













これにより、大規模言語モデルの開発や、複雑なシミュレーションなどの高度な計算処理を短時間で実行可能になりました。また、NVIDIA AI Enterpriseの5年サブスクリプションを付属することで、より円滑なAI開発環境を提供します。
※本製品は消費電力が非常に高くNVIDIAが認定したシステムにのみ搭載可能です。動作認証済のシステムや搭載方法については弊社にご相談下さい。 ※NVLinkでのGPU接続は、NVIDIA H100 NVL を2枚接続する際に有効です。異なるGPUカードとの接続は動作保障外となりますのでご注意下さい。
| NVIDIA H100 for PCIe | NVIDIA H100 NVL for PCIe | NVIDIA H200 NVL for PCIe | |
| アーキテクチャ | Hopper | Hopper | Hopper |
| FP64 | 24 TFLOPS | 30TFLOPS | 30 TFLOPS |
| FP64 Tensor コア | 30 TFLOPS | 60TFLOPS | 60 TFLOPS |
| FP32 | 30 TFLOPS | 60TFLOPS | 60 TFLOPS |
| TF32 Tensor コア* | 395 TFLOPS | 835TFLOPS | 835 TFLOPS |
| BFLOAT16 Tensor コア* | 395 TFLOPS | 1,671TFLOPS | 1,671 TFLOPS |
| FP16 Tensor コア* | 1,513 TFLOPS | 1,671TFLOPS | 1,671 TFLOPS |
| FP8 Tensor コア* | 3,026 TFLOPS | 3,341TFLOPS | 3,341 TFLOPS |
| INT8 Tensor コア* | 3,026 TOPS | 3,341 TOPS | 3,341 TFLOPS |
| GPU メモリ | 80 GB HBM2e | 94GB HBM3 | 141GB HBM3e |
| GPU メモリ帯域幅 | 2TB/秒 | 3.9TB/秒 | 4.8TB/秒 |
| デコーダー | 7 NVDEC | 7 NVDEC | 7 NVDEC |
| TDP | 約350W | 350-400W (構成可能) | 最大600W(設定可能) |
| マルチインスタンス GPU | 最大 7 個の MIG(第3世代) | 各 12GB の最大 14 個の MIG | 最大7パーティション(各16.5GB) |
| フォーム ファクター | PCIe Dual Slot | PCIe Dual Slot | PCIe Dual Slot |
| 冷却方法 | Passive | Passive | Passive |
| NVIDIA AI Enterprise | 含む(5年間) | 含む(5年間) | 含む(5年間) |
| 保証 | 3年 | 3年 | 3年 |
このカードを搭載したモデルはこちらから
➡【GSV-IGRAS-4U8G】【GSV-ATRSM-5U8G】
※ジーデップ・アドバンスのサーバー、ワークステーションは最新の高負荷GPUカードが安定して最高のパフォーマンスが発揮できるよう、 NVIDIA社やベアボーンメーカーと連携し、ハードウェア・OS・ミドルウェア・開発ツールまで最適化した形でご提供しています。
- Hopper
- PCIe 5.0
- HBM3e
- 141GB
- [FP64]30 TFLOPS
- [FP32]60 TFLOPS
- FP16/ FP8演算性能
- 標準3年保証






大容量で高速なHBM3eメモリによる高いパフォーマンス
NVIDIA Hopper アーキテクチャをベースとする NVIDIA H200 は、毎秒 4.8 テラバイト (TB/s) で 141 ギガバイト (GB) の HBM3eメモリを提供する初の GPU です。
これは、NVIDIA H100 Tensor コア GPU の約 2 倍の容量で、メモリ帯域幅は 1.4 倍です。H200 の大容量かつ高速なメモリは、生成 AI と LLM を加速し、エネルギー効率を向上させ、総所有コストを低減し、HPC ワークロードに最適化されています。


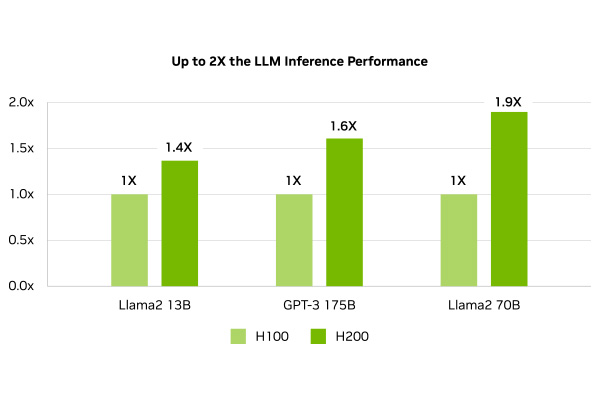
LLM・推論速度がH100と比較して最大 2倍向上
LLMを円滑に稼働させるためには、高性能なコンピュータが必要不可欠です。NVIDIA H200 AIアクセラレータは、この課題を解決する画期的なGPUです。700億パラメータの大規模言語モデル 「Llama2 70B」の推論を前モデルである、NVIDIA H100と比較して1.9倍、1750億パラメータの大規模言語モデル「GPT3-175B」の推論で1.6倍高速化し、LLMの処理速度を最大約2倍に向上させることで、より多くのユーザーに、より迅速かつ高品質なAIサービスを提供することが可能になります。

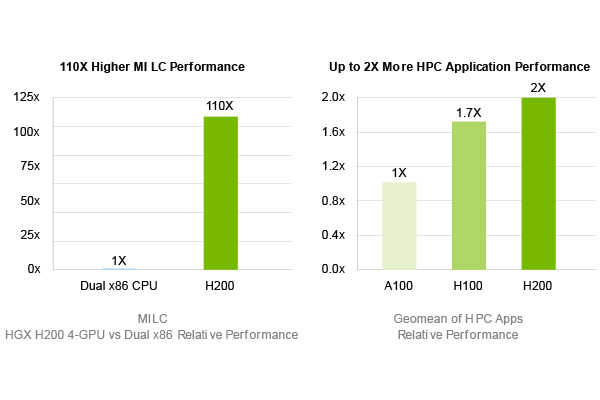
HPCアプリケーションに対してデータ転送110倍に高速化(対CPU)
NVIDIA H200は、膨大なデータを高速に処理する能力に長けたGPUです。GPUはデータの読み書き速度を示す指標としてメモリ帯域幅があり、H200は前モデルのH100 80GBの2.0TB/s、H100 NVL 94GBの3.9TB/s からさらに進化して4.8TB/s のメモリ帯域をもっています。スーパーコンピューターで複雑な計算を行う場合、大量のデータをメモリーとCPUの間で何度もやり取りが行われるのですが、これがボトルネックとなり計算速度が遅くなってしまうことがあります。
NVIDIA H200は、このボトルネックを解消するために、4.8TB/sと非常に高いメモリ帯域幅を実現しています。データをスムーズにやり取りできるため、シミュレーションやAIの学習など、大規模な計算を短時間で処理することが可能です。
また、H200は従来のCPU (Xeon® Platinum 8480+ 2CPU) と比べて、110倍の速さでデータを処理でき、高速なメモリ帯域幅は、科学研究やAI開発など技術革新を加速させる上で不可欠な存在となります。

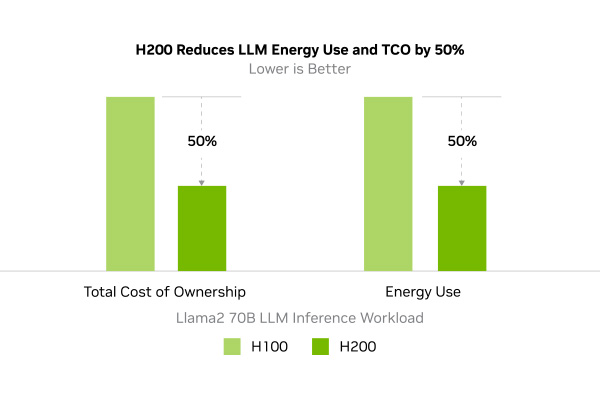
エネルギーとTCOの効率化
NVIDIA H200は、驚異的な性能を発揮しながらも、同時にTCO(総所有コスト)を大幅に削減できる画期的なGPUです。
前世代のH100と同等の電力消費量でありながらはるかに高いパフォーマンスを実現します。AIモデルの学習や、大規模なシミュレーションなど、高度な計算処理を必要とする分野においてこの高いエネルギー効率は、電気料金の削減に直結し、TCOを大幅に抑えることに貢献します。
高いエネルギー効率を実現することで消費電力を削減し環境負荷を軽減します。これは、サステナビリティ社会の実現に向けた重要なファクター言えるでしょう。

NVIDIA AI Enterprise エンタープライズサポートを含む5年のソフトウェアサブスクリプションが付属
NVIDIA H200とNVIDIA AI Enterpriseの組み合わせは、AI 対応プラットフォームの構築が簡素化され、生成AIやコンピュータビジョンなど、多様なAIモデルの開発と導入を加速させ、企業レベルのセキュリティと安定性を確保します。AI開発者は複雑な環境設定に煩わされることなく、AIモデルの開発に集中することができます。
これらの要素が組み合わさることで、企業はAIの導入障壁を下げ、より迅速にビジネスにAIを導入し、競争優位性を確立することができます。
NVIDIA H200には5年間分のNVIDIA AI Enterprise ソフトウェアとサポートが含まれています。


2. With sparsity.






- NVIDIA
- RTX PRO™ 6000 Server
- RTX PRO™ 6000 Max-Q
- RTX PRO™ 6000
- NVIDIA RTX PRO 5000 72GB
- NVIDIA RTX PRO™ 5000
- NVIDIA RTX PRO™ 4500
- NVIDIA RTX PRO™ 4000
- NVIDIA RTX PRO™ 4000 SFF
- NVIDIA® A800 40GB Active
- NVIDIA® L40S
- H200 NVL 141GB PCIe
- XILINX


-
ご購入に関するご相談・お問い合わせ
-
uniVは完全オーダーメイドで
お客様のご希望の仕様に合わせて
製造することが可能です。
お気軽にお問い合わせください。
-


