











Pascal TITAN X ベンチマークと水冷GPUモデルのご案内
Pascal世代のGPU NVIDIA TITAN X がついに日本に上陸しました。
これまでPascal世代でのDeepLearning入門カードとしてはGefroceGTX1080でのご利用が多かったのですが。実際TITAN Xとどのくらいの性能差があるのかベンチマークしてみました。
■ハードウェアスペック
| モデル | メモリ | 単精度浮動小数点演算性能 | メモリーバンド幅 |
| TITAN X (Pascal) | 12GB | 約11TFLOPS | 480GB/s |
| Geforce GTX1080 | 8GB | 約8.9TFLOPS |
320GB/s |
| Geforce GTX TITAN X | 12GB | 約6.6TFLOPS | 336.5GB/s |
GTX1080と比較するとメモリ容量は1.5倍、floatの計算速度の指標である単精度浮動小数点演算性能は1.25倍となっています。またメモリバンド幅も1.5倍と高速化されており、Pascal世代の一つ前のTAITAN Xと比較しても大幅に機能強化されたことがわかります。
■ベンチマーク
まずはGoogleNetでのベンチマークを取得してみました。
DeepLearningの処理時間は1epochの実行時間がわかれば基本的に掛け算で見積もれるため、ImageNetを1epoch実行してみました。1batch動かせば良いという話もありますが、念のため1epochです。
合わせて今回のメモリ容量増強に伴い、どのくらいのBatchSize数を動かせるかも試してみました。
評価条件
・DataSet:ImageNet2012 画像サイズは224x224x3(RGB)
・Middleware:Caffe
・epoch数:1
結果(実行時間)
| GoogleNet Bentch Size | 32 | 64 | 80 | 96 |
| TITAN X (Pascal) | 56min | 50min | 49min | 49min |
| GTX 1080 | 72min | 66min | 計測不能 | 計測不能 |

GTX1080ではBatch Size64までしかメモリに乗りませんでしたが、TITAN XはSize96まで乗りました。メモリ容量が1.5倍になっているのが如実に効いています。速度も1.4倍前後になっていることが判ります。
一方、BatchSizeの違いはそれほど実行時間に影響しないことがお判り頂けます。
次にResNetを使って評価を行ってみました。
ResNetは2015年のILSVRCでトップを獲った手法で、ImageNetのデータセットでは初登場は152層、最新の研究では200層という不快ネットワーク構成が可能です。CIDAR10というデータセットでは実に1001層での学習にも成功しています。
元論文によると、200層のRasnNetは8枚のGPUを使って3週間掛けて学習をさせたそうです。TITAN X1枚ではどのくらいになるのでしょうか・・・
また、こちらはどのくらいのBatchSizeが可能かという観点で実験してみました。
評価条件
・DataSet:ImageNet2012 画像サイズは224x224x3(RGB)
・Network:ResNet 152層及び200層
・Middleware:Caffe
結果(バッチ数)
搭載できたバッチ数で評価しています。トレーニング時のバッチ数とテスト時のバッチ数(括弧内)となっています。
| モデル | 152層 | 200層 |
| TITAN X (Pascal) | 16(8)batch | 10(4)batch |
| GTX1080 | 8(8)batch | 4(4)batch |
さすがにどちらでもResNet200もメモリに乗りますが、対応可能なBatchSizeが異なります。TITAN Xはtrainに10バッチ載せることができました。
結果(実行時間)
| モデル | 100iterrationあたりの処理時間[sec] | 1epochでの予想時間[min] |
| TITAN X (Pascal) | 32 ※BatchSize 10 | 533 |
| GTX1080 | 26 ※BatchSize 4 | 1083 |
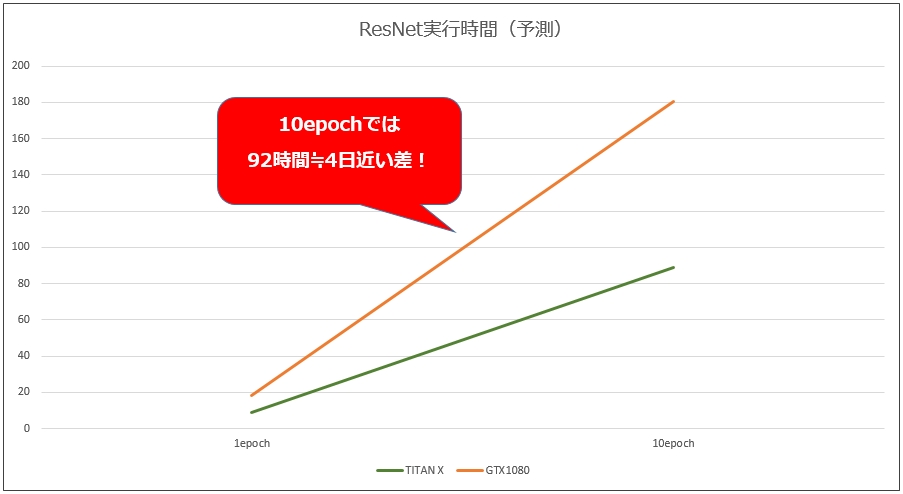
表中の「1epochでの予想時間」ですが、100万枚の処理で1epochとして算出しています。机上の計算ですが、倍以上の性能差が得られました。実際に学習させる際には数十epoch実行するため、時間でいうと日・週の単位で効いてきます。
■ 考察
まず、GPUメモリサイズの違いによって、GTX1080ではバッチサイズの 大きなものは測定不可能となります。やはりDeepLearningにおいてメモリサイズは演算可否だけでなく、学習スピードにも大きく効いてきます。
ベンチマークの通りTITAN Xは GTX1080に比べ、25%ほど処理時間が短縮されています。コア数のスペック差から見ても妥当な数字と思われます。
また、UNIVでは下記のサーマルスロットルリングの対策として水冷TITAN X 搭載モデルの販売を開始しました。尚、TITAN X や Gefroce はコンシュマー市場向けの開発思想のGPUボードであり、保証期間も1年となります。本格運用の際には耐久性、信頼性の面からTESLAの採用を強くお勧めします。
※技術協力 GDEPアドバンスソリューションパートナー
株式会社システム計画研究所 久野 祐輔氏
水冷TITAN X搭載モデルのご提案
TITAN Xは上記の通り現時点でDeepLearning試験研究用途や入門用のGPUカードとしては高い性能を有していますが、弱点としては発熱が高いことが挙げられます。
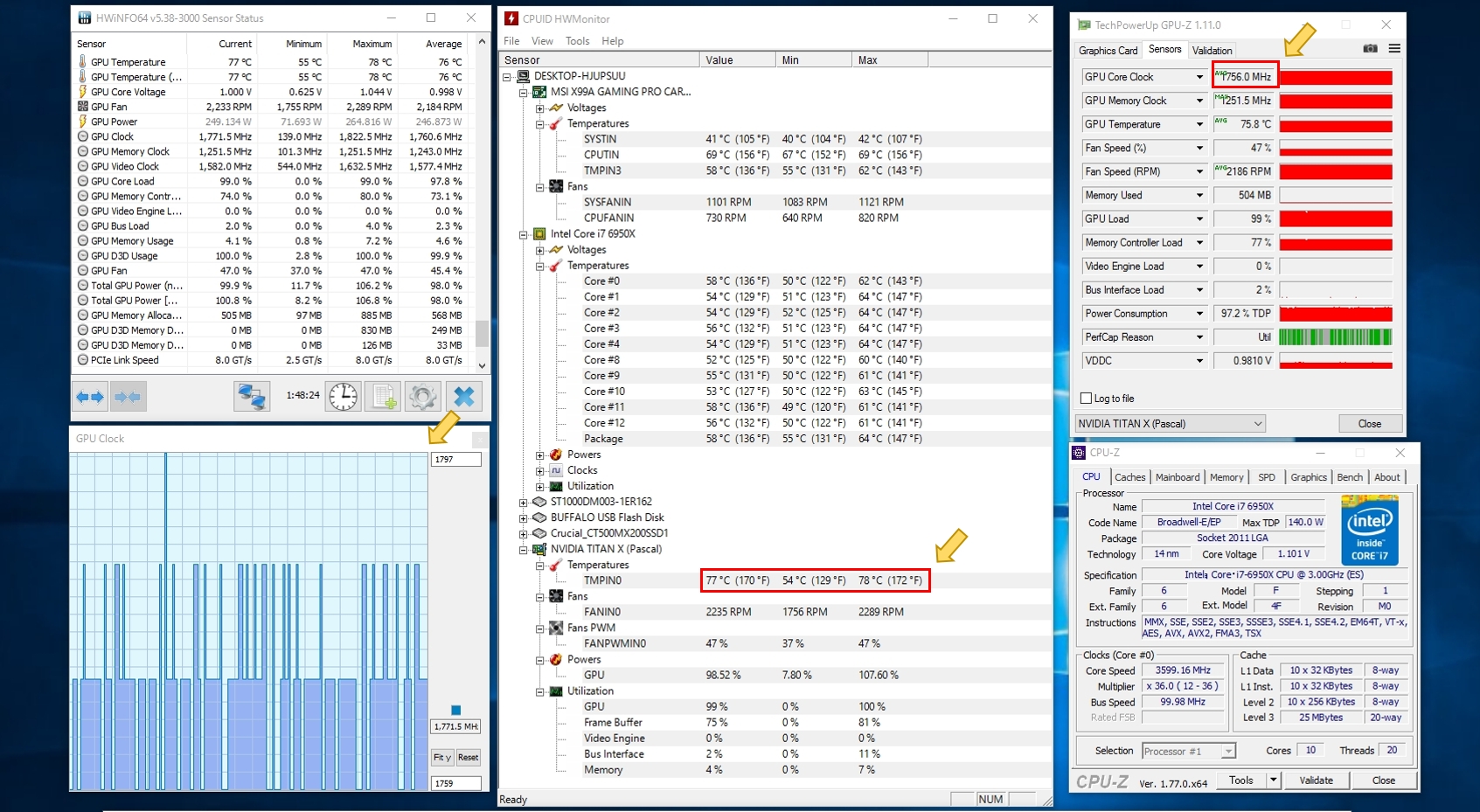
今回のベンチでもGPU負荷を掛け始めてから約1分ほどでGPUコア温度は85℃に達し、サーマルスロットルリングによる急激なクロックの低下が確認されました。

そこでUNIVではオリジナルの水冷ユニットでGPUの水冷化をご提案します。
.jpg) UNIVオリジナルのGPU水冷ユニットは自然循環型のラジエータータイプを採用。ラジエータ液を120mmの大型ファンで冷却し、GPUコアに設置された銅版ヒートシンクをダイレクトに冷却します。
UNIVオリジナルのGPU水冷ユニットは自然循環型のラジエータータイプを採用。ラジエータ液を120mmの大型ファンで冷却し、GPUコアに設置された銅版ヒートシンクをダイレクトに冷却します。
チューブやガスケットは液漏れを徹底して防止するミッションクリティカル仕様の高品質タイプです。
GPU水冷化前と比較すると、ベースクロック1417MHz ブーストクロック1531MHzに対して、
空冷時1462.2MHz → 水冷時1756.0MHzと約20%(300MHz)も高いクロックを維持しつつ、コア温度は5℃前後も低温での動作を実現しました。
ファンの回転数も抑えられ低騒音化も同時に実現可能です。

Pascal TITAN XでDeepLearningをするならUNIVのDeepLearningBOX
※TITAN X搭載モデルは、これからDeepLaerningを始める方を主な対象とした開発キットでありワークステーションタイプとなっておりますのでデスクサイドで作業できます。
しかしながら、開発後の本番稼働には24時間連続使用可能な耐久性信頼のある NVIDIA社製Tesla P100/P40/P4等を動作確認済サーバにてお使いください。
投稿日 : 2016-10-24 10:00:00








-
ご購入に関するご相談・お問い合わせ
-
uniVは完全オーダーメイドで
お客様のご希望の仕様に合わせて
製造することが可能です。
お気軽にお問い合わせください。
-


