60 に対応しエンタープライズクラスの高信頼性ストレージとの組み合わせはミッションクリティカルなシーンでも安定した利用が可能です。インターコネクトも標準で10GBase-Tを2ポート、オプションでInfiniBand(EDR)も増設可能ですので、高速広帯域なノード間通信やフレキシブルなストレージ増設にも対応しています。さらにOS冗長化や高速インターコネクトで高い堅牢性と拡張性を実現しています。
VIDEO
トップローディングで最大60基のストレージを搭載可能
筐体フロントからトレーを引き出しトップからストレージを脱着するトップローディングアーキテクチャを採用。特別な工具を使用することなく高いメンテナンス性を提供します。ストレージの内部ケーブルを廃し、背面外部インターフェースの接続もケーブルレスにした構造は高い堅牢性を実現します。大規模なHPCやビッグデータを扱う機械学習に最適な高集積大容量ストレージです。
Skylake-SP Xeon® Scalable Family 搭載
Skylake-SP Xeon® Scalable Family を2基搭載可能なハイエンドワークステーション。最大で56コア/112スレッドのメニーコア環境を実現します。L2キャッシュを大幅に増量し、さらにCPUコア間やキャッシュメモリのインターコネクトを従来のリングバスによる接続から、メッシュアーキテクチャに変更してあります。これによりBroadwell世代のマイクロアーキテクチャの同じ周波数と比較した場合、コア当たり10%の性能向上が期待できます。
高信頼性エンタープライズストレージを搭載
本製品に搭載のハードディスクは高品質で信頼性が高いエンタープライズレベル製品のみを採用。 複数台のストレージにより周囲温度が高くなるような厳しい環境下でも、低温・低振動で動作するよう設計されています。ミッションクリティカルな24時間365日常時稼働環境でも優れた適合性を発揮します。
多様で高速なインターコネクトでスケールアウトも可能
標準で10GbpsのEtherコネクタを2ポート装備し外部ストレージとの高速な接続を可能にしています。またオプションでInfiniBand(EDR)も増設可能です。ご使用用途とご予算に応じてフレキシブルにストレージ増築が可能でより一層の高速化・大容量化に貢献します。
安心のオンサイトサポート
オンサイト保守サービスを標準としています。障害発生時に故障切り分け完了後に作業員をお客様先に派遣、復旧します。 (平日翌々営業日オンサイト9-17時半) ※注意点 弊社からご購入いただいたHDDが対象となります。他社購入のディスクが搭載された場合は保守にご加入の場合でも保証対象外となる可能性がございます
UNI-W9Xはインテル® Xeon® W-3400 および Xeon® W-2400 プロセッサーを搭載し、次世代のプロフェッショナル・ワークロードを支える究極のワークステーション・プラットフォームを提供します。インテル® W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングの信頼性と生産性、構成の柔軟性を向上することが可能です。
インテル® Xeon® Wプロセッサー・ファミリー
インテル® Xeon® Wプロセッサー・ファミリーは、さまざまなクリエイターのために設計されています。インテル® Xeon® W-3400プロセッサー搭載のプラットフォームは、VFX、3Dレンダリング、複雑な 3D CAD、およびAI開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。
ワークステーションの静音性と冷却性を保つプレミアムCPUクーラー
Noctua NH-U14S DX-4677を標準搭載。6本ヒートパイプ、140mmサイズ、プレミアムグレード140mmファンを2つ搭載することにより、静音性に優れた冷却効率を実現しており、静かな環境で使用するワークステーションに最適です。NF-A15ファンは、マザーボードによる自動速度制御のPWMをサポートします。アイドル時には静音、必要に応じてCFMパフォーマンスをフルに発揮します。
強化されたプラットフォーム
インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し、生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルは複雑なコンピューティングの需要に応えることが簡単にできます。
高品質なサーバーグレード ECCレジスタードDDR5-4800メモリを標準搭載
メモリはDDR-5規格広帯域 4800MHzモジュールをQuad-Cannelで実装、合計8つのメモリスロットを確保しております。データ破損を自動的に検出して修正し、システムクラッシュのリスクを低減させることができます。独自のメモリトレースレイアウトを採用し、最大速度でDDR5メモリのオーバークロックを可能にし、様々なワークロードに対してより良いメモリパフォーマンスを実現します。
PCI-Express 5.0 に対応
最新のPCI Express 5.0規格に対応し、前世代の2倍となる128 Gb/秒の転送速度に対応します。この驚異的な帯域幅により、将来の超高速SSDの性能を最大限に引き出すことができます。
UNI-W9Xはインテル® Xeon® W-3400 および Xeon® W-2400 プロセッサーを搭載し、次世代のプロフェッショナル・ワークロードを支える究極のワークステーション・プラットフォームを提供します。インテル® W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングの信頼性と生産性、構成の柔軟性を向上することが可能です。
インテル® Xeon® Wプロセッサー・ファミリー
インテル® Xeon® Wプロセッサー・ファミリーは、さまざまなクリエイターのために設計されています。インテル® Xeon® W-3400プロセッサー搭載のプラットフォームは、VFX、3Dレンダリング、複雑な 3D CAD、およびAI開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。
ワークステーションの静音性と冷却性を保つプレミアムCPUクーラー
Noctua NH-U14S DX-4677を標準搭載。6本ヒートパイプ、140mmサイズ、プレミアムグレード140mmファンを2つ搭載することにより、静音性に優れた冷却効率を実現しており、静かな環境で使用するワークステーションに最適です。NF-A15ファンは、マザーボードによる自動速度制御のPWMをサポートします。アイドル時には静音、必要に応じてCFMパフォーマンスをフルに発揮します。
強化されたプラットフォーム
インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し、生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルは複雑なコンピューティングの需要に応えることが簡単にできます。
高品質なサーバーグレード ECCレジスタードDDR5-4800メモリを標準搭載
メモリはDDR-5規格広帯域 4800MHzモジュールをQuad-Cannelで実装、合計8つのメモリスロットを確保しております。データ破損を自動的に検出して修正し、システムクラッシュのリスクを低減させることができます。独自のメモリトレースレイアウトを採用し、最大速度でDDR5メモリのオーバークロックを可能にし、様々なワークロードに対してより良いメモリパフォーマンスを実現します。
PCI-Express 5.0 に対応
最新のPCI Express 5.0規格に対応し、前世代の2倍となる128 Gb/秒の転送速度に対応します。この驚異的な帯域幅により、将来の超高速SSDの性能を最大限に引き出すことができます。
UNI-W9Xはインテル® Xeon® W-3400 および Xeon® W-2400 プロセッサーを搭載し、次世代のプロフェッショナル・ワークロードを支える究極のワークステーション・プラットフォームを提供します。インテル® W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングの信頼性と生産性、構成の柔軟性を向上することが可能です。
インテル® Xeon® Wプロセッサー・ファミリー
インテル® Xeon® Wプロセッサー・ファミリーは、さまざまなクリエイターのために設計されています。インテル® Xeon® W-3400プロセッサー搭載のプラットフォームは、VFX、3Dレンダリング、複雑な 3D CAD、およびAI開発とエッジ導入向けの拡張されたプラットフォーム機能とともに、卓越したパフォーマンス、セキュリティー、信頼性を提供し、プロフェッショナルなクリエイター向けに究極のワークステーション・ソリューションを実現します。
ワークステーションの静音性と冷却性を保つプレミアムCPUクーラー
Noctua NH-U14S DX-4677を標準搭載。6本ヒートパイプ、140mmサイズ、プレミアムグレード140mmファンを2つ搭載することにより、静音性に優れた冷却効率を実現しており、静かな環境で使用するワークステーションに最適です。NF-A15ファンは、マザーボードによる自動速度制御のPWMをサポートします。アイドル時には静音、必要に応じてCFMパフォーマンスをフルに発揮します。
強化されたプラットフォーム
インテル W790 チップセットと組み合わせることで、プロフェッショナルな高速ネットワークカード、グラフィックス・アクセラレーター、大容量ストレージアレイといった拡張された周辺機器に加えて、ハイパフォーマンス・コンピューティングと信頼性を経験し、生産性と構成の柔軟性を向上することが可能です。最大 112 レーン (W2400 は64レーン)の PCIe Gen 5.0 接続、最大 4TB の DDR5 RDIMM メモリーサポート、最大 5x USB 3.2 Gen 2x2 ポートなど、革新的なプラットフォーム機能により構成に柔軟性を持たせており、プロフェッショナルは複雑なコンピューティングの需要に応えることが簡単にできます。
高品質なサーバーグレード ECCレジスタードDDR5-4800メモリを標準搭載
メモリはDDR-5規格広帯域 4800MHzモジュールをQuad-Cannelで実装、合計8つのメモリスロットを確保しております。データ破損を自動的に検出して修正し、システムクラッシュのリスクを低減させることができます。独自のメモリトレースレイアウトを採用し、最大速度でDDR5メモリのオーバークロックを可能にし、様々なワークロードに対してより良いメモリパフォーマンスを実現します。
PCI-Express 5.0 に対応
最新のPCI Express 5.0規格に対応し、前世代の2倍となる128 Gb/秒の転送速度に対応します。この驚異的な帯域幅により、将来の超高速SSDの性能を最大限に引き出すことができます。
GSV-IGRAS-4U8Gは、エンタープライズ向けPCIe構成のx86アーキテクチャサーバーです。AI技術を活用した工場(AIファクトリー)や研究開発領域に合わせて、最適なインフラを柔軟に構築・配置できるのが大きな特長です。第6世代インテル® Xeon® 6 プロセッサー・ファミリーを搭載可能で、最大96コアまでサポート。さらに、高速なDDR5メモリやPCIe 5.0 I/Oに対応することで、システム全体の処理能力と拡張性を飛躍的に向上しております。
インテル® Xeon® 6プロセッサー(1ソケットあたり最大86コア)搭載
GSV-IGRAS-4U8Gは、最新のIntel® Xeon® 6プロセッサーをデュアルソケットで搭載可能なハイエンドGPUサーバーです。1CPUあたり最大86コア、350W TDPまで対応し、AI推論、科学技術計算、データ分析などの高負荷な計算処理を強力に支援します。新アーキテクチャーとなるXeon 6は、PCIe 5.0およびDDR5メモリと組み合わせることで、より高速かつ効率的なデータ処理を実現。スケーラブルな設計により、将来の拡張性にも優れており、大規模なAI・HPC環境においてそのパフォーマンスを発揮します。
デュアルスロットのハイエンドGPUを最大8基搭載可能。各GPUは最大600wまでサポート
GSV-IGRAS-4U8Gは、最大8基のデュアルスロットGPUを搭載可能な高密度設計の4Uラックマウント型GPUサーバーです。NVIDIA RTX™PROシリーズやデータセンター向けハイエンドGPUなど、アクティブ/パッシブ双方のGPUに対応し、用途に応じた最適な構成が可能です。さらに、各GPUに最大600Wまでの電力供給をサポートし、NVIDIA NVLinkによる高速GPU間通信にも対応。AI推論、ディープラーニング、大規模HPC、レンダリングなど多様なワークロードにおいて、優れたスケーラビリティと柔軟性を提供します。
マルチGPUを最大限に活用するための電源・冷却設計も充実しており、研究機関や企業の次世代計算環境に理想的なプラットフォームです。
最新GPU・Blackwell世代の RTX6000 PPRO Server Ediiton に対応
GSV-IGRAS-4U8Gは、最新のNVIDIA Blackwellアーキテクチャに基づくRTX 6000 Pro シリーズに対応した、次世代GPUサーバーです。高密度な4Uフォームファクターに最大8基のデュアルスロットGPUを搭載可能で、各GPUに最大600Wの電力供給を実現。最新のPCIe 5.0と高速DDR5メモリを活用し、生成AI、LLM推論、科学技術計算、レンダリングなど、最先端のワークロードにおいて圧倒的なパフォーマンスを発揮します。RTX 6000 Pro Serverとの組み合わせにより、データセンター環境においてもエンタープライズグレードの信頼性と処理能力を提供。将来の拡張性と冷却性にも優れ、高度なAIインフラ構築に最適なソリューションです。
ASUS Control CenterとハードウェアRoot-of-Trustにより、セキュリティと管理性を強化
GSV-IGRAS-4U8Gは、エンタープライズ環境に求められるセキュリティと管理性を両立する先進的な設計です。ASUS独自の「ASUS Control Center」IT管理ソフトウェアにより、リモートからのハードウェア監視・制御・ファームウェア更新が可能で、システム管理の効率を大幅に向上させます。さらに、ハードウェアレベルでのRoot-of-Trustセキュリティ機能を備えており、起動時の信頼性検証や改ざん検知を通じて、不正なアクセスやマルウェアからシステムを保護。ファームウェアやBIOSの整合性を保証し、企業のITインフラ全体におけるセキュリティリスクを大幅に低減します。信頼性・管理性・セキュリティを兼ね備えたGSV-IGRAS-4U8Gは、安全なAI・HPC環境の基盤として最適なシステムです。
ツールレス設計を採用し、メンテナンスの簡素化と最大効率を実現
GSV-IGRAS-4U8Gは、ツールレス設計を採用することで、システムの保守性と運用効率を大幅に向上させたGPUサーバーです。ストレージベイ、拡張カード、冷却ファン、PCIeリザーバーボードなどの主要コンポーネントは工具なしで取り外し・交換が可能で、迅速なメンテナンスやアップグレードを実現します。これにより、ダウンタイムの最小化と作業効率の最大化を両立し、データセンターや研究機関での高可用性運用をサポート。高密度・高性能な構成でありながら、整備性に優れた設計は、AIやHPCなど常時高負荷がかかる環境において大きな利点となります。
GSV-IGRAS-4U8Gは、エンタープライズ向けPCIe構成のx86アーキテクチャサーバーです。AI技術を活用した工場(AIファクトリー)や研究開発領域に合わせて、最適なインフラを柔軟に構築・配置できるのが大きな特長です。第6世代インテル® Xeon® 6 プロセッサー・ファミリーを搭載可能で、最大96コアまでサポート。さらに、高速なDDR5メモリやPCIe 5.0 I/Oに対応することで、システム全体の処理能力と拡張性を飛躍的に向上しております。
インテル® Xeon® 6プロセッサー(1ソケットあたり最大86コア)搭載
GSV-IGRAS-4U8Gは、最新のIntel® Xeon® 6プロセッサーをデュアルソケットで搭載可能なハイエンドGPUサーバーです。1CPUあたり最大86コア、350W TDPまで対応し、AI推論、科学技術計算、データ分析などの高負荷な計算処理を強力に支援します。新アーキテクチャーとなるXeon 6は、PCIe 5.0およびDDR5メモリと組み合わせることで、より高速かつ効率的なデータ処理を実現。スケーラブルな設計により、将来の拡張性にも優れており、大規模なAI・HPC環境においてそのパフォーマンスを発揮します。
デュアルスロットのハイエンドGPUを最大8基搭載可能。各GPUは最大600wまでサポート
GSV-IGRAS-4U8Gは、最大8基のデュアルスロットGPUを搭載可能な高密度設計の4Uラックマウント型GPUサーバーです。NVIDIA RTX™PROシリーズやデータセンター向けハイエンドGPUなど、アクティブ/パッシブ双方のGPUに対応し、用途に応じた最適な構成が可能です。さらに、各GPUに最大600Wまでの電力供給をサポートし、NVIDIA NVLinkによる高速GPU間通信にも対応。AI推論、ディープラーニング、大規模HPC、レンダリングなど多様なワークロードにおいて、優れたスケーラビリティと柔軟性を提供します。
マルチGPUを最大限に活用するための電源・冷却設計も充実しており、研究機関や企業の次世代計算環境に理想的なプラットフォームです。
最新GPU・Blackwell世代の RTX6000 PPRO Server Ediiton に対応
GSV-IGRAS-4U8Gは、最新のNVIDIA Blackwellアーキテクチャに基づくRTX 6000 Pro シリーズに対応した、次世代GPUサーバーです。高密度な4Uフォームファクターに最大8基のデュアルスロットGPUを搭載可能で、各GPUに最大600Wの電力供給を実現。最新のPCIe 5.0と高速DDR5メモリを活用し、生成AI、LLM推論、科学技術計算、レンダリングなど、最先端のワークロードにおいて圧倒的なパフォーマンスを発揮します。RTX 6000 Pro Serverとの組み合わせにより、データセンター環境においてもエンタープライズグレードの信頼性と処理能力を提供。将来の拡張性と冷却性にも優れ、高度なAIインフラ構築に最適なソリューションです。
ASUS Control Center IT管理ソフトウェアとハードウェアレベルのRoot-of-Trustソリューションを搭載し、セキュリティと制御を強化
GSV-IGRAS-4U8Gは、エンタープライズ環境に求められるセキュリティと管理性を両立する先進的な設計です。ASUS独自の「ASUS Control Center」IT管理ソフトウェアにより、リモートからのハードウェア監視・制御・ファームウェア更新が可能で、システム管理の効率を大幅に向上させます。さらに、ハードウェアレベルでのRoot-of-Trustセキュリティ機能を備えており、起動時の信頼性検証や改ざん検知を通じて、不正なアクセスやマルウェアからシステムを保護。ファームウェアやBIOSの整合性を保証し、企業のITインフラ全体におけるセキュリティリスクを大幅に低減します。信頼性・管理性・セキュリティを兼ね備えたGSV-IGRAS-4U8Gは、安全なAI・HPC環境の基盤として最適なシステムです。
ツールレス設計を採用し、メンテナンスの簡素化と最大効率を実現
GSV-IGRAS-4U8Gは、ツールレス設計を採用することで、システムの保守性と運用効率を大幅に向上させたGPUサーバーです。ストレージベイ、拡張カード、冷却ファン、PCIeリザーバーボードなどの主要コンポーネントは工具なしで取り外し・交換が可能で、迅速なメンテナンスやアップグレードを実現します。これにより、ダウンタイムの最小化と作業効率の最大化を両立し、データセンターや研究機関での高可用性運用をサポート。高密度・高性能な構成でありながら、整備性に優れた設計は、AIやHPCなど常時高負荷がかかる環境において大きな利点となります。
GSV-IGRAS-4U8Gは、エンタープライズ向けPCIe構成のx86アーキテクチャサーバーです。AI技術を活用した工場(AIファクトリー)や研究開発領域に合わせて、最適なインフラを柔軟に構築・配置できるのが大きな特長です。第6世代インテル® Xeon® 6 プロセッサー・ファミリーを搭載可能で、最大96コアまでサポート。さらに、高速なDDR5メモリやPCIe 5.0 I/Oに対応することで、システム全体の処理能力と拡張性を飛躍的に向上しております。
インテル® Xeon® 6プロセッサー(1ソケットあたり最大86コア)搭載
GSV-IGRAS-4U8Gは、最新のIntel® Xeon® 6プロセッサーをデュアルソケットで搭載可能なハイエンドGPUサーバーです。1CPUあたり最大86コア、350W TDPまで対応し、AI推論、科学技術計算、データ分析などの高負荷な計算処理を強力に支援します。新アーキテクチャーとなるXeon 6は、PCIe 5.0およびDDR5メモリと組み合わせることで、より高速かつ効率的なデータ処理を実現。スケーラブルな設計により、将来の拡張性にも優れており、大規模なAI・HPC環境においてそのパフォーマンスを発揮します。
デュアルスロットのハイエンドGPUを最大8基搭載可能。各GPUは最大600wまでサポート
GSV-IGRAS-4U8Gは、最大8基のデュアルスロットGPUを搭載可能な高密度設計の4Uラックマウント型GPUサーバーです。NVIDIA RTX™PROシリーズやデータセンター向けハイエンドGPUなど、アクティブ/パッシブ双方のGPUに対応し、用途に応じた最適な構成が可能です。さらに、各GPUに最大600Wまでの電力供給をサポートし、NVIDIA NVLinkによる高速GPU間通信にも対応。AI推論、ディープラーニング、大規模HPC、レンダリングなど多様なワークロードにおいて、優れたスケーラビリティと柔軟性を提供します。
マルチGPUを最大限に活用するための電源・冷却設計も充実しており、研究機関や企業の次世代計算環境に理想的なプラットフォームです。
最新GPU・Blackwell世代の RTX6000 PPRO Server Ediiton に対応
GSV-IGRAS-4U8Gは、最新のNVIDIA Blackwellアーキテクチャに基づくRTX 6000 Pro シリーズに対応した、次世代GPUサーバーです。高密度な4Uフォームファクターに最大8基のデュアルスロットGPUを搭載可能で、各GPUに最大600Wの電力供給を実現。最新のPCIe 5.0と高速DDR5メモリを活用し、生成AI、LLM推論、科学技術計算、レンダリングなど、最先端のワークロードにおいて圧倒的なパフォーマンスを発揮します。RTX 6000 Pro Serverとの組み合わせにより、データセンター環境においてもエンタープライズグレードの信頼性と処理能力を提供。将来の拡張性と冷却性にも優れ、高度なAIインフラ構築に最適なソリューションです。
ASUS Control Center IT管理ソフトウェアとハードウェアレベルのRoot-of-Trustソリューションを搭載し、セキュリティと制御を強化
GSV-IGRAS-4U8Gは、エンタープライズ環境に求められるセキュリティと管理性を両立する先進的な設計です。ASUS独自の「ASUS Control Center」IT管理ソフトウェアにより、リモートからのハードウェア監視・制御・ファームウェア更新が可能で、システム管理の効率を大幅に向上させます。さらに、ハードウェアレベルでのRoot-of-Trustセキュリティ機能を備えており、起動時の信頼性検証や改ざん検知を通じて、不正なアクセスやマルウェアからシステムを保護。ファームウェアやBIOSの整合性を保証し、企業のITインフラ全体におけるセキュリティリスクを大幅に低減します。信頼性・管理性・セキュリティを兼ね備えたGSV-IGRAS-4U8Gは、安全なAI・HPC環境の基盤として最適なシステムです。
ツールレス設計を採用し、メンテナンスの簡素化と最大効率を実現
GSV-IGRAS-4U8Gは、ツールレス設計を採用することで、システムの保守性と運用効率を大幅に向上させたGPUサーバーです。ストレージベイ、拡張カード、冷却ファン、PCIeリザーバーボードなどの主要コンポーネントは工具なしで取り外し・交換が可能で、迅速なメンテナンスやアップグレードを実現します。これにより、ダウンタイムの最小化と作業効率の最大化を両立し、データセンターや研究機関での高可用性運用をサポート。高密度・高性能な構成でありながら、整備性に優れた設計は、AIやHPCなど常時高負荷がかかる環境において大きな利点となります。
GSV-IEMSM-4U4Gは、NVIDIA L40S、NVIDIA A800、NVIDIA RTX PRO™ 6000 Max-QをはじめとしたNVIDIA Ada Lovelace / BlackwellアーキテクチャGPUを最大4基搭載可能な4UラックマウントGPUサーバーです。CPUにはAIアクセラレーションを搭載した第5世代Xeon® Scalableプロセッサーを採用し、負荷の高いAIワークロードにも対応。GPU処理に加え、プリポスト処理の高速化にも優れた性能を発揮します。また、I/OインターフェースはPCI Express 5.0に対応し、32GT/sの広帯域を実現。システム全体のボトルネックを解消するとともに、完全な後方互換性を提供します。ストレージにはフロントアクセスが可能な2基の3.5インチHDDホットスワップベイと、2.5インチSSDを最大4基内蔵でき、高い拡張性を備えています。GPUカードはNVIDIA L40S、NVIDIA A800、RTX 6000 Ada、NVIDIA RTX PRO™ 6000 Max-QをはじめとしたNVIDIA Ada Lovelace / BlackwellアーキテクチャGPUに対応しており、大規模AIの学習・推論のいずれにも対応可能な高性能AIサーバーです。さらに、AI開発・運用を効率化するG-Suiteに対応しており、環境構築や運用負荷を軽減しながら、導入後すぐにAI開発・解析環境を立ち上げることが可能です。ハードウェア性能を最大限に引き出し、研究開発やデータ処理の生産性向上に貢献します。また、NVIDIAエリートパートナーであるジーデップ・アドバンスでは、NVIDIA Docker上にNGC(NVIDIA GPU CLOUD)開発環境を標準インストール。さらに、お客様の利用環境に応じてコンパイラやライブラリ、ジョブスケジューラなどを最適化することも可能です。生成AIによる大規模言語モデル、画像生成、医療分野の生成系AIなど、AI開発およびHPC研究に最適なモデルです。
カスタマイズメニューにない構成についても、お気軽にお問い合わせください。お客様のご要望に応じて、優れたコストパフォーマンスと安定した運用環境をご提供いたします。
NVIDIA RTX PRO 6000 Blackwell シリーズ製品比較レポート G-Suiteとは?できることをわかりやすく解説
第4世代インテルXeonスケーラブル プロセッサー(Sapphire Rapids)搭載
第4世代インテルXeonスケーラブル プロセッサー(Sapphire Rapids)を採用、Intel 7ノード(旧10nm)で製造され、プロセッサあたり最大60個のGolden Coveコアと新しい専用アクセラレータコアを搭載、新しいアクセラレータを使用したターゲットワークロードにおいて、前世代に比べて平均1.53倍の性能向上と、ワットあたりの平均性能2.9倍の効率改善を実現します。
最も多機能かつセキュアなインテル® Xeon® プラットフォーム
インテル® Xeon® プラットフォームの新機能により、PCIe 5.0、DDR5メモリ、CXL 1.1をサポート、またメインメモリはDDR5-4800規格で8チャネル構成、最大メインメモリ容量4TBなど、大幅な機能の向上に加えて、ネットワークは高速な10Gbpsイーサーネットを標準搭載と管理用IPMIも装備し、リモートメンテナンスにも対応しています。また、 最大8ベイのエンクロージャーはNVMe U.2に対応しており、大容量で高速なストレージ環境も柔軟に構築可能で、これまでにな多機能でセキュアなプラットフォームです。
NVIDIA Hopper アーキテクチャ搭載 H100搭載
GPUは、NVIDIA® Hopperアーキテクチャベースで80GB HBM2eの大容量メモリを搭載が可能、NVIDIA H100 Tensor Core GPU は、TMSCの4nm プロセスルールを採用し814平方mmのダイサイズに、従来のA100の約1.5倍にあたる800億個のトランジスタを搭載したまさに史上最大にして最速のGPUであり、倍精度・単精度をはじめ多様な精度を兼ね備え、マルチインスタンスGPU(MIG)機能により1つのGPUで最大7つのジョブを同時に実行可能。世界で最も困難な計算に AI、データ分析、 HPC分野で驚異的な性能を発揮します。また、第 4 世代の Tensor コアと、FP8 精度で混合エキスパート (MoE) モデルのトレーニングを前世代比最大 9 倍高速化するTransformer Engine を備えております。また、NVIDIA RTX シリーズ(RTX A6000/RTX A5000) を搭載したモデルも用意しておりジェネレーティブAI による大規模言語モデル、画像生成、医療分野の生成系AIなどAI開発、HPC研究に最適なモデルです。
AI開発環境 G-Works 標準搭載
本システムには Linux(Ubuntu)オペレーティングシステムと、当社独自のAI開発 ライブラリー群 「G-Works」、そしてOpenAI社も利用しているMLopsプラットフォームである「WandB」がプレインストールされており、AI開発ユーザーが届いたその日からすぐに利用できるターンキーでの提供となります。まさに大学、研究機関、企業のR&D部門などのAI開発者に最適なAI開発システムとなります。
GSV-IEMSM-4U4G は、ジーデップ・アドバンスが国内代理店の Super Micro Compute社製べアシステムをベースに構成されたGPUサーバーです。本システムは、第4世代インテルXeonスケーラブル プロセッサー(Sapphire Rapids)を採用、Intel 7ノード(旧10nm)で製造され、プロセッサあたり最大60個のGolden Coveコアと新しい専用アクセラレータコアを搭載、新しいアクセラレータを使用したターゲットワークロードにおいて、前世代に比べて平均1.53倍の性能向上と、ワットあたりの平均性能2.9倍の効率改善を実現とプロセッサの新機能により、PCIe 5.0、DDR5メモリ、CXL 1.1をサポート、またメインメモリはDDR5-4800規格で8チャネル構成、最大メインメモリ容量4TBなど、大幅な機能の向上に加えて、ネットワークは高速な10Gbpsイーサーネットを標準搭載と管理用IPMIも装備し、リモートメンテナンスにも対応しています。また、 最大8ベイのエンクロージャーはNVMe U.2に対応しており、大容量で高速なストレージ環境も柔軟に構築可能です。
第4世代インテルXeonスケーラブル プロセッサー(Sapphire Rapids)搭載
第4世代インテルXeonスケーラブル プロセッサー(Sapphire Rapids)を採用、Intel 7ノード(旧10nm)で製造され、プロセッサあたり最大60個のGolden Coveコアと新しい専用アクセラレータコアを搭載、新しいアクセラレータを使用したターゲットワークロードにおいて、前世代に比べて平均1.53倍の性能向上と、ワットあたりの平均性能2.9倍の効率改善を実現します。
最も多機能かつセキュアなインテル® Xeon® プラットフォーム
インテル® Xeon® プラットフォームの新機能により、PCIe 5.0、DDR5メモリ、CXL 1.1をサポート、またメインメモリはDDR5-4800規格で8チャネル構成、最大メインメモリ容量4TBなど、大幅な機能の向上に加えて、ネットワークは高速な10Gbpsイーサーネットを標準搭載と管理用IPMIも装備し、リモートメンテナンスにも対応しています。また、 最大8ベイのエンクロージャーはNVMe U.2に対応しており、大容量で高速なストレージ環境も柔軟に構築可能で、これまでにな多機能でセキュアなプラットフォームです。
NVIDIA Hopper アーキテクチャ搭載 H100搭載
GPUは、NVIDIA® Hopperアーキテクチャベースで80GB HBM2eの大容量メモリを搭載が可能、NVIDIA H100 Tensor Core GPU は、TMSCの4nm プロセスルールを採用し814平方mmのダイサイズに、従来のA100の約1.5倍にあたる800億個のトランジスタを搭載したまさに史上最大にして最速のGPUであり、倍精度・単精度をはじめ多様な精度を兼ね備え、マルチインスタンスGPU(MIG)機能により1つのGPUで最大7つのジョブを同時に実行可能。世界で最も困難な計算に AI、データ分析、 HPC分野で驚異的な性能を発揮します。また、第 4 世代の Tensor コアと、FP8 精度で混合エキスパート (MoE) モデルのトレーニングを前世代比最大 9 倍高速化するTransformer Engine を備えております。また、NVIDIA RTX シリーズ(RTX A6000/RTX A5000) を搭載したモデルも用意しておりジェネレーティブAI による大規模言語モデル、画像生成、医療分野の生成系AIなどAI開発、HPC研究に最適なモデルです。
AI開発環境 G-Works 標準搭載
本システムには Linux(Ubuntu)オペレーティングシステムと、当社独自のAI開発 ライブラリー群 「G-Works」、そしてOpenAI社も利用しているMLopsプラットフォームである「WandB」がプレインストールされており、AI開発ユーザーが届いたその日からすぐに利用できるターンキーでの提供となります。まさに大学、研究機関、企業のR&D部門などのAI開発者に最適なAI開発システムとなります。
GSV-IEMSM-4U4Gは、ジーデップ・アドバンスが国内代理店の Super Micro Compute社製べアシステムをベースに構成されたGPUサーバーです。本システムは、第4世代インテルXeonスケーラブル プロセッサー(Sapphire Rapids)を採用、Intel 7ノード(旧10nm)で製造され、プロセッサあたり最大60個のGolden Coveコアと新しい専用アクセラレータコアを搭載、新しいアクセラレータを使用したターゲットワークロードにおいて、前世代に比べて平均1.53倍の性能向上と、ワットあたりの平均性能2.9倍の効率改善を実現とプロセッサの新機能により、PCIe 5.0、DDR5メモリ、CXL 1.1をサポート、またメインメモリはDDR5-4800規格で8チャネル構成、最大メインメモリ容量4TBなど、大幅な機能の向上に加えて、ネットワークは高速な10Gbpsイーサーネットを標準搭載と管理用IPMIも装備し、リモートメンテナンスにも対応しています。また、 最大8ベイのエンクロージャーはNVMe U.2に対応しており、大容量で高速なストレージ環境も柔軟に構築可能です。
第4世代インテルXeonスケーラブル プロセッサー(Sapphire Rapids)搭載
第4世代インテルXeonスケーラブル プロセッサー(Sapphire Rapids)を採用、Intel 7ノード(旧10nm)で製造され、プロセッサあたり最大60個のGolden Coveコアと新しい専用アクセラレータコアを搭載、新しいアクセラレータを使用したターゲットワークロードにおいて、前世代に比べて平均1.53倍の性能向上と、ワットあたりの平均性能2.9倍の効率改善を実現します。
最も多機能かつセキュアなインテル® Xeon® プラットフォーム
インテル® Xeon® プラットフォームの新機能により、PCIe 5.0、DDR5メモリ、CXL 1.1をサポート、またメインメモリはDDR5-4800規格で8チャネル構成、最大メインメモリ容量4TBなど、大幅な機能の向上に加えて、ネットワークは高速な10Gbpsイーサーネットを標準搭載と管理用IPMIも装備し、リモートメンテナンスにも対応しています。また、 最大8ベイのエンクロージャーはNVMe U.2に対応しており、大容量で高速なストレージ環境も柔軟に構築可能で、これまでにな多機能でセキュアなプラットフォームです。
NVIDIA Hopper アーキテクチャ搭載 H100搭載
GPUは、NVIDIA® Hopperアーキテクチャベースで80GB HBM2eの大容量メモリを搭載が可能、NVIDIA H100 Tensor Core GPU は、TMSCの4nm プロセスルールを採用し814平方mmのダイサイズに、従来のA100の約1.5倍にあたる800億個のトランジスタを搭載したまさに史上最大にして最速のGPUであり、倍精度・単精度をはじめ多様な精度を兼ね備え、マルチインスタンスGPU(MIG)機能により1つのGPUで最大7つのジョブを同時に実行可能。世界で最も困難な計算に AI、データ分析、 HPC分野で驚異的な性能を発揮します。また、第 4 世代の Tensor コアと、FP8 精度で混合エキスパート (MoE) モデルのトレーニングを前世代比最大 9 倍高速化するTransformer Engine を備えております。また、NVIDIA RTX シリーズ(RTX A6000/RTX A5000) を搭載したモデルも用意しておりジェネレーティブAI による大規模言語モデル、画像生成、医療分野の生成系AIなどAI開発、HPC研究に最適なモデルです。
AI開発環境 G-Works 標準搭載
本システムには Linux(Ubuntu)オペレーティングシステムと、当社独自のAI開発 ライブラリー群 「G-Works」、そしてOpenAI社も利用しているMLopsプラットフォームである「WandB」がプレインストールされており、AI開発ユーザーが届いたその日からすぐに利用できるターンキーでの提供となります。まさに大学、研究機関、企業のR&D部門などのAI開発者に最適なAI開発システムとなります。
民間企業、政府機関、学術などの研究者がAIへの取り組みを強化するにつれ、AIの計算リソースに対するニーズが高まっている背景から、生成AIモデルのサイズや複雑さが増し、ローカルシステムでの開発が困難になっています。
AIの時代のためにゼロから設計された新しいクラスのコンピューター
NVIDIA DGX Sparkは従来クラウドやデータセンターのリソースが必要だった大規模な AI ワークロードに取り組んでいる AI 開発者、研究者、データ サイエンティスト、学生向けに設計されています。デスクトップシステムでありながら、1,000 TOPSのAIパフォーマンス(FP4精度)と128GBのコヒーレント統合システムメモリを提供し、開発者がデスクで最大2,000億のパラメータ、128GBのunifiedシステムメモリによりAIモデルの開発、推論を可能にします。
さらに、NVIDIA ConnectX™ ネットワーキングにより、2台のNVIDIA DGX Sparkスーパーコンピュータを接続し、最大405Bパラメータのモデルの推論を可能にします。非常に小さなフォーム ファクター(重量わずか1.2キロ、 L150mm x W150 mm x H50.5 mm )で既存のラップトップやデスクトップシステムでは実行できないAIモデルやワークロードに対応します。
DGX Spark – System Connections
DGX SparkのリアパネルはすべてのI/Oポートが配置されており左側には電源ボタンがあります。
電源ボタンの隣には4つのUSB-Cポートがあります。1つのポートはDGX Sparkに電力を供給するために使用され、残りの3つはユーザーのために空いています。
パネルの中央近くにはHDMI 2.1aポートがあり、ディスプレイをDGX Sparkに直接接続できます。HDMI 2.1aは、最大8Kディスプレイを120Hz HDRまでサポートし、ネットワーク接続はパネルの右側にあります。中央近くにはRJ-45イーサネット接続があり、最大10Gbps(ギガビット毎秒)の速度で通信できるイーサネット(LAN)規格です。
左側にはConnectX-7 200Gbps QSFP接続があります。Quad Small Form-factor Pluggable(QSFP)接続は、高速データレートをサポートします。
ユーザーは、2つのDGX Sparkを接続して、最大405BパラメータのAIモデルに対応できる個人クラスターを作成するためにQSFPケーブルが必要です。また、2つのDGX Sparkシステムを接続するには1つのポートのみが必要となります。
スケーラブルソリューション
DGX Sparkは、産業用向けにAI製品やサービスを生産するためのシステムやプロセスを稼働する際、システムの設計と開発における基盤となるソフトウェアアーキテクチャを搭載しています。Ubuntu Linuxを搭載したNVIDIA DGX OSを使用し、最新のNVIDIA AIソフトウェアスタックで事前構成され、NVIDIA NIM™ とNVIDIAブループリントへの開発者プログラムアクセスとともに、開発者はPytorch、Jupyter、Ollamaなどの一般的なツールを使用して、DGX Spark上でプロトタイプ作成、微調整、推論を行い、データセンターやクラウドにシームレスに展開することができます。
DGX Sparkは、開発者、研究者、データサイエンティスト、および学生が、コンパクトなパッケージで大規模な生成AIパフォーマンスを発揮することを可能にします。
DGX Sparkとその他のAIシステム環境の比較
AI開発のためのシステム環境を検討する際、ハイエンドのワークステーションGPUのうちの2つがメモリとして稼働しますが、開発者がラップトップやデスクトップシステムを追加しようとする場合、コストが高くなります。
データセンターやクラウドは、膨大なコンピューティング容量とメモリ容量を必要とするため、AI開発者はデータセンターのリソースや、クラウドインスタンスの予算を確保したりする必要があります。
その点、DGX Spark は、デスクトップ デバイス上でより大きな AI モデルやワークロードで作業する必要がある AI 開発者に最適です。
DGX Sparkの利点
DGX Spark は、大規模なモデルで最大 200B のパラメーターの AI ワークロードをローカルで実行できます。
また、NVIDIA AI ソフトウェア スタックは、AI を構築および実行でき、データはローカルに保持されるため、外部の場所にデータを転送する必要がありません。AIクラウド - データセンターのコンピューティングやクラウドインスタンスの費用は必要なく、大規模AIモデルの構築の際は2つのDGX Sparkを接続して作業ができます。
NVIDIA AIソフトウェアスタックにより開発者がAIを構築・実行するために必要なすべてのツールを提供され、追加のコンピューティングやデプロイのために、作業をクラウドやデータセンターに簡単に移行することもできます。
民間企業、政府機関、学術などの研究者がAIへの取り組みを強化するにつれ、AIの計算リソースに対するニーズが高まっている背景から、生成AIモデルのサイズや複雑さが増し、ローカルシステムでの開発が困難になっています。
AIの時代のためにゼロから設計された新しいクラスのコンピューター
NVIDIA DGX Sparkは従来クラウドやデータセンターのリソースが必要だった大規模な AI ワークロードに取り組んでいる AI 開発者、研究者、データ サイエンティスト、学生向けに設計されています。デスクトップシステムでありながら、1,000 TOPSのAIパフォーマンス(FP4精度)と128GBのコヒーレント統合システムメモリを提供し、開発者がデスクで最大2,000億のパラメータ、128GBのunifiedシステムメモリによりAIモデルの開発、推論を可能にします。
さらに、NVIDIA ConnectX™ ネットワーキングにより、2台のNVIDIA DGX Sparkスーパーコンピュータを接続し、最大405Bパラメータのモデルの推論を可能にします。非常に小さなフォーム ファクター(重量わずか1.2キロ、 L150mm x W150 mm x H50.5 mm )で既存のラップトップやデスクトップシステムでは実行できないAIモデルやワークロードに対応します。
DGX Spark – System Connections
DGX SparkのリアパネルはすべてのI/Oポートが配置されており左側には電源ボタンがあります。
電源ボタンの隣には4つのUSB-Cポートがあります。1つのポートはDGX Sparkに電力を供給するために使用され、残りの3つはユーザーのために空いています。
パネルの中央近くにはHDMI 2.1aポートがあり、ディスプレイをDGX Sparkに直接接続できます。HDMI 2.1aは、最大8Kディスプレイを120Hz HDRまでサポートし、ネットワーク接続はパネルの右側にあります。中央近くにはRJ-45イーサネット接続があり、最大10Gbps(ギガビット毎秒)の速度で通信できるイーサネット(LAN)規格です。
左側にはConnectX-7 200Gbps QSFP接続があります。Quad Small Form-factor Pluggable(QSFP)接続は、高速データレートをサポートします。
ユーザーは、2つのDGX Sparkを接続して、最大405BパラメータのAIモデルに対応できる個人クラスターを作成するためにQSFPケーブルが必要です。また、2つのDGX Sparkシステムを接続するには1つのポートのみが必要となります。
スケーラブルソリューション
DGX Sparkは、産業用向けにAI製品やサービスを生産するためのシステムやプロセスを稼働する際、システムの設計と開発における基盤となるソフトウェアアーキテクチャを搭載しています。Ubuntu Linuxを搭載したNVIDIA DGX OSを使用し、最新のNVIDIA AIソフトウェアスタックで事前構成され、NVIDIA NIM™ とNVIDIAブループリントへの開発者プログラムアクセスとともに、開発者はPytorch、Jupyter、Ollamaなどの一般的なツールを使用して、DGX Spark上でプロトタイプ作成、微調整、推論を行い、データセンターやクラウドにシームレスに展開することができます。
DGX Sparkは、開発者、研究者、データサイエンティスト、および学生が、コンパクトなパッケージで大規模な生成AIパフォーマンスを発揮することを可能にします。
DGX Sparkとその他のAIシステム環境の比較
AI開発のためのシステム環境を検討する際、ハイエンドのワークステーションGPUのうちの2つがメモリとして稼働しますが、開発者がラップトップやデスクトップシステムを追加しようとする場合、コストが高くなります。
データセンターやクラウドは、膨大なコンピューティング容量とメモリ容量を必要とするため、AI開発者はデータセンターのリソースや、クラウドインスタンスの予算を確保したりする必要があります。
その点、DGX Spark は、デスクトップ デバイス上でより大きな AI モデルやワークロードで作業する必要がある AI 開発者に最適です。
DGX Sparkの利点
DGX Spark は、大規模なモデルで最大 200B のパラメーターの AI ワークロードをローカルで実行できます。
また、NVIDIA AI ソフトウェア スタックは、AI を構築および実行でき、データはローカルに保持されるため、外部の場所にデータを転送する必要がありません。AIクラウド - データセンターのコンピューティングやクラウドインスタンスの費用は必要なく、大規模AIモデルの構築の際は2つのDGX Sparkを接続して作業ができます。
NVIDIA AIソフトウェアスタックにより開発者がAIを構築・実行するために必要なすべてのツールを提供され、追加のコンピューティングやデプロイのために、作業をクラウドやデータセンターに簡単に移行することもできます。
ASUS ASCENT GX10 Powered By GDEPは、NVIDIA® GB10 Grace Blackwell Superchipを搭載し、最大1PFLOPSの高速AI演算を実現するコンパクトなデスクトップAIシステムです。そのため、生成AIや大規模言語モデル(LLM)の学習・推論、高負荷ワークロードや最大2,000億パラメータ規模のモデルの微調整も安定して実行できます。さらに、ハードウェアとソフトウェアを統合したフルスタック互換性により、導入後すぐに開発・検証作業を開始でき、環境構築の手間を大幅に削減します。加えて、NVLink™-C2CやConnectX-7による高速接続で複数ノード構成でも安定した演算性能を維持可能。高効率冷却設計により小型フォームファクターでも信頼性と静音性を確保します。さらに、ローカルでのデータ処理により低遅延応答やセキュリティ対応も実現し、GDEP Advance Standalone Backup Utilityでシステム全体のバックアップや復元も容易です。これらによってASUS ASCENT GX10 Powered By GDEPは、AI開発・研究を効率的かつ力強くサポートします。
大規模AIワークロードに対応するコンパクトAIスーパーコンピューター
ASUS ASCENT GX10 Powered By GDEPは、NVIDIA® GB10 Grace Blackwell Superchip を搭載し、最大 1 ペタフロップス(PFLOPS)の高速な AI 演算性能を発揮します。これにより、生成 AIや大規模言語モデル(LLM)の学習・推論といった高負荷なワークロードにも対応可能です。さらに、128GBの大容量メモリを備えることで、最大2,000億パラメータ規模の大規模 AI モデルに対する微調整(ファインチューニング)や検証作業も、安定かつスムーズに実行できます。研究開発から実運用を見据えたプロトタイピングまで、計算資源の制約を感じることなく、効率的なAI開発環境を提供します。
スケーラブルで安定したAIワークロード対応デスクトップソリューション
ASUS ASCENT GX10 Powered By GDEPは、AI研究者・開発者向けに設計されており、ハードウェアからソフトウェアまでを含むフルスタック互換性により、ローカル環境においても高性能かつ効率的なAI開発を実現します。最適化された構成により、環境構築の手間を最小限に抑え、導入後すぐに開発・検証作業へ着手することが可能です。加えて、NVIDIAの高速インターコネクト技術「NVLink™-C2C」によりCPUとGPU間のデータ転送は低遅延かつ高帯域で行われ、演算リソースを最大限に活用できます。これにより、データ処理から学習・推論までの一連のワークフローがスムーズに連携します。さらに、「ConnectX-7」を用いて2台のGX10システムを接続することで、システム全体の演算性能およびスケーラビリティを大幅に向上させることが可能です。複数ノード構成においても安定した高速処理を維持し、より大規模かつ高度なAIワークロードにも柔軟に対応します。
高効率冷却と安定稼働を実現するGX10デスクトップAIシステム
ASUS ASCENT GX10 Powered By GDEPは、工学的知見に基づいて設計された高効率冷却システムを採用し、超小型フォームファクターでありながら、高いパフォーマンスと信頼性を両立。発熱量の大きい高性能コンポーネントに対しても熱設計を最適化することで、サーマルスロットリングを抑制し、演算性能を安定的に維持します。また、冷却効率とエアフローの最適化により、運用時の静音性にも配慮しており、研究室やオフィス環境に加え、エンタープライズ利用を想定した業務環境においても快適に導入・運用が可能です。さらに、長時間にわたる高負荷なAIワークロードや常時稼働を前提とした設計思想に基づき、高い可用性と信頼性が求められる業務継続環境においても、安定したAI開発・研究基盤を提供します。
高性能AI処理と効率的ワークフローを両立する統合環境
ASUS ASCENT GX10 Powered By GDEPは、最小限の設置面積で最大限の運用効率を実現するラボやオフィスに加え、エッジ環境での運用を前提に設計されたコンパクトなAIシステムです。限られた設置スペースや電力条件下でも高い計算能力を発揮し、データを生成・処理する現場に近い場所で高度なAI処理を実行することで、低遅延な応答が求められるユースケースに対応。また、NVIDIA® GB10 Grace Blackwell Superchipと、NVIDIAが提供する統合AIソフトウェアを組み合わせたフルスタックAIソリューションとして提供され、エッジ環境におけるAIモデルの開発、学習、推論、展開までを一貫してサポートします。データをローカル環境内で処理・活用することで、クラウドへのデータ転送を最小限に抑え、通信コストの削減やデータローカリティの確保、セキュリティ要件への対応を可能にし、エンタープライズ用途における実用的かつ持続可能なエッジAI基盤を実現します。
大切なシステムを丸ごと守る、安心の完全バックアップ「GDEP Advance Standalone Backup Utility」搭載
GDEP Advance Standalone Backup Utility(以下 Standalone Backup)はジーデップ・アドバンスが提供するコンピュータのシステム領域を完全バックアップするためのユーティリティツールです。