

















GSV-IEMSM-4U4Gは、ジーデップ・アドバンスが国内代理店の Super Micro Compute社製べアシステムをベースに構成されたGPUサーバーです。本システムは、第4世代インテルXeonスケーラブル プロセッサー(Sapphire Rapids)を採用、Intel 7ノード(旧10nm)で製造され、プロセッサあたり最大60個のGolden Coveコアと新しい専用アクセラレータコアを搭載、新しいアクセラレータを使用したターゲットワークロードにおいて、前世代に比べて平均1.53倍の性能向上と、ワットあたりの平均性能2.9倍の効率改善を実現とプロセッサの新機能により、PCIe 5.0、DDR5メモリ、CXL 1.1をサポート、またメインメモリはDDR5-4800規格で8チャネル構成、最大メインメモリ容量4TBなど、大幅な機能の向上に加えて、ネットワークは高速な10Gbpsイーサーネットを標準搭載と管理用IPMIも装備し、リモートメンテナンスにも対応しています。また、 最大8ベイのエンクロージャーはNVMe U.2に対応しており、大容量で高速なストレージ環境も柔軟に構築可能です。
GPUは、NVIDIA® Hopperアーキテクチャベースで80GB HBM2eの大容量メモリを搭載が可能、第4世代の Tensor コアと、FP8 精度で混合エキスパート (MoE) モデルのトレーニングを前世代比最大9倍高速化するTransformer Engine を備えております。また、NVIDIA RTX シリーズ(RTX A6000/RTX A5000) を搭載したモデルも用意しておりジェネレーティブAI による大規模言語モデル、画像生成、医療分野の生成系AIなどAI開発、HPC研究に最適なモデルです。
また、本システムには Linux(Ubuntu)オペレーティングシステムと、当社独自のAI開発 ライブラリー群 「G-Works」、そしてOpenAI社も利用しているMLopsプラットフォームである「WandB」がプレインストールされており、AI開発ユーザーが届いたその日からすぐに利用できるターンキーでの提供となります。まさに大学、研究機関、企業のR&D部門などのAI開発者に最適なAI開発システムとなります。
GPUは、NVIDIA® Hopperアーキテクチャベースで80GB HBM2eの大容量メモリを搭載が可能、第4世代の Tensor コアと、FP8 精度で混合エキスパート (MoE) モデルのトレーニングを前世代比最大9倍高速化するTransformer Engine を備えております。また、NVIDIA RTX シリーズ(RTX A6000/RTX A5000) を搭載したモデルも用意しておりジェネレーティブAI による大規模言語モデル、画像生成、医療分野の生成系AIなどAI開発、HPC研究に最適なモデルです。
また、本システムには Linux(Ubuntu)オペレーティングシステムと、当社独自のAI開発 ライブラリー群 「G-Works」、そしてOpenAI社も利用しているMLopsプラットフォームである「WandB」がプレインストールされており、AI開発ユーザーが届いたその日からすぐに利用できるターンキーでの提供となります。まさに大学、研究機関、企業のR&D部門などのAI開発者に最適なAI開発システムとなります。
- 4GPU
- 120Core
- NVMe
- Dual 10G
- u.2
- DDR5
- 4800MHz
- ECC
- Registered
- 2200W
- Rackmount
- IPMI
- 200V入力対応
- 標準3年保証






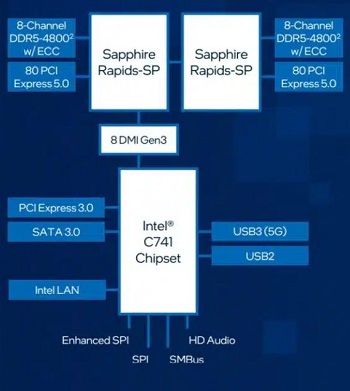
第4世代インテルXeonスケーラブル プロセッサー(Sapphire Rapids)搭載
第4世代インテルXeonスケーラブル プロセッサー(Sapphire Rapids)を採用、Intel 7ノード(旧10nm)で製造され、プロセッサあたり最大60個のGolden Coveコアと新しい専用アクセラレータコアを搭載、新しいアクセラレータを使用したターゲットワークロードにおいて、前世代に比べて平均1.53倍の性能向上と、ワットあたりの平均性能2.9倍の効率改善を実現します。

最も多機能かつセキュアなインテル® Xeon® プラットフォーム
インテル® Xeon® プラットフォームの新機能により、PCIe 5.0、DDR5メモリ、CXL 1.1をサポート、またメインメモリはDDR5-4800規格で8チャネル構成、最大メインメモリ容量4TBなど、大幅な機能の向上に加えて、ネットワークは高速な10Gbpsイーサーネットを標準搭載と管理用IPMIも装備し、リモートメンテナンスにも対応しています。また、 最大8ベイのエンクロージャーはNVMe U.2に対応しており、大容量で高速なストレージ環境も柔軟に構築可能で、これまでにな多機能でセキュアなプラットフォームです。
NVIDIA Hopper アーキテクチャ搭載 H100搭載
GPUは、NVIDIA® Hopperアーキテクチャベースで80GB HBM2eの大容量メモリを搭載が可能、NVIDIA H100 Tensor Core GPU は、TMSCの4nm プロセスルールを採用し814平方mmのダイサイズに、従来のA100の約1.5倍にあたる800億個のトランジスタを搭載したまさに史上最大にして最速のGPUであり、倍精度・単精度をはじめ多様な精度を兼ね備え、マルチインスタンスGPU(MIG)機能により1つのGPUで最大7つのジョブを同時に実行可能。世界で最も困難な計算に AI、データ分析、 HPC分野で驚異的な性能を発揮します。また、第 4 世代の Tensor コアと、FP8 精度で混合エキスパート (MoE) モデルのトレーニングを前世代比最大 9 倍高速化するTransformer Engine を備えております。また、NVIDIA RTX シリーズ(RTX A6000/RTX A5000) を搭載したモデルも用意しておりジェネレーティブAI による大規模言語モデル、画像生成、医療分野の生成系AIなどAI開発、HPC研究に最適なモデルです。

AI開発環境 G-Works 標準搭載
本システムには Linux(Ubuntu)オペレーティングシステムと、当社独自のAI開発 ライブラリー群 「G-Works」、そしてOpenAI社も利用しているMLopsプラットフォームである「WandB」がプレインストールされており、AI開発ユーザーが届いたその日からすぐに利用できるターンキーでの提供となります。まさに大学、研究機関、企業のR&D部門などのAI開発者に最適なAI開発システムとなります。

製品名・スペックから検索










-
ご購入に関するご相談・お問い合わせ
-
uniVは完全オーダーメイドで
お客様のご希望の仕様に合わせて
製造することが可能です。
お気軽にお問い合わせください。
-


